
We recently hosted a fireside chat on Generative AI with Nazneen Rajani, Robustness Researcher at HuggingFace. During the discussion, we touched on the topic of Open source AI models, the evolution of Foundation Models, and frameworks for model evaluation.
The event was attended by over 200 founders and entrepreneurs in our PearVC office in Menlo Park. For those who couldn’t attend in person, we are excited to recap the high points today (answers are edited and summarized for length). A short highlight reel can be also found here, thanks to Cleancut.ai who attended the talk.
Aparna: Nazneen, what motivated you to work in AI Robustness, could you share a bit about your background?
Nazneen: My research journey revolves around large language models, which I’ve been deeply involved in since my PhD. During my PhD, I was funded by the DARPA Explainable AI (XAI) grant, focusing on understanding and interpreting model outputs. At that time, I worked with RNNs and LSTMs, particularly in tasks involving Vision and language, as computer vision was experiencing significant advancements. Just as I was graduating, the transformer model emerged and took off in the field of NLP.
Following my PhD, I continued my work at Salesforce Research, collaborating with Richard Socher on interpreting deep learning models using GPT-2. It was fascinating to explore why models made certain predictions and generate explanations for their outputs. Recently, OpenAI published a paper using GPT4 to interpret neurons in GPT-2, which came full circle for me..
Currently, my focus is on language models, specifically on hallucination factuality, interpretability, robustness, and the ethical considerations surrounding these powerful technologies. I am currently part the H4 team at Hugging Face, working on building an open-source alternative to GPT, providing similar power and capabilities. Our goal is to share knowledge, artifacts, and datasets to bridge the gap between GPT-3-level models and InstructGPT or GPT-4, fostering open collaboration and accessibility.
Aparna: That’s truly impressive, Nazneen. Your background aligns perfectly with the work you’re doing at Hugging Face. Now, let’s dive deeper into understanding what Hugging Face is and what it offers.
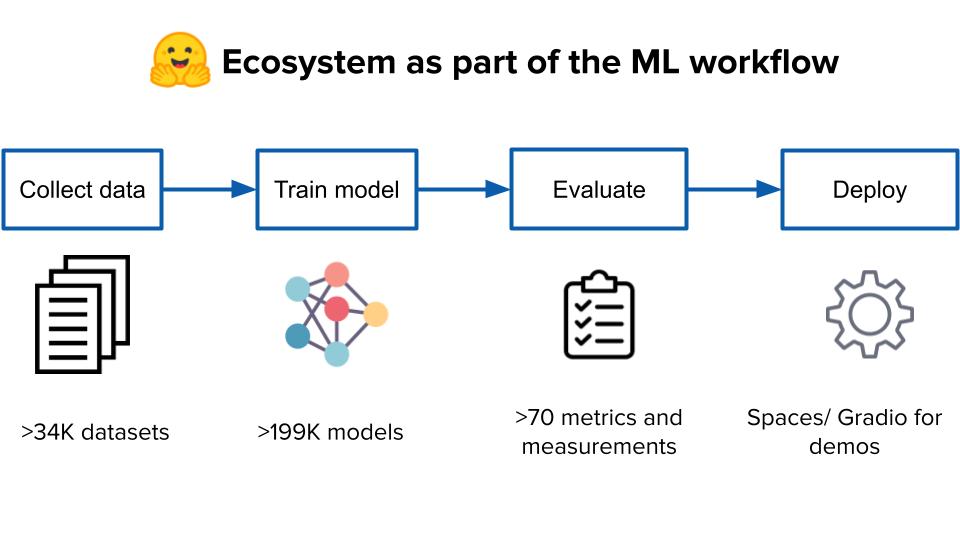
Nazneen: Hugging Face can be thought of as the “GitHub of machine learning.” It supports the entire pipeline of machine learning, making it incredibly accessible and empowering for users. We provide a wide range of resources, starting with datasets. We have over 34,000 datasets available for machine learning purposes. Additionally, we offer trained models, which have seen tremendous growth. We now have close to 200,000 models, a significant increase from just a few months ago.
In addition to datasets and models, we have a library called “evaluate” that allows users to assess model performance using more than 70 metrics. We also support deployment through interactive interfaces like Streamlit and Gradio, as well as Docker containers for creating containerized applications. Hugging Face’s mission is to democratize machine learning, enabling everyone to build their own models and deploy them. It’s a comprehensive ecosystem that supports the entire machine learning pipeline.
Aparna: Hugging Face has become such a vital platform for machine learning practitioners. But what would you say are the benefits of open-source language models compared to closed-source models like GPT-4.
Nazneen: Open-source language models offer several significant advantages. Firstly, accessibility is a key benefit. Open-source models make these powerful technologies widely accessible to users, enabling them to leverage their capabilities. The rate of progress in the field is accelerated by open-source alternatives. For example, when pivotal moments like the release of datasets such as RedPajama or LAION or the LLAMA weights occur, they contribute to rapid advancements in open-source models.
Collaboration is another crucial aspect. Open-source communities can come together, share resources, and collectively build strong alternatives to closed models. The compute is no longer a bottleneck for open source.. The reduced gap between closed and open-source models demonstrates how collaboration fosters progress. Ethical considerations also come into play. Open-source models often have open datasets and allow for auditing, risk analysis.
Open-source models make these powerful technologies widely accessible to users, enabling them to leverage their capabilities.

Aparna: Nazneen, your chart showing the various models released over time has been highly informative. It’s clear that the academic community and companies have responded strongly to proprietary models. Could you explain what Red Pajama is for those who might not be familiar with it?
Nazneen: Red Pajama is an open-source dataset that serves as the foundation for training models. It contains an enormous amount of data, approximately 1.5 trillion tokens. This means that all the data used to train the foundation model, such as the Meta’s LLaMA, is now available to anyone who wants to train their own models, provided they have the necessary computing resources. This dataset has made the entire foundation model easily accessible. You can simply download it and start training your own models.
Aparna: It seems that the open source community’s reaction to closed models, has led to the development of alternatives like Red Pajama. For instance, Facebook’s Llama had a restrictive license that prevented its commercial use, which triggered the creation of Red Pajama.
Nazneen: Absolutely, Aparna. Currently, powerful technologies like these are concentrated in the hands of a few, who can control access and even decide to discontinue API support. This can be detrimental to applications and businesses relying on these models. Therefore, it is essential to make such powerful models more accessible, enabling more people to work with them and develop them. Licensing plays a significant role in this context, as it determines the openness and usability of models. At Hugging Face, we prioritize open sourcing and face limitations when it comes to closed models. We cannot train on their outputs or use them for commercial purposes due to their restrictive licenses. This creates challenges and a need for accessible alternatives.
It is essential to make such powerful models more accessible, enabling more people to work with them and develop them.
Aparna: Founders often start with GPT-4 due to its capabilities and ease of use. However, they face concerns about potential changes and the implications for the prompt engineering they’ve done. The uncertainty surrounding access to the model and its impact on building a company is a significant worry. Enterprises also express concerns about proprietary models, as they may face difficulties integrating them into their closed environments and ensuring safety and explainability. Are these lasting concerns?
Nazneen: The concerns raised by founders and enterprises highlight the importance of finding the right model and ensuring it fits their specific needs. This is where Hugging Face comes in. Today, we are releasing something called “transformer agents” that address this very challenge. An agent is a language model that you can chat with using natural language prompts to define your goals. We also provide a set of tools that serve as functions, which are essentially models from our extensive collection of 200,000 models. These tools are selected for you based on the task you describe. The language model then generates the necessary code and uses the tools to accomplish your goal. It’s a streamlined process that allows for customization and achieving specific objectives.
Aparna: I learned from my experience with Kubernetes that open source software is great for innovation. However, it can lack reliability and ease of use unless there’s a commercial entity involved. Some contributions may be buggy or poorly maintained, and the documentation may not always be updated or helpful. To address this, Google Cloud hosted Kubernetes to make it more accessible. How does Hugging Face help me navigate through 200,000 models and choose the right one for my needs?
Nazneen: The Transformers Agents can assist you with that exact task. Transformer agents are essentially language models that you can chat with. You provide a natural language prompt describing what you want to achieve, and the agent uses a set of pre-existing tools, which are essentially different models, to fulfill your request. These tools can be customized or extended to suit specific goals. The agent composes these tools and runs the code for you, making it a streamlined process. For example, you can ask the agent to draw a picture of a river, lakes, and trees, then transform that image into a frozen lake surrounded by a forest. These tools are highly customizable, allowing you to achieve your desired outcomes.
Aparna: It feels like the evolution of what we’ve seen with OpenAI’s GPT plug-ins and Langchain’s work on chaining models together. Does Hugging Face’s platform automate and simplify the process of building an end-to-end AI application?
Nazneen: Absolutely! The open-source nature of the ecosystem enables customization and validation. You can choose to keep it in a closed world setting if you have concerns about safety and execution of potentially unsafe code. Hugging Face provides tools to validate the generated code and ensure its safety. The pipeline created by Hugging Face connects the necessary models seamlessly, making it a powerful and efficient solution.
Aparna: This aligns with our investment thesis and the idea of building applications with models tailored to specific workflows. Switching gears, what are some of the applications where you would use GPT-3 and GPT4?
Nazneen: GPT-3 can be used for almost any task. The key approaches are in-context learning and pre-training. These approaches are particularly effective for tasks like entity linking or extraction, making the model more conversational.
While GPT-3 performs well on traditional NLP tasks like sentiment analysis, conversational models like GPT-4 shine in their ability to engage in interactive conversations and follow instructions. They can perform tasks and format data in specific ways, which sets them apart and makes them exciting.
The real breakthrough moment for generative AI was not GPT-3. Earlier chatbots like Blenderbot from Meta and Microsoft’s chatbots existed but were not as popular due to less refined alignment methodologies. The refinement in approaches like in-context learning and fine-tuning has led to wider adoption and breakthroughs in generative AI.
Aparna: How can these techniques address issues such as model alignment, incorrect content, and privacy concerns?
Nazneen: Techniques like RLHF focus on hallucination and factuality, allowing models to generate “I don’t know” when unsure instead of producing potentially incorrect information. Collecting preferences from domain experts and conducting human evaluations can improve model performance in specific domains. However, ethical concerns regarding privacy and security remain unresolved.
Aparna: I do want to ask you about evaluation. How do I know that the model that I find tuned is actually good? How can I really evaluate my work?
Nazneen: Evaluation is key for a language model because of the stochasticity of the thing. Before I talk about evaluation, I want to first talk about the types of learning or training that goes into these language models. There are four types of learning.
- The first is pre training, which is essentially building the foundation model.
- The second is in-context learning or in-context training, where no parameters are updated, but you give the model a prompt, and describe a new task that you want the model to achieve. It can either be zero shot, or a few shots. And then you give it a new example. It learns in context.
- The third one is supervised fine tuning, which is going from something like GPT3 to instruct GPT. So, you want this foundation model to follow instructions and chat with a human and generate outputs that are actually answers to what the person is looking for or being chatty and being open ended and also following instructions.
- The fourth type of training is called reinforcement learning with human feedback. In this case, you first train a reward model based on human preferences. What people have done in the past is, have humans generate a handful of examples, and then ask something like chat GPT to generate more. That is how Alpaca came about and the self instruct data set came about.
For evaluating the first two types of learning, pre-training and in-context learning, we can use benchmarks like the big bench from Google, or the helm benchmarks from Stanford, which are very standard benchmarks of NLP tasks.
During supervised fine tuning, you evaluate for chattiness, whether the language model is actually generating open-ended answers, and also whether it’s actually able to follow instructions. We cannot use these NLP benchmarks here.
We also have to evaluate the reward model to make sure that it has actually learned the values we care about. The things that people generally train the reward model on are truthfulness, harmlessness, and helpfulness. So how good is the response in these dimensions?
Finally, the last part is the very interesting final way to evaluate is called Red Teaming, which comes in the very end. In this case, you’re trying to adversarially attack or prompt the model, and see how it does.
Aparna: What do you think are the defensible sources of differentiation in generative AI?
Nazneen: While generative AI is a crowded field, execution and data quality are key differentiators. Ensuring high-quality data and disentangling hype from reality are crucial. Building models with good data quality can yield better results compared to models trained on noisy data. Investing effort and resources into data quality is essential.
While generative AI is a crowded field, execution and data quality are key differentiators.
Aparna: Lastly, what do you see as the major opportunities for AI in enterprise?
Nazneen: Enterprise AI solutions have major opportunities in leveraging proprietary data for training models. One example is streamlining employee onboarding by automating email exchanges, calendars, and document reading. Workflows in platforms like ServiceNow and Salesforce can also be automated using large language models. The enterprise space offers untapped potential for AI applications by utilizing data and automating various processes.