This week, PearX S19 alum, Polimorphic, announced their $5.6m seed round led by M13 with participation from Pear and Shine Capital. We’re really excited about this milestone for Polimorphic because we’ve been able to witness their incredible growth from an idea that came about in their dorm room at MIT to becoming a leading infrastructure player for state, local, and federal government agencies. They’ve demonstrated some amazing traction: 30 governments actively using their platform and they continue to add 15 new customers every month.
To mark the occasion, we wanted to look back over the last 4+ years of working with the Polimorphic team and some of the major milestones along the way.
How we met the team
We first met Polimorphic’s co-founders, Parth and Daniel, at MIT when they applied for Pear Competition. We invited them to join our upcoming PearX batch in the Summer of 2019.
Polimorphic CEO & Co-founder Parth presenting at S19 Demo Day at Filoli Gardens
At the time, the founders were working on a product to make sense of government data. The first version was a tool to collect information from federal, state, and local agencies like press releases, legislation and more, making it easy to digest and consume for politicians and constituents alike but especially for younger consumers.
How they evolved
Polimorphic has evolved quite a bit since 2019. After PearX, the team raised some additional capital and went on a country wide road trip to meet face-to-face with federal, state, and local agencies to learn about their needs. In January 2020, they set off on their trip and visited Iowa, New Hampshire, Washington DC, North Carolina, and Michigan. The pandemic hit during this road trip, and they were even stranded in Michigan for a while!
Through many months of customer discovery, they learned that their data transparency product was not, in fact, the biggest pain point for governments. Instead, they learned that federal, state, and local government agencies dealt with a tremendous amount of manual work with the number of tasks they deal with – from applications to internal approval workflows to payments processing.
Polimorphic team at S19 Demo Day
Why we invested
While the product has evolved since 2019, we knew there was a big opportunity here for this team to tackle. We were very optimistic about their unique ability to build in this space and we’re really excited that they uncovered this big opportunity. Some of the reasons we were, and still are, excited about this team include:
Market opportunity: We all interact with local, state, and federal governments for many daily tasks. We see a multi billion dollar opportunity in providing software to help federal, state, and local governments manage their day-to-day work. Governments still use a lot of pen and paper in their processes which is why many people view governments as slow moving. But interacting with our government does not need to be a slog.
Product vision: The team saw this big untapped opportunity to digitize and add automation to our interactions with governments. Polimorphic helps digitize applications, payments, internal approval flows and use AI to help automate the busy work for government employees.
Founding team: We found Parth and Daniel so compelling. They were two undergraduate engineers thinking deeply about the problems our governments face. Parth’s grandfather worked in local government and he saw first hand the work that went into getting constituents their basic government services. This problem felt really personal to them. They were on a mission to solve these problems and had the grit and tenacity to focus on an otherwise unsexy space. We knew if they could land some customers, the product would be sticky and this has proven to be true.
What’s to come
Over the last four years, we’ve partnered closely with their team as they’ve refined their product roadmap. We helped them identify the biggest hurdles that governments face and encouraged them to really talk to their customers to understand those pain points inside and out.
We also helped the Polimorphic team fine tune their pitch and raise additional capital. When looking to raise more funding, Parth presented again at our PearX W23 demo day and quickly found a lead investor for this round.
At PearX S23 Demo Day in October 2023
This team has made huge strides since we met them. It’s really inspiring to look back over the last few years to see how they’ve grown in a relatively short amount of time. They went from being stuck in Michigan during the pandemic with no customers to having 30 cities and counties (and growing!) using their software. They’re rapidly growing and are adding a new city to their platform every 2 days. They recently launched a GovGPT, the first gen AI tool that governments have made public to their constituents in the entire country. We’re excited for their future!
Automation opportunities from vertical software’s data gold mine mean it has never been a better time to create purpose-built operational tools for overlooked industries. Plus, our market map of AI-enabled vertical software new entrants.
Vertical software founders build applications across many industries but with a common mission: to empower expert operators and owners to streamline and grow their businesses with software purpose-built for their own industry.
Over the past decade, Pear has supported founders building powerful applications for industries ranging from supply chain (Expedock, Beyond Trucks), construction (Gryps, Miter, Doxel), energy (Aurora, Pearl Street) and insurance (Federato) to home services (Conduit), travel (JetInsight, Skipper), agriculture (FarmRaise, Lasso), real estate (Hazel) and live events (Chainpass) – and more. These companies and plenty of others we admire outside of our portfolio have created hundreds of billions of dollars in enterprise value for themselves and for their customers.
Today, with artificial intelligence capabilities easier than ever to deploy in B2B products, we think it has never been a better time to build vertical software that automates core aspects of customer operations.
Any new vertical software opportunity — any sector that is not well-served by purpose-built software for industry-specific workflows — now looks even more promising. And, many existing vertical software tools have a rare opportunity to ramp up ACVs, increase stickiness, and build a powerful moat.
To understand why we might be on the verge of a golden age of intelligently-automated vertical software, we’ll take a look at two problems: First, the ACV problem that has limited vertical software opportunities. Then, the defensibility problem afflicting new AI application entrants.
The ACV Problem
Vertical software companies often sell into fragmented industries with many small-to-medium businesses. These businesses operate on thin margins and have limited ability to pay for new operational software. Contract values – and therefore market size – for many verticals have historically been constrained, which means that many sectors remain underserved by purpose-built, cloud-based software.
Historically, vertical software companies have sought to increase the value of their customer relationships by adding bolt-on monetization features like payments or banking. Other vertical software companies have initially sold to the fragmented base of a sector and steadily added operational features to move upmarket to larger customers within their industry.
In either case, the fundamental margin structure of the end customer remains unchanged, and few vertical software companies can reliably claim to impact their customers’ profitability in a major way. A vertical software customer might love their software’s intuitive UI, centralized system of record, navigable scheduling tools, and modern payment processing system. But these benefits rarely reduce the customer’s overall operating cost in a significant way.
The Defensibility Problem
Despite the excitement over applications of large language models in late 2022 and early 2023, many initial products were dismissed as “thin wrappers” over an off-the-shelf model. Critics argued that these initial applications lacked product differentiation and long-term defensibility.
At Pear, we believe that proprietary data is one of the keys to a defensible AI application. Proprietary data behind B2B AI applications comes in three forms:
Many early tools built over groundbreaking LLMs offered no form of proprietary data. At best, some products built over lightly-adapted models offered bronze or silver-level data-based defensibility. But we’ve been on the hunt for game-changing applications that build an advantage in proprietary model-training data from the start.
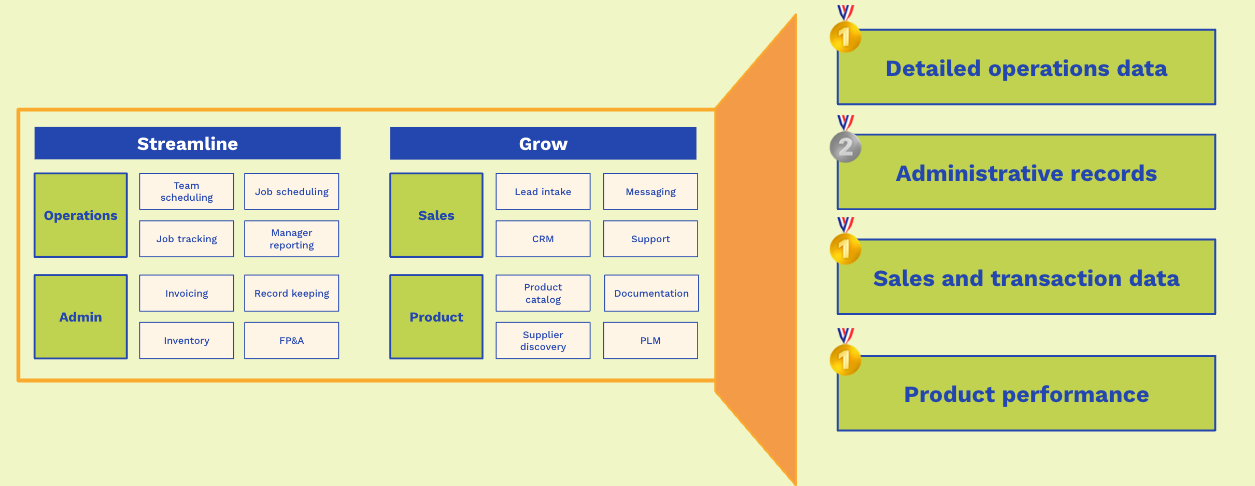
The Vertical Software Data Gold Mine
Traditional vertical software products generate enormous amounts of gold-level data, capture substantial silver-level information, and often themselves aggregate bronze-level data within their products.
Customer business logic flows through vertical software features. From operational decisions and administrative record-keeping to sales and product performance, customers of vertical software deposit reams of data daily into a rich system of record.
The most impactful B2B applications in the next decade will rigorously structure, mine, and harness gold-level product-generated data to enable workflow automation for their end customers.
Any business process with decisions and steps encoded in a vertical software feature set will be a candidate for automation. We’re most excited about automation that enables faster information processing tied to sales growth or cost-saving opportunities for an end customer: instant diagnosis and repair commissioning for field technicians, predictive inventory capabilities embedded in B2B marketplaces, copilot-style knowledge bases that help small business owners understand the impact of every decision on their bottom line.
Automation across many business functions will mean that vertical software companies can finally impact their customers’ margin structure – and as a result, help these customers break any linear scaling trap they face when they otherwise expand their business.
Early entrants: A preliminary market map
We have seen a proliferation of promising AI-enabled vertical software products in a handful of sectors, and we are proud to be the earliest supporters of teams like Expedock, Pearl Street, Gryps, Hazel, and Federato.
Many initial intelligently automated vertical software products target the largest sectors of the economy (we’ve looked separately at the ecosystem of AI in healthcare companies here). We’ll update this market map over time, and we’re eager to include companies unlocking automation potential in industries that have seen fewer capable purpose-built tools in the past.
What we are looking for
We hope to support many more founders delivering on a new and bigger promise of vertical software. Standout teams that we currently support – or just simply admire – typically excel on a few dimensions:
They have an unfair data advantage.
They have identified substantial automation potential.
They can communicate their value without invoking AI.
We want to hear from you
If you share our conviction that we’re entering a new golden age of vertical software and you’re exploring startup ideas that help expert operators streamline and grow their businesses through intelligent automation, we would love to hear from you. Reach out at keith@pear.vc if you’re working on something impactful.
On August 3rd, PearX S20 alum Sequel, received FDA approval. Sequel’s co-founders, Greta Meyer and Amanda Calabrese, worked hard to develop their product and work through the FDA clearance process. This can be a grueling process, so it’s truly a huge milestone for Sequel to be able to launch their FDA-approved tampons. We wanted to mark the occasion by looking back on our journey working with the Sequel team.
Founders, Greta Meyer and Amanda Calabrese
We met Sequel co-founders, Greta Meyer and Amanda Calabrese, when they were still students at Stanford. They were both undergraduate engineering students, where they participated in the LaunchPad d-school course in 2018 to design and launch a product. They were both professional athletes that had lived first hand, menstruation leaks during practice or worse an athletic tournament. Mar was tasked with helping them refine their fundraising pitch and this is how our partnership with Sequel got started.
Sequel joined our PearX S20 cohort, right at the start of the pandemic, when they were still called Tempo. And even though it was unexpectedly a virtual cohort, it was an outstanding PearX class, with many other breakout companies like: Seven Starling, Interface Bio, Federato, Expedock, Gryps, and rePurpose Global.
PearX check-in during Covid.
After meeting Amanda and Greta, we chose to invest in Sequel for a few key reasons:
Big market opportunity:
Greta and Amanda were both superstar athletes and had a pain point: menstruation products are still not reliable for women. While participating in the Launchpad course, they dug into this more to see if others felt the same way. They learned that most women still prefer a tampon to all of the options out there, but they unveiled a common frustration for women: they had to combine their tampons with pads or pantyliners to avoid leaks. Amanda and Greta realized that, while the tampon had been around for ages, it hadn’t seen any innovation in nearly a century. They saw a big opportunity to build a women’s health company that was focused on innovating this big, unmet need for women.
Their product vision:
We were excited about their mission and vision: to re-engineer the tampon. For their product, the two engineers envisioned a redesign of a tampon in a spiral-shape to fit more comfortably and better absorb periods to prevent leaks. They designed and patented their design, so it’s truly proprietary. We really liked the product innovation and their vision to shake up an old industry that’s dominated by a few huge players like Tampax.
The founders:
Greta and Amanda were stellar founders and superstar athletes too: Amanda competes for the US Lifesaving Association and Greta played Varsity Lacrosse while at Stanford. They had first hand experience with tampons failing them while being active, and we loved that they were both extremely purpose-driven.
Amanda and Greta presenting during Demo Day
During PearX, they built out a pretty robust go-to-market strategy, assembled influencers, and started a beta program. They got a quality system up and running to prepare for FDA testing. They were able to beta test with 75+ users before PearX Demo Day. They presented to thousands of investors at Pear Demo Day and raised a seed round from MaC VC, Long Journey Ventures, and others.
Since participating in PearX, they’ve had a number of exciting wins. Greta and Amanda were included on the Forbes 30 under 30 list for manufacturing and industry. Amanda moderated a SXSW panel on content creators and stigmatized spaces. And they received positive press from Fortune, the Wall Street Journal, Forbes and others.
With FDA approval behind them, we are excited for the Sequel team to be able to focus on commercialization and getting their product out in the world. We know the best is yet to come for this company!
PearX alumni company, Via, just announced that they’ve been acquired by Justworks. To mark this occasion, we wanted to share a look back on how we met and worked with the Via team over the years.
Mar first met sisters and Via co-founders Maite and Itziar when they were students at Stanford’s Graduate School of Business. They were enrolled in the Launchpad d.school course where Mar was a guest lecturer. Through the class, they developed an idea to build a marketplace to connect top professionals to short-term project work at different companies around the world. They built strong conviction through the course and we thought they were the perfect fit for as founders of these companies. We invited them to join PearX, our early-stage bootcamp for founders, and partnered with them from then on to build Via.
We decided to partner with Maite and Itziar for a few major reasons:
We saw a big market opportunity:
The Via co-founders discovered that there was a massive multi-billion dollar need for hyper local employer of record (EOR) and native payroll services for companies in international tech hubs. Through research, they learned that, when companies hire internationally, they typically do so via contractor agreements, but this happens without any truly scalable benefits, compliance, or payroll services. This works for companies that are hiring a small handful of employees in international markets, but it breaks down for companies that are hiring at scale with dozens or even hundreds of employees. Via saw a big opportunity to make that easier for these larger companies.
Strong ability to execute:
After seeing the big market opportunity, the Via team focused on building a product that met that need. They built deep infrastructure in over a dozen large, international markets, allowing Via to provide the right level of service to multinational Fortune 500 customers. Companies no longer had to spend years laying down the foundation to open a new hub, they could partner directly with Via and launch their new offices in a fraction of the time. They were quickly able to attract a number of top professionals to join companies internationally. We realized the cyclicality of this business model, and at the same time, they were hearing from their corporate customers that there was a big challenge in hiring employees internationally. Starting a new hub in a different country was desirable for many reasons, but payroll, insurance, benefits, and compliance all become very complicated, which prevented many companies from starting international hubs.
The founders were the right ones to tackle this:
The sisters and co-founders, Maite and Itziar, were the perfect duo to start and run Via. We loved the team because of their deep understanding of their customer’s pain point and their international focus. They are both GSB alums and brought deep business experience to the table: Maite has a background in investment banking at JP Morgan and Itziar was Head of Strategy for Citi Fintech. They also worked in markets like Argentina and Mexico, so they understood the pain points of hiring internationally.
Via’s work became even more relevant in a post-pandemic world, where there has been a big rise in companies hiring internationally. Put simply, they’ve become the best choice for Fortune 500 customers. This acquisition by Justworks makes sense: together they can offer the Via service at scale.
We are proud of their journey. After raising an initial pre-seed round after PearX, they realized that it would be hard to build a venture scale business focusing only on short term job opportunities. We huddled with them and they decided it would be best to pivot to the employer side and solve their problem which was more around building a permanent workforce internationally. Maite and Itziar navigated this pivot with rigor and optimism.
The team then scaled out their hyper-local EOR platform, scaled to millions of dollars in annual revenue, and raised a Series A in December 2022. To date, they’ve raised from an incredible group of investors, including Industry Ventures, Switch VC, Entree Capital, Burst Capital, Pear and more.
Given the infrastructure that they’ve built, it’s no surprise that they had inbound interest for M&A. We think they’ve found the perfect home in the Justworks team. The acquisition by Justworks provides an ideal platform to scale their joint business internationally allowing any company to become a global organization. Congrats to Maite, Itziar, and the entire Via team!
Founders often ask us what kind of AI company they should start and how to start something long lasting?
Our thesis on AI and ML at Pear is grounded in the belief that advances in these fields are game-changing, paralleling the advent of the web in the late ’90s. We foresee that AI and ML will revolutionize both enterprise software and consumer applications. A particular area of interest is generative AI, which we believe holds the potential to increase productivity across many verticals by five to ten times. Pear has been investing in AI/ML for many years, and in generative AI more recently. That said, there’s still a lot of noise in this space, which is part of the reason we host a “Perspectives in AI” technical fireside series to cut through the hype, and connect the dots between research and product.
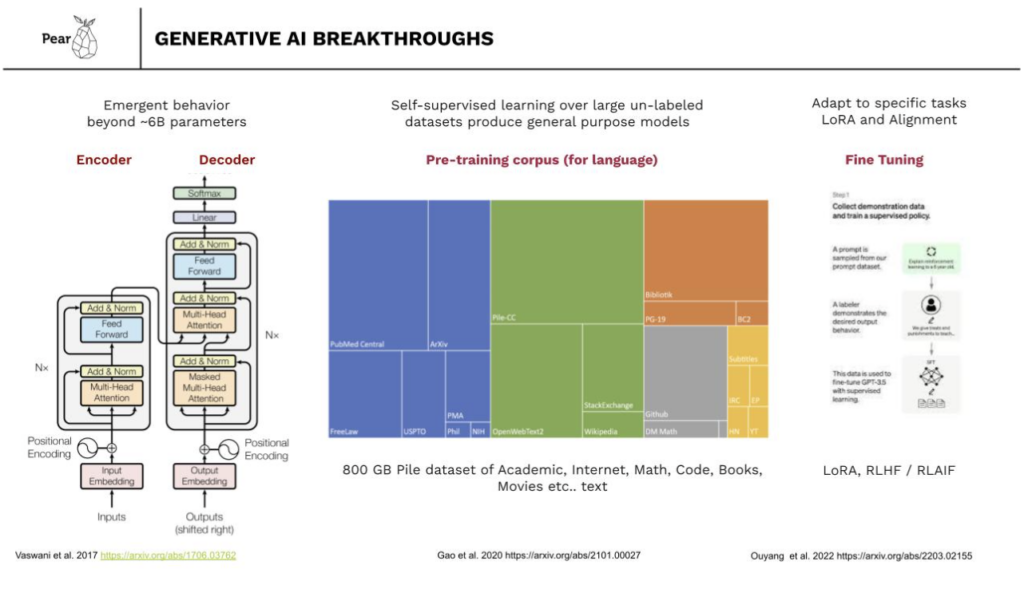
Much of the progress in Generative AI began with the breakthrough invention of the transformer in 2017 by researchers at Google. This innovation combined with the at-scale availability of GPUs in public clouds paved the way for large language models and neural networks to be trained on massive datasets. When these models reach a size of 6 billion parameters or more, they exhibit emergent behavior, performing seemingly intelligent tasks. Coupled with training on mixed domain data such as the pile dataset, these models become general-purpose, capable of various tasks including code generation, summarization, and other text-based functions. These are still statistical models with non zero rates of error or hallucination but they are nevertheless a breakthrough in the emergence of intelligent output.
Another related advancement is the ability to employ these large foundational models and customize them through transfer learning to suit specific tasks. Many different techniques are employed here, but one that is particularly efficient and relevant to commercial applications is fine tuning using Low Rank Adaptation. LoRA enables the creation of multiple smaller fine tuned models that can be optimized for a particular purpose or character, and function in conjunction with the larger model to provide a more effective and efficient output. Finally one of the most important recent innovations that allowed the broad public release of LLMs has been RLHF and RLAIF to create models that are aligned with company-specific values or use-case-specific needs. Collectively these breakthroughs have catalyzed the capabilities we’re observing today, signifying a rapid acceleration in the field.
Text is, of course, the most prevalent domain for AI models, but significant progress has been made in areas like video, image, vision, and even biological systems. This year, in particular, marks substantial advancements in generative AI, including speech and multimodal models. The interplay between open-source models (represented in white in the figure below) and commercial closed models is worth noting. Open-source models are becoming as capable as their closed counterparts, and the cost of training these models is decreasing.
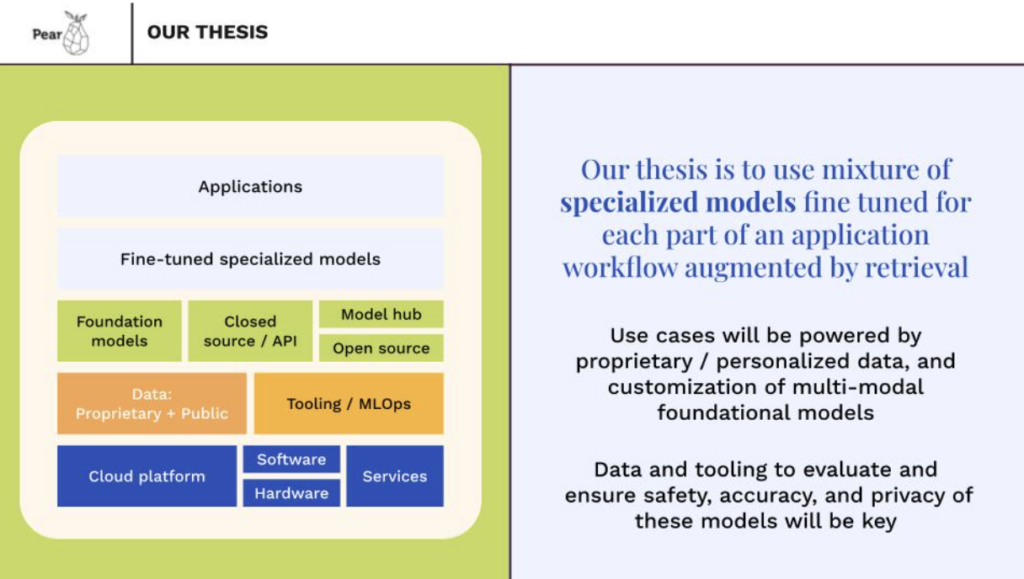
Our thesis on AI breaks down into three parts: 1. applications along with foundation / fine tuned models, 2. data, tooling and orchestration and 3. infrastructure which includes cloud services software and hardware. At the top layer we believe the applications that will win in the generative AI ecosystem will be architected using ensembles of task specific models that are fine tuned using proprietary data (specific to each vertical, use case, and user experience),along with retrieval augmentation. OrbyAI is an early innovation leader in this area of AI driven workflow automation. It is extremely relevant and useful for enterprises.We also believe that tooling for integrating, orchestrating, evaluating/testing, securing and continuously deploying model based applications is a separate investment category. Nightfall understands this problem well and is focused on tooling for data privacy and security of composite AI applications. Finally, we see great opportunity in infrastructure advances at the software, hardware and cloud services layer for efficient training and inference at larger scales across different device form factors. There are many diverse areas within infrastructure from specialized AI chips to high bandwidth networking to novel model architectures. Quadric is a Pear portfolio company working in this space.
Successful entrepreneurs will focus on using a mixture of specialized models fine tuned using proprietary or personal data, to a specific workflow along with retrieval augmentation and prompt engineering techniques to build reliable, intelligent applications that automate previously cumbersome processes. For most enterprise use cases the models will be augmented by a retrieval system to ensure a fact basis as well as explainability of results. We discuss open source models in this context because these are more widely accessible for sophisticated fine tuning, and they can be used in private environments for access to proprietary data. Also they are often available in many sizes enabling applications with more local and edge based form factors. Open source models are becoming progressively more capable with new releases such as Llama2 and the cost of running these models is also going down.
When we talk about moats, we think it’s extremely important that founders have compelling insight regarding the specific problem they are solving and experience with go-to market for their use case. This is important for any start up, but in AI access to proprietary data and skilled human expertise are even more important for building a moat. Per our thesis, fine tuning models for specific use cases using proprietary data and knowledge is key for building a moat. Startups that solve major open problems in AI such as providing scalable mechanisms for data integration, data privacy, improved accuracy, safety, and compliance for composite AI applications can also have an inherent moat.
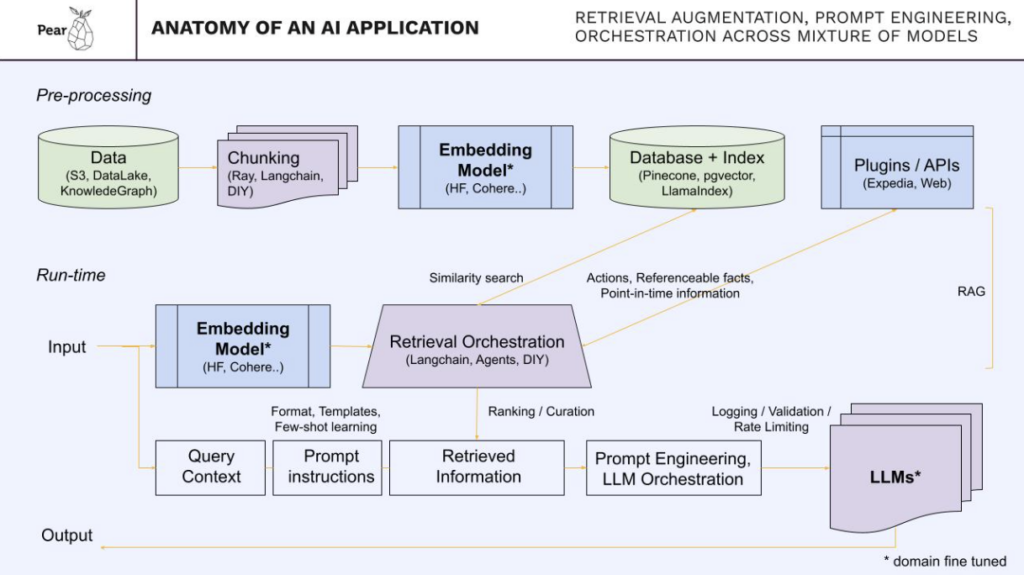
A high level architecture or “Anatomy of a modern AI application” often involves preprocessing data, chunking it and then using an embedding model, putting those embeddings into a database, creating an index or multiple indices and then at runtime, creating embeddings out of the input and then essentially searching against the index with appropriate curation and ranking of results. AI applications pull in other sources of information and data as needed using traditional APIs and databases, for example for real time or point in time information, referenceable facts or to take actions. This is referred to as RAG or retrieval augmented generation. Most applications require prompt engineering for many purposes including formatting the model input/output, adding specific instructions, templates, and providing examples to the LLM. The retrieved information combined with prompt engineering is fed to an LLM or a set of LLMs/ mixture of large language models, and the synthesized output is communicated back to the user. Input and output validation, rate limiting and other privacy and security mechanisms are inserted at the input and output of LLMs. I’ve bolded the Embedding model, and the LLMs, because those benefit from fine tuning.
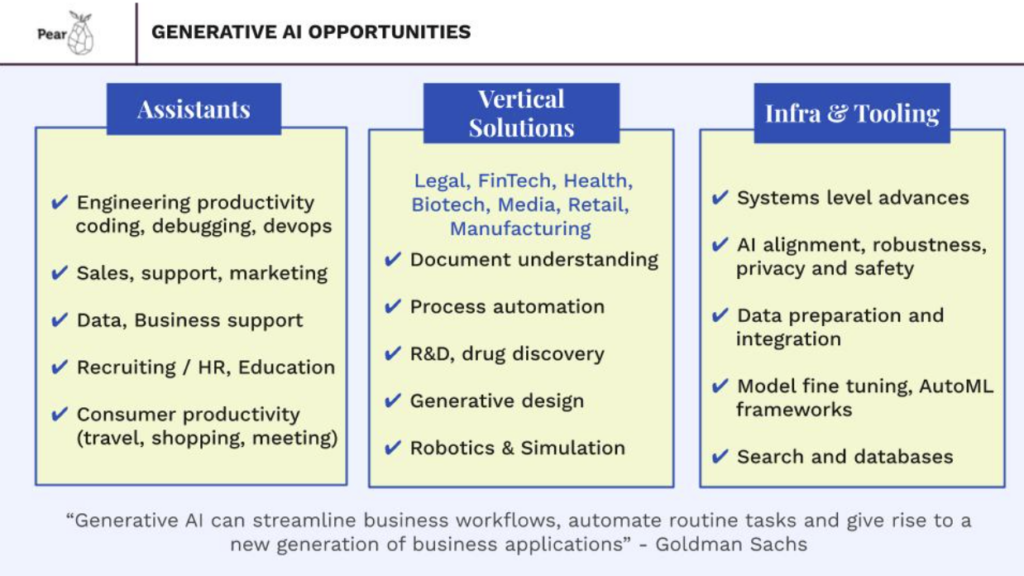
In terms of applications that are ripe for disruption from generative AI, there are many. First of all, the idea of personalized “AI Assistants” for consumers broadly will likely represent the most powerful shift in the way we use computing in the future. Shorter term we expect specific “assistants” for major functional areas. In particular software development and the engineering function overall will likely be the first adopter of AI assistants for everything from code development to application troubleshooting. It may be best to think of this area in terms of the jobs to be done (e.g., SWE, Test/QA, SRE etc), while some of these are using generativeAI today, there is much more potential still. A second closely related opportunity area is data and analytics which is dramatically simplified by generative AI. Additional rich areas for building generative AI applications are all parts of CRM systems for marketing, sales, and support, as well as recruiting, learning/education and HR functions. Sellscale is one of our latest portfolio companies accelerating sales and marketing through generative AI. In all of these areas we think it is important for startups to build deep moats using proprietary data and fine tuning domain specific models.
We also clearly see applications in healthcare, legal, manufacturing, finance, insurance, biotech and pharma verticals all of which have significant workflows that are rich in text, images or numbers that can benefit greatly from artificial intelligence. Federato is a Pear portfolio company that is applying AI to risk optimization for the insurance industry while VizAI uses AI to connect care teams earlier, increase speed of diagnosis and improve clinical care pathways starting with Stroke detection. These verticals are also regulated and have a higher bar for accuracy, privacy and explainability all of which provide great opportunities for differentiation and moats. Separately, media, retail and gaming verticals offer emerging opportunities for generative AI that have more of a consumer / creator goto market. The scale and monetization profile of this type of vertical may be different from highly regulated verticals. We also see applications in Climate, Energy and Robotics longer term.
Last but not least, at Pear we believe some of the biggest winners from generative AI will be at the infrastructure and tooling layers of the stack. Startups solving problems in systems to make inference and training more efficient, pushing the envelope with context lengths, enabling data integration, model alignment, privacy, and safety and building platforms for model evaluation, iteration and deployment should see a rapidly growing market.
We are very excited to partner with the entrepreneurs who are building the future of these workflows. AI, with its recent advances, offers a new capability that is going to force a rethinking of how we work and what parts can be done more intelligently. We can’t wait to see what pain points you will address!
I recently hosted a fireside chat with AI researcher Edward Hu. Our conversation covered various aspects of AI technology, with a focus on two key inventions Edward Hu pioneered: Low Rank Adaptation (LoRA) and μTransfer, which have had wide ranging impact on the efficiency and adoption of Large Language Models. For those who couldn’t attend in person, here is a recap (edited and summarized for length).
Aparna: Welcome, everyone to the next edition of the ‘Perspectives on AI’ fireside chat series at Pear VC. I’m Aparna Sinha, a partner at Pear VC focusing on AI, developer tooling and cloud infrastructure investments. I’m very pleased to welcome Edward Hu today.
Edward is an AI researcher currently at Mila in Montreal, Canada. He is pursuing his PhD under Yoshua Bengio, who is a Turing award winner. Edward has a number of inventions to his name that have impacted the AI technology that you and I use every day. He is the inventor of Low Rank Adaptation (LoRA) as well as μTransfer, and he is working on the next generation of AI reasoning systems.Edward, you’ve had such an amazing impact on the field. Can you tell us a little bit about yourself and how you got started working in this field?
Edward: Hello, everyone. Super happy to be here. Growing up I was really interested in computers and communication. I decided to study both computer science and linguistics in college. I got an opportunity to do research at Johns Hopkins on empirical NLP, building systems that would understand documents, for example. The approach in 2017, was mostly building pipelines. So you have your name entity recognition module, that feeds into maybe a retrieval system, and then the whole thing in the end, gives you a summarization through a separate summarization module. This was before large language models.
I remember the day GPT-2 came out. We had a lab meeting and everybody was talking about how it was the same approach as GPT, but scaled to a larger data set and a larger model. Even though it was less technically interesting, the model was performing much better. I realized there is a limit to the gain we have from engineering traditional NLP pipelines. In just a few years we saw a transition from these pipelines to a big model, trained on general domain data and fine tuned on specific data. So when I was admitted as an AI resident at Microsoft Research, I pivoted to work on deep learning. I was blessed with many mentors while I was there, including Greg Yang, who recently started xAI. We worked on the science and practice of training huge models and that led to LoRA and μTransfer.
More recently, I’m back to discovering the next principles for intelligence. I believe we can gain much capability by organizing computation in our models. Is our model really thinking the way we think? This motivated my current research at Mila on robust reasoning.
Aparna: That’s amazing. So what is low rank adaptation in simple terms and what is it being used for?
Edward: Low Rank Adaptation (often referred to as LoRA) is a method used to adapt large, pre-trained models to specific tasks or domains without significant retraining. The concept is to have a smaller module that contains enough domain-specific information, which can be appended to the larger model. This allows for quick adaptability without altering the large model’s architecture or the need for extensive retraining. It performs as if you have fine tuned a large model on a downstream task.
For instance, in the context of diffusion models, LoRA enables the quick adaptation of a model to particular characters or styles of art. This smaller module can be quickly swapped out, changing the style of art without major adjustments to the diffusion model itself.
Similarly, in language processing, a LoRA module can contain domain-specific information in the range of tens to hundreds of megabytes, but when added to a large language model of tens of gigabytes or even terabytes, it enables the model to work with specialized knowledge. LoRA’s implementation allows for the injection of domain-specific knowledge into a larger model, granting it the ability to understand and process information within a specific field without significant alteration to the core model.
Aparna: Low rank adaptation seems like a compelling solution to the challenges of scalability and domain specificity in artificial intelligence. What is the underlying principle that enables its efficacy, and what led you to develop LoRA?
Edward: We came up with LoRA two years ago, and it has gained attention more recently due to its growing applications. Essentially, LoRA uses the concept of low rank approximation in linear algebra to create a smaller, adaptable module.This module can be integrated into larger models to customize them towards a particular task.
I would like to delve into the genesis of LoRA. During my time at Microsoft,when GPT-3 was released and the OpenAI-Microsoft partnership began, we had the opportunity to work with the 175-billion-parameter model, an unprecedented scale at that time. Running this model on production infrastructure was indeed painful.
Firstly, without fine-tuning, the model wasn’t up to our standards. Fine-tuning, is essential to adapt our models to specific tasks, and it became apparent that few-shot learning didn’t provide the desired performance for a product. Although once fine-tuned, the performance was amazing, the process itself was extremely expensive.
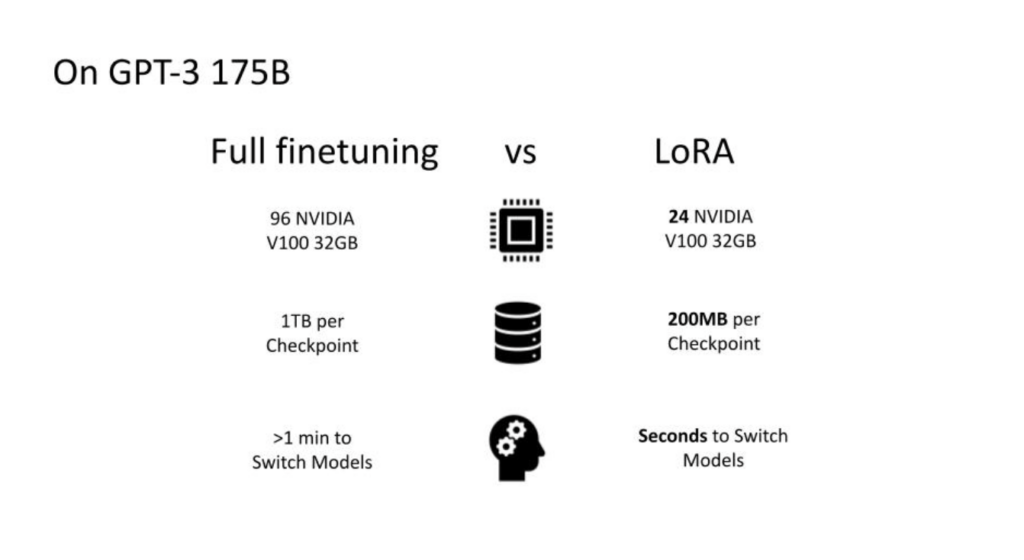
To elucidate, it required at least 96 Nvidia V100s, which was cutting-edge technology at the time and very hard to come by, to start the training process with a small batch size, which was far from optimal. Furthermore, every checkpoint saved was a terabyte in size, which meant that the storage cost was non-negligible, even compared to the GPUs’ cost. The challenges did not end there. Deploying the model into a product presented additional hurdles. If you wanted to customize per user, you had to switch models, a process that took about a minute with such large checkpoints. The process was super network-intensive, super I/O-intensive, and simply too slow to be practical.
Under this pressure, we sought ways to make the model suitable for our production environment. We experimented with many existing approaches from academia, such as adapters and prefix tuning. However, they all had shortcomings. With adapters, the added extra layers led to significant latency, a nontrivial concern given the scale of 175 billion parameters. For prefix tuning and other methods, the issue was performance, as they were not on par with full fine-tuning. This led us to think creatively about other solutions, and ultimately to the development of LoRA.
Aparna: That sounds like a big scaling problem, one that must have prevented LLMs from becoming real products for millions of users.
Edward: Yes, I’ll proceed to elaborate on how we solved these challenges, and I will discuss some of the core functionalities and innovations behind LoRA.
Our exploration with LoRA led to impressive efficiencies. We successfully devised a setup that could handle a 175 billion parameter model. By fine-tuning and adapting it, we managed to cut the resource usage down to just 24 V100s. This was a significant milestone for our team, given the size of the model. This newfound efficiency enabled us to work with multiple models concurrently, test numerous hyperparameter combinations, and conduct extensive model trimming.
What further enhanced our production capabilities was the reduction in checkpoint sizes, from 1 TB to just 200 megabytes. This size reduction opened the door to innovative engineering approaches such as caching in VRAM or RAM and swapping them on demand, something that would have been impossible with 1 TB checkpoints. The ability to switch models swiftly improved user experience considerably.
LoRA’s primary benefits in a production environment lie in the zero inference latency, acceleration of training, and lowering the barrier to entry by decreasing the number of GPUs required. The base model remains the same, but the adaptive part is faster and smaller, making it quicker to switch. Another crucial advantage is the reduction in storage costs, which we estimated to be a reduction by a factor of 1000 to 5000, a significant saving for our team.
Aparna: That’s a substantial achievement, Edward, paving the way for many new use cases.
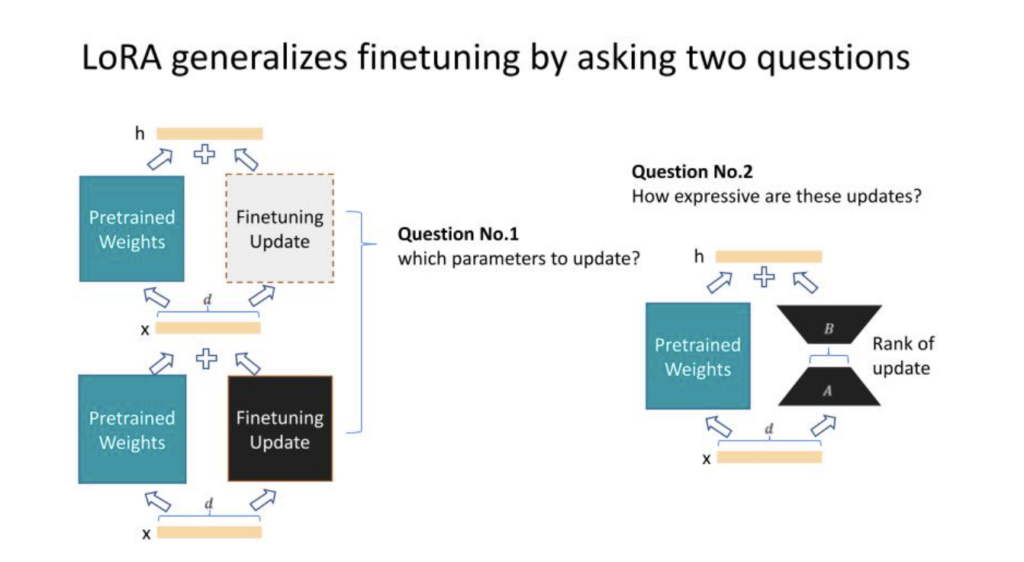
Edward: Indeed. Now, let’s delve into how LoRA works, particularly for those new to the concept. LoRA starts with fine-tuning and generalizes in two directions. The first direction concerns which parameters of the neural network – made up of numerous layers of weights and biases – we should adapt. This could involve updating every other layer, every third layer, or specific types of layers such as the attention layers or the MLP layers for a transformer.
The second direction involves the expressiveness of these adaptations or updates. Using linear algebra, we know that matrices, which most of the weights are, have something called rank. The lower the rank, the less expressive it is, providing a sort of tuning knob for these updates’ expressiveness. Of course, there’s a trade-off here – the more expressive the update, the more expensive it is, and vice versa.
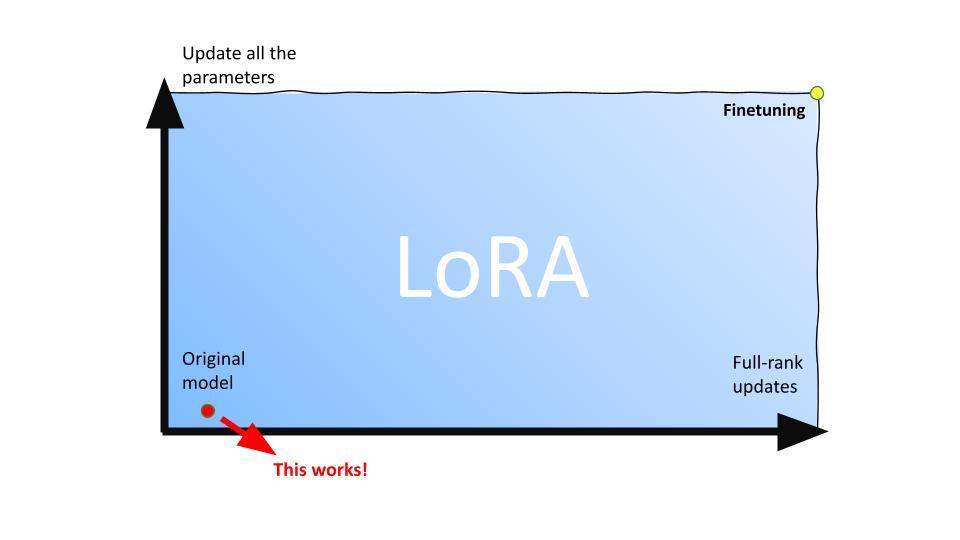
Considering these two directions, we essentially have a 2D plane to help navigate our model adaptations. The y-axis represents the parameters we’re updating – from all parameters to none, which would retain the original model. The parameters of our model exist on a plane where the x-axis signifies whether we perform full rank updates or low rank updates. A zero rank update would equate to no updating at all. The original model can be seen as the origin, and fine tuning as the upper right corner, indicating that we update all parameters, and these updates are full rank.
The introduction of LoRA allows for a model to move freely across this plane. Although it doesn’t make sense to move outside this box, any location inside represents a LoRA configuration. A surprising finding from our research showed that a point close to the origin, where only a small subset of parameters are updated using very low rank, can perform almost as well as full fine tuning in large models like GPT-3. This has significantly reduced costs while maintaining performance.
Aparna: This breakthrough is not only significant for the field as a whole, but particularly for OpenAI and Microsoft. It has greatly expanded the effectiveness and efficiency of large language models.
Edward: Absolutely, it is a significant leap for the field. However, it’s also built on a wealth of preceding research. Concepts like Adapters, Prefix Tuning, and the like have been proposed years before LoRA. Each new development stands on the shoulders of prior ones. We’ve built on these works, and in turn, future researchers will build upon LoRA. We will certainly have better methods in the future.
Aparna: From my understanding, LoRA is already widely used. While initially conceived for text-based models, it’s been applied to diffusion models, among other things.
Edward: Indeed, the beauty of this approach is its general applicability. Whether deciding which layers to adapt or how expressive the updates should be, these considerations apply to virtually any model that incorporates multiple layers and matrices, which is characteristic of modern deep learning. By asking these two questions, you can identify the ideal location within this ‘box’ for your model. While a worst case scenario would have you close to the upper right, thereby not saving as much, many models have proven to perform well even when situated close to the lower left corner. LoRA is also supported in HuggingFace nowadays, so it’s relatively easy to use.
Aparna: Do you foresee any potential challenges or limitations in its implementation? Are there any other domains or innovative applications where you envision LoRA making a significant impact in the near future?
Edward: While LoRA presents exciting opportunities, it also comes with certain challenges. Implementing low rank adaptation requires precision in crafting the smaller module, ensuring it aligns with the larger model’s structure and objectives. An imprecise implementation could lead to inefficiencies or suboptimal performance. Furthermore, adapting to rapidly changing domains or highly specialized fields may pose additional complexities.
As for innovative applications, I envision LoRA being utilized in areas beyond visual arts and language. It could be applied in personalized healthcare, where specific patient data can be integrated into broader medical models. Additionally, it might find applications in real-time adaptation for robotics or enhancing virtual reality experiences through customizable modules.
In conclusion, while LoRA promises significant advancements in the field of AI, it also invites careful consideration of its limitations and potentials. Its success will depend on continued research, collaboration, and innovative thinking.
Aparna: For many of our founders, the ability to efficiently fine tune models and customize them according to their company’s unique personality or data is fundamental to constructing a moat. What your work has done is optimize this process through tools like Lora and μTransfer. Would you tell us now about μTransfer, the project you embarked upon post your collaboration with Greg Yang on the theory of infinity with neural networks.
Edward: The inception of μTransfer emerged from a theoretical proposition. The community has observed that the performance of a neural network seemed to improve with its size. This naturally kindled the theoretical question, “What happens when the neural network is infinitely large?” If one extrapolates the notion that larger networks perform better, it stands to reason that an infinitely large network would exhibit exceptional performance. This, however, is not a vacuous question.
When one postulates an infinite size, or more specifically, infinite width for a neural network, it becomes a theoretical object open to analysis. The intuition being, when you are summing over infinitely many things, mathematical tools such as convergence of random variables come into play. They can assist in reasoning about the behavior of the network. It is from this line of thought that μTransfer was conceived. In essence, it not only has practical applications but is also a satisfying instance of theory and empirical applications intersecting, where theory can meaningfully influence our practical approaches.
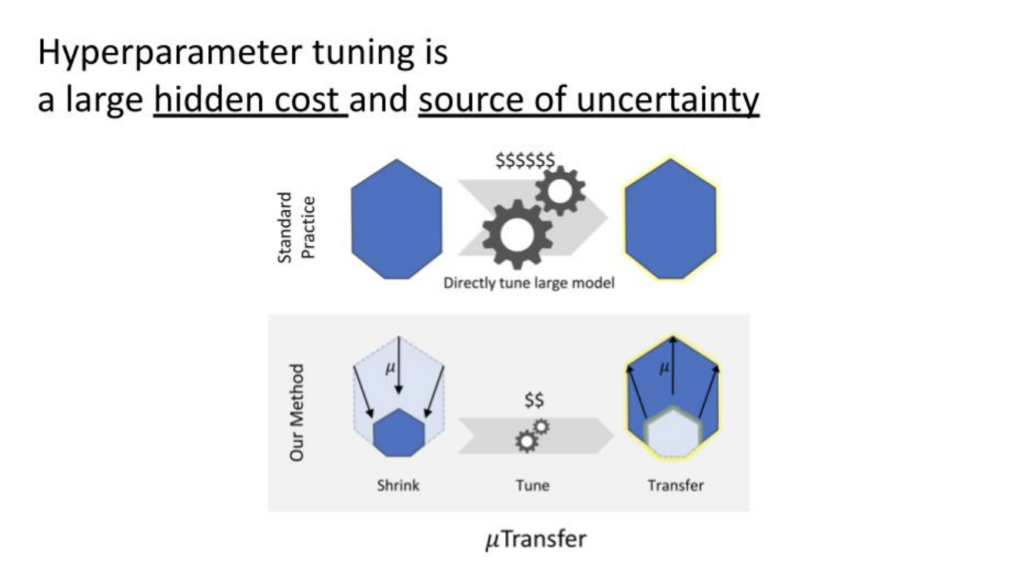
I’d like to touch upon the topic of hyperparameter training. Training large AI models often involves significant investments in terms of money and compute resources. For instance, the resources required to train a model the size of GPT-3 or GPT-4 are substantial. However, a frequently overlooked aspect due to its uncertainty is hyperparameter tuning. Hyperparameters are akin to knobs or magic numbers that need to be optimized for the model to train efficiently and yield acceptable results. They include factors like learning rate, optimizer hyperparameters, and several others. While a portion of the optimal settings for these has been determined by the community through trial and error, they remain highly sensitive. When training on a new dataset or with a novel model architecture, this tuning becomes essential yet again, often involving considerable guesswork. It turns out to be a significant hidden cost and a source of uncertainty.
To further expound on this, when investing tens of millions of dollars to train the next larger model, there’s an inherent risk of the process failing midway due to suboptimal hyperparameters, leading to a need to restart, which can be prohibitively expensive. To mitigate this, in our work with μTransfer, we adopt an alternative approach. Instead of experimenting with different hyperparameter combinations on a 100 billion parameter model, we employ our method to reduce the size of the model, making it more manageable.
In the past, determining the correct hyperparameters and setup was akin to building proprietary knowledge, as companies would invest significant time experimenting with different combinations. When you publish a research paper, you typically disclose your experimental results, but rarely do you share the precise recipe for training those models. The working hyperparameters were a part of the secret. However, with tools like μTransfer, the cost of hyperparameter tuning is vastly reduced, and more people can build a recipe to train a large model.
We’ve discovered a way to describe a neural network that allows for the maximal update of all parameters, thus enabling feature learning in the infinite-width limit. This in turn gives us the ability to transfer hyperparameters, a concept that might need some elucidation. Essentially, we make the optimal hyperparameters the same for the large model and the small model, making the transfer process rather straightforward – it’s as simple as a ‘copy and paste’.
When you parameterize a neural network using the standard method in PyTorch, as a practitioner, you’d observe that the optimal learning rate changes and requires adaptation. However, with our method of maximal update parameterization, we achieve a natural alignment. This negates the need to tune your large model because it will have the same optimal hyperparameters as a small model, a principle we’ve dubbed ‘mu transfer’. Indeed, “μ” in “μTransfer” stands for “maximal update,” which is derived from a parameterization we’ve dubbed “maximal update parameterization”.
To address potential prerequisites for this transfer process, for the most part, if you’re dealing with a large model, like a large transformer, and you are shrinking it down to a smaller size, there aren’t many restrictions. There are a few technical caveats; for instance, we don’t transfer regularization hyperparameters because they are more of an artifact encountered when we don’t have enough data, which is usually not an issue when pretraining a large model on the Internet.
Nonetheless, this transfer needs to occur between two models of the same architecture. For example, if we have GPT3 175 B for which we want to find the hyperparameters, we would shrink it down to GPT3 10 mil or 100 mil to facilitate the transfer of hyperparameters from the small model to the large model. It doesn’t apply to transferring hyperparameters between different types of models, like from a diffusion model to GPT.
Aparna: A trend in recent research indicates that the cost of training foundational models is consistently decreasing. For instance, training and optimizing a model at a smaller scale and then transferring these adjustments to a larger scale significantly reduces time and cost. Consequently, these models become more accessible, enabling entrepreneurs to utilize them and fine-tune them for various applications. Edward, do you see this continuing?
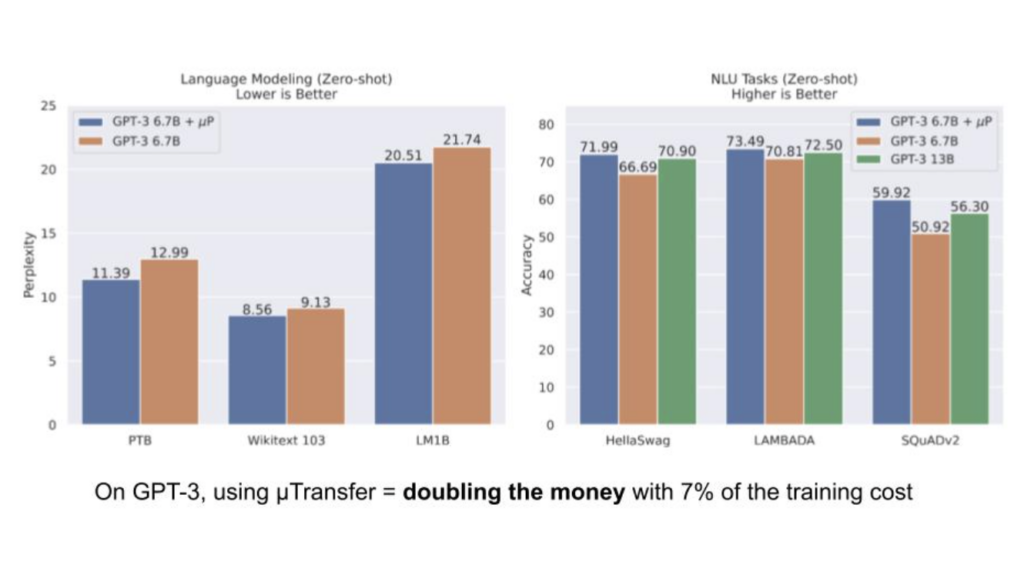
Edward: Techniques like μTransfer, which significantly lower the barrier to entry for training large models, will play a pivotal role in democratizing access to these large models. For example, I find it particularly gratifying to see our work being used in the scaling of large language models, such as the open-source Cerebras-GPT, which comprises around 13 billion parameters or more.
In our experiments, we found that using μTransfer led to superior hyperparameters compared to those discovered through heuristics in the GPT-3 paper. The improved hyperparameters allowed a 6.7 billion parameter model to roughly match the performance of a 13 billion parameter model, effectively doubling the value of the original model with only a 7% increase in the pre-training cost.
Aparna: It appears that the direction of this technology is moving towards a world where numerous AI models exist, no longer monopolized by one or two companies. How do you envision the utilization of these models evolving in the next one or two years?
Edward: It’s crucial to comprehend the diverse ways in which computational resources are utilized in training AI models. To begin with, one could train a large-scale model on general domain data, such as the Pile or a proprietary combination of internet data. Despite being costly, this is typically a one-time investment, except for occasional updates when new data emerges or a significant breakthrough changes the model architecture.
Secondly, we have domain-specific training, where a general-purpose model is fine-tuned to suit a particular field like law or finance. This form of training doesn’t require massive amounts of data and, with parameter-efficient fine-tuning methods like LoRA, the associated costs are dropping significantly.
Finally, there’s the constant use of hardware and compute in inference, which, unlike the first two, is an ongoing cost. This cost may end up dominating if the model or domain isn’t changed frequently.
Aparna: Thank you for the comprehensive explanation. Shifting gears a bit, I want to delve into your academic pursuits. Despite your significant contributions that have been commercialized, you remain an academic at heart, now back at Mila focusing on your research. I’m curious about your perspectives on academia, the aspects of research that excite you, and what you perceive to be the emerging horizons in this space.
Edward: This question resonates deeply with me. Even when I was at Microsoft, amidst exciting projects and the training of large models, I would often contemplate the next significant advancements in the principles and fundamentals underpinning the training of these models. There are myriad problems yet to be solved.
Data consumption and computational requirements present unique challenges to current AI models like GPT-4. As these models are trained on increasingly larger data sets, we might reach a point where we exhaust high-quality internet content. Moreover, despite their vast data processing, these models fail at executing relatively simple tasks, such as summing a long string of numbers, which illustrates the gap between our current AI and achieving Artificial General Intelligence (AGI). AGI should be able to accomplish simple arithmetic effortlessly. This gap is part of what motivates my research into better ways to structure computation and enhance reasoning capabilities within AI.
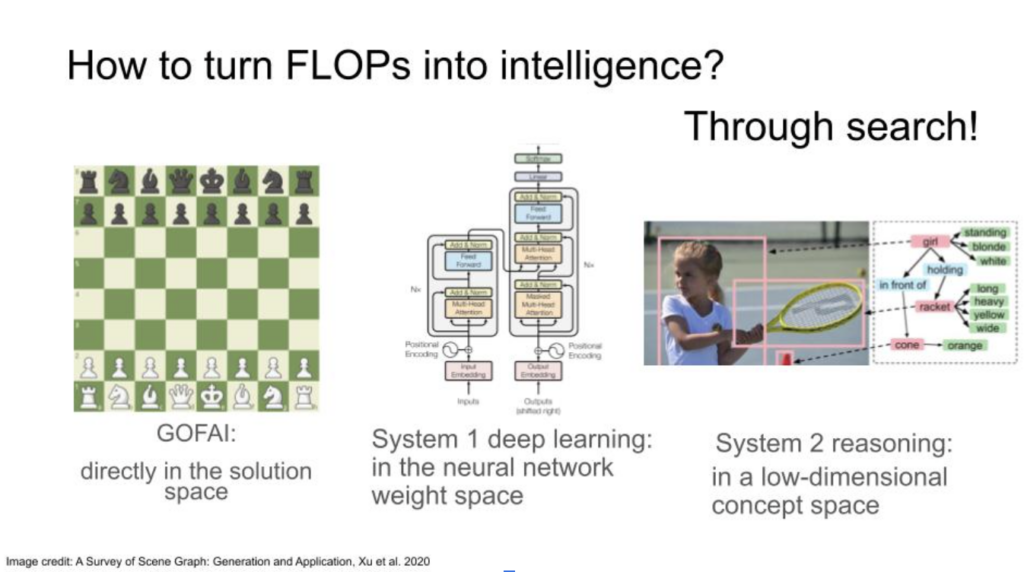
Shifting back to the topic of reasoning, it’s an exciting direction since it complements the scaling process and is even enabled by it. The fundamental question driving our research is, “How can we convert computations, or flops, into intelligence?” In the past, AI was not particularly efficient at transforming compute into intelligence, primarily due to limited computational resources and ineffective methods. Although we’re doing a better job now, there’s still room for improvement.
The key to turning flops into intelligence lies in the ability to perform effective search processes. Intelligence, at its core, represents the capability to search for reasons, explanations, and sequences of actions. For instance, when devising a move in chess, one examines multiple possible outcomes and consequences—a form of search. This concept is not exclusive to games like chess but applies to any context requiring logical reasoning.
Traditional AI—often referred to in research communities as “good old fashioned AI” or “GOFAI”—performed these search processes directly in the solution space. It’s analogous to playing chess by examining each possible move directly. However, the efficiency of these processes was often lacking, which leads us to the development of modern methods.
The fundamental challenge we face in computational problem-solving, such as in a game of chess, is that directly searching the solution space for our next move can be prohibitively expensive, even when we try to exhaustively simulate all possibilities. This issue escalates when we extend it to complex domains like language processing, planning, or autonomous driving.
Today, deep learning has provided us with an effective alternative. Although deep learning is still a form of search, we are now exploring in the space of neural network weights, rather than directly in the solution space. Training a neural network essentially involves moving within a vast space of billions of parameters and attempting to locate an optimal combination. While this might seem like trading one immense search space for another, the introduction of optimization techniques such as gradient descent has made this search more purposeful and guided.
However, when humans think, we are not merely searching in the weight space. We are also probing what we might call the ‘concept space.’ This space consists of explanations and abstract representations; we formulate narratives around the entities involved and their relationships. Therefore, the next frontier of AI research, which we are currently exploring at Mila with Yoshua, involves constructing models capable of searching this ‘concept space.’
Building on the foundations of large-scale, deep learning neural networks, we aim to create models that can autonomously discover concepts and their relationships. This approach harkens back to the era of ‘good old fashioned AI’ where researchers would manually construct knowledge graphs and scene graphs. However, the major difference lies in the model’s ability to learn these representations organically, without explicit instruction.
We believe that this new dimension of search will lead to better ‘sample complexity,’ meaning that the models would require less training data. Moreover, because these models have a more structured, lower-dimensional concept space, they are expected to generalize much better to unseen data. Essentially, after seeing a few examples, these models would ideally know how to answer the same type of question on unseen examples.
Aparna: Thank you, Edward. Your insights have been both practical, pertaining to present technologies that our founders can utilize, as well as forward-looking, providing a glimpse into the ongoing research that is shaping the future of artificial intelligence. Thank you so much for taking us through your inventions and making this information so accessible to our audience.
Join me for the next Perspectives in AI fireside, hosted monthly at Pear for up to date technical deep dives on emerging areas in Artificial Intelligence. You can find an archive of previous talks here.
Last month, PearX S21 alum Transcera announced its seed round led by Xora Innovation, joined by Tau Ventures and existing pre-seed investors Pear, Digitalis Ventures, and KdT Ventures. To mark this milestone, we wanted to share more about Pear’s partnership with Transcera and its founders, Hunter Goble (CEO), Justin Wolfe (CSO), and Wayne Lencer (scientific co-founder).
We first met Hunter and Wayne when they applied to Pear Competition. Hunter was still an MBA student at HBS and Wayne was a professor at Harvard Medical School and researcher at Boston Children’s Hospital. At the time, they were part of the Nucleate program and looking to commercialize a new drug delivery platform they were working on.
S21 PearX Demo Day
When we met the team, we were excited about Transcera for several reasons:
Enormous unmet need and market opportunity. Today, many of the most impactful and best-selling medicines are so-called biologic drugs, comprising complex molecules that are typically synthesized via living systems rather than chemical means. These are large, bulky molecules including peptides or proteins that often exhibit little-to-no uptake upon oral dosing, and instead have to be injected into the blood or under the skin. For obvious reasons, when given a choice, patients strongly prefer the convenience of a self-administered pill. For example, pharma companies are now racing to develop orally administered versions of GLP-1 receptor agonists for obesity, as the first such drugs approved for this blockbuster indication have required administration via subcutaneous injection.
Broad, differentiated, and defensible technology platform – inspired by nature, informed by high-quality science, and validated preclinically. For almost three decades, Wayne and his group have been studying how large, orally ingested bacterial toxins, such as cholera toxin, are able to cross the intestinal epithelial barrier to cause disease. The lab discovered that structural features of key membrane constituents called glycosphingolipids directly influence the cellular sorting of these lipids and any associated payloads. Building on this foundational work, Transcera has demonstrated preclinically that synthetic lipids can be harnessed to achieve transport of biologics across intestinal barrier cells, enabling oral delivery and enhanced biodistribution. This active transport mechanism is differentiated from most existing approaches to enhancing oral bioavailability, which have primarily focused on passive diffusion enabled by permeation enhancers and other formulation excipients, and have suffered from relatively low absorption and narrow applicability.
Ambitious operating team with complementary skill sets. Prior to HBS, Hunter spent 5 years at Eli Lilly working on the commercial launch of a key drug product, and he also served as an internal consultant around new product planning for the pharma company’s immunology division. Justin completed his PhD in the Pentelute lab at MIT where he focused on delivery strategies for biologic drugs, including novel conjugation approaches for peptides, and he later worked as a scientist advancing the discovery and medicinal chemistry of macrocyclic peptides at Ra Pharmaceuticals through its acquisition by UCB. Whereas Hunter brings a savvy commercial mindset and disciplined financial rigor to Transcera, Justin in turn brings apt academic and industry domain expertise and strong scientific leadership skills. Hunter, Justin, and Wayne all share a passion for translating basic science research into technologies and programs that can make a tremendous impact for patients.
We have been impressed with the Transcera team’s execution and scientific progress so far. During PearX S21, we worked closely with Hunter on shaping the story and crafting the pitch ahead of Demo Day. Before joining the Pear team full-time as Pear’s biotech partner, I served as an industry mentor to Transcera, advising the team on questions related to IP in-licensing. After joining Pear, I continued to work closely with Transcera and fellow syndicate co-investors on scientific strategy, fundraising, and partnering.
The full PearX S21 cohort after Demo Day
Over the past two years, the Transcera team has proven to be resilient and resourceful. The production and scale-up of the synthetic lipid conjugates were challenging to master, but the team’s diligent efforts yielded multiple promising lead compounds. Critically, the team has expanded to bring in hands-on expertise in chemistry, cellular biology, and preclinical development, among other areas.
With this recent financing, we are excited to continue to back the Transcera team, and we are eager to see further development of the platform, with the ultimate goal of unlocking the full potential of biologic drugs for patients.
The Transcera team is hiring! Please check out the job posting here: https://jobs.polymer.co/transcera/28175. If you’re interested please reach out to Eddie and we can connect you!
I’m incredibly excited to share that Arash Ferdowsi, Co-founder and former CTO of Dropbox, has joined Pear as our newest Visiting Partner!
I’ve known Arash since 2007, when Dropbox was still just two people: Arash and his Co-founder Drew. I was immediately inspired by their vision and drive and fortunate enough to be an early backer. The first time I sat down with Arash and Drew, we didn’t talk about the ins and outs of cloud storage, but instead we just talked about becoming good long-term partners.
From left to right: Sequoia’s Mike Moritz, Arash, and myself at a small apartment that was being used as an early Dropbox office. Arash’s co-founder Drew snapped this picture.
Arash helped to grow and scale Dropbox from inception to IPO. As Co-founder and CTO, he truly accomplished so much: building and scaling a company that is used by hundreds of millions of people.
Dropbox IPO in 2018.
Arash departed the company in 2020, and since that time he’s become a successful angel investor. We’ve been fortunate to partner with him on co-investments and welcome him to Pear as a visiting speaker on a number of occasions.
Arash at Pear’s celebration for Persians in tech
Over the last 15 years, Arash and I have truly built a great relationship on a foundation of true partnership, and I’m very excited to have him join Pear in a more official capacity.
We’re looking forward to Arash working with Pear founders. Welcome to the family, Arash!
Honey Homes, closed their Series A recently, led by Khosla Ventures and supported by Pear and others. To mark the occasion, we thought we’d do a little lookback of our history working with the Honey Homes team over the last few years.
We were first introduced to Honey Homes’ Founder and CEO Vishwas Prabhakara through DoorDash alums, including Evan Moore. The Khosla team knew that the Honey Homes team had a promising early idea and felt Pear would be great seed partners in shaping it into a venture-scalable business.
Once we met the team, we were excited about backing them for a few key reasons:
First of all, we knew this was a massive and unsolved market opportunity. US homeowners spend $250 billion annually on their homes via a highly-fragmented vendor network. The Honey Homes team saw a big opportunity to streamline that network and create a product experience that has never existed for home owners. Most home services companies are marketplaces or managed marketplaces, so it is challenging to make the economics work and keep the quality bar high while scaling. This results in churn from both the supply and demand side. Honey Homes saw an opportunity to do things differently and build out a new model – a homeowner subscription business where they employ handy people. This changes the economics and raises the quality bar substantially.
Secondly, they had a clear vision for a product to meet that market demand. The Honey Homes team wanted to build a membership service for busy homeowners to manage and complete to-do lists. I was a new homeowner myself at the time, could easily relate the never ending list of tasks to maintain my home and the difficulty of finding and keeping handymen. I found the idea of a reliable membership service really enticing.
Finally, we felt that the team was really strong and perfectly suited to tackle this problem. Vishwas was Yelp’s first General Manager and he was also COO of Digit, where he gained valuable experience as an operator. He understood first hand the piecemealing that homeowners have to do for maintenance and improvement work. Avantika Prabhakara, who leads Marketing at Honey Homes, has a rich marketing background from organizations like Opendoor, Trulia, and Zillow, so she’s also deeply familiar with the challenges people face on finding reliable contractors and handyman services.
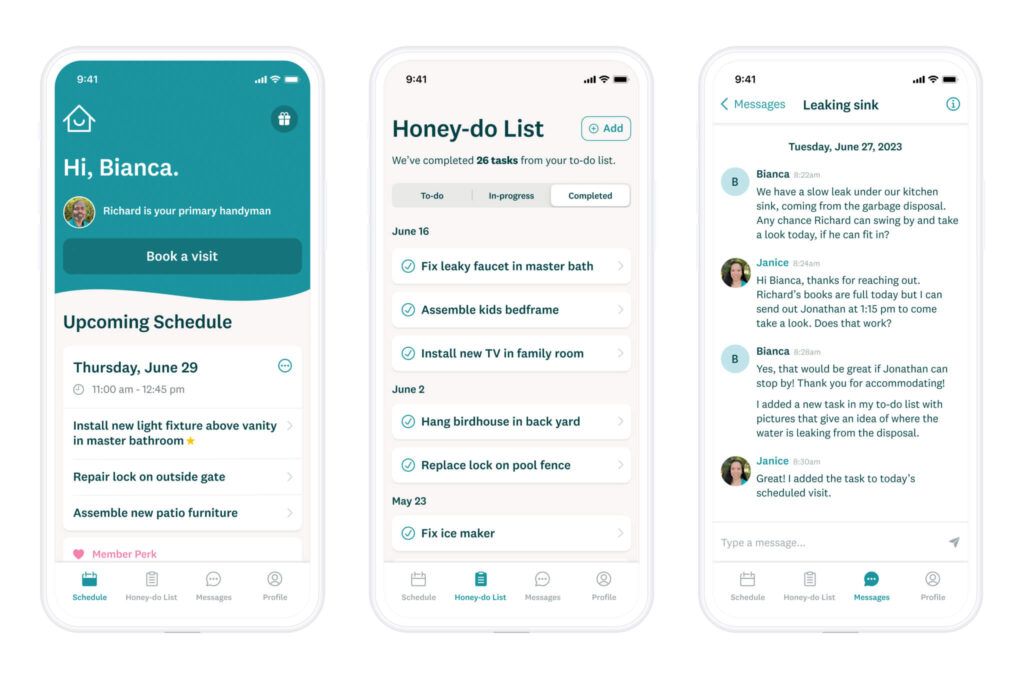
The Honey Homes app is easy-to-use for homeowners.
Khosla and Pear co-led the seed round in July 2021. Over the last two years, they’ve focused on building out the infrastructure to make this service work, growth in their initial markets, and eliminating key risks in order to raise their Series A. They grew from just a co-founding team to 12 employees and 14 handymen during this time. They also expanded across the Bay Area and Dallas and onboarded 500+ subscription customers. In total, over 20,000 home tasks have been completed for members through more than 10,000 Honey Homes visits over the last two years.
I’ve been lucky enough to not only be an investor into Honey Homes, but also an early customer. I started using Honey Homes in March 2022, and I’ve had hundreds of tasks completed in my home ranging from fixing a frustrating leaky pond to helping us move our furniture to fixing water-damaged cracks in our ceiling to cleaning out dryer ducts. We use the service so regularly that even my daughter knows our handyman, Miguel, by name. Honey Homes has had an incredibly strong customer response: everyone who hears about it wants to join and they’ve done an excellent job retaining customers.
We’re so proud of the team for successfully raising their Series A and cannot wait for their continued growth and success!
We’re excited to share that Aparna Sinha is Pear’s newest Partner! Aparna has made an outsized impact in her time with us as a Visiting Partner, and we couldn’t be more thrilled that she’s joining our team full time.
Aparna brings a strong thesis and a depth of experience in enterprise, developer, and AI to Pear and is excited to work with ambitious founders during this breakout moment in AI. “We’re in the midst of unprecedented technological advancement. AI is re-shaping our present and enabling the most significant breakthroughs of our lifetimes. The breadth and pace of this technological shift creates an opportunity for startups to disrupt the value chain and reshape how we interact with our world,” says Aparna. “Pear’s co-founder is a female former founder with a PhD in engineering, and our work to grow top female technical entrepreneurs resonates with me,” she continued.
Over the last six months, Aparna helped launch PearX for AI, a new track of the PearX program tailored towards AI builders. We recently welcomed six teams to the inaugural PearX for AI cohort and are excited for these founders to debut their companies with the world soon. Through the PearX for AI program, Aparna is partnering with founders to define their product, win early customers, and grow. She’s able to leverage her deep experience from Google and in enterprise software to give Pear’s portfolio companies an advantage in the market.
Aparna is also building out our AI advisor community, connecting Pear founders with industry experts from organizations like Stanford, Google, OpenAI, Hugging Face, McKinsey and more. At this moment, AI is touching every single facet of technology and she’s been working to build a top notch council of advisors to assist Pear founders on their entrepreneurial journeys.
We’re so excited to welcome Aparna. If you’re a founder looking to connect, please email her at aparna@pear.vc.