I recently hosted a fireside chat with AI researcher Edward Hu. Our conversation covered various aspects of AI technology, with a focus on two key inventions Edward Hu pioneered: Low Rank Adaptation (LoRA) and μTransfer, which have had wide ranging impact on the efficiency and adoption of Large Language Models. For those who couldn’t attend in person, here is a recap (edited and summarized for length).
Aparna: Welcome, everyone to the next edition of the ‘Perspectives on AI’ fireside chat series at Pear VC. I’m Aparna Sinha, a partner at Pear VC focusing on AI, developer tooling and cloud infrastructure investments. I’m very pleased to welcome Edward Hu today.
Edward is an AI researcher currently at Mila in Montreal, Canada. He is pursuing his PhD under Yoshua Bengio, who is a Turing award winner. Edward has a number of inventions to his name that have impacted the AI technology that you and I use every day. He is the inventor of Low Rank Adaptation (LoRA) as well as μTransfer, and he is working on the next generation of AI reasoning systems. Edward, you’ve had such an amazing impact on the field. Can you tell us a little bit about yourself and how you got started working in this field?
Edward: Hello, everyone. Super happy to be here. Growing up I was really interested in computers and communication. I decided to study both computer science and linguistics in college. I got an opportunity to do research at Johns Hopkins on empirical NLP, building systems that would understand documents, for example. The approach in 2017, was mostly building pipelines. So you have your name entity recognition module, that feeds into maybe a retrieval system, and then the whole thing in the end, gives you a summarization through a separate summarization module. This was before large language models.
I remember the day GPT-2 came out. We had a lab meeting and everybody was talking about how it was the same approach as GPT, but scaled to a larger data set and a larger model. Even though it was less technically interesting, the model was performing much better. I realized there is a limit to the gain we have from engineering traditional NLP pipelines. In just a few years we saw a transition from these pipelines to a big model, trained on general domain data and fine tuned on specific data. So when I was admitted as an AI resident at Microsoft Research, I pivoted to work on deep learning. I was blessed with many mentors while I was there, including Greg Yang, who recently started xAI. We worked on the science and practice of training huge models and that led to LoRA and μTransfer.
More recently, I’m back to discovering the next principles for intelligence. I believe we can gain much capability by organizing computation in our models. Is our model really thinking the way we think? This motivated my current research at Mila on robust reasoning.
Aparna: That’s amazing. So what is low rank adaptation in simple terms and what is it being used for?
Edward: Low Rank Adaptation (often referred to as LoRA) is a method used to adapt large, pre-trained models to specific tasks or domains without significant retraining. The concept is to have a smaller module that contains enough domain-specific information, which can be appended to the larger model. This allows for quick adaptability without altering the large model’s architecture or the need for extensive retraining. It performs as if you have fine tuned a large model on a downstream task.
For instance, in the context of diffusion models, LoRA enables the quick adaptation of a model to particular characters or styles of art. This smaller module can be quickly swapped out, changing the style of art without major adjustments to the diffusion model itself.
Similarly, in language processing, a LoRA module can contain domain-specific information in the range of tens to hundreds of megabytes, but when added to a large language model of tens of gigabytes or even terabytes, it enables the model to work with specialized knowledge. LoRA’s implementation allows for the injection of domain-specific knowledge into a larger model, granting it the ability to understand and process information within a specific field without significant alteration to the core model.
Aparna: Low rank adaptation seems like a compelling solution to the challenges of scalability and domain specificity in artificial intelligence. What is the underlying principle that enables its efficacy, and what led you to develop LoRA?
Edward: We came up with LoRA two years ago, and it has gained attention more recently due to its growing applications. Essentially, LoRA uses the concept of low rank approximation in linear algebra to create a smaller, adaptable module.This module can be integrated into larger models to customize them towards a particular task.
I would like to delve into the genesis of LoRA. During my time at Microsoft, when GPT-3 was released and the OpenAI-Microsoft partnership began, we had the opportunity to work with the 175-billion-parameter model, an unprecedented scale at that time. Running this model on production infrastructure was indeed painful.
Firstly, without fine-tuning, the model wasn’t up to our standards. Fine-tuning, is essential to adapt our models to specific tasks, and it became apparent that few-shot learning didn’t provide the desired performance for a product. Although once fine-tuned, the performance was amazing, the process itself was extremely expensive.
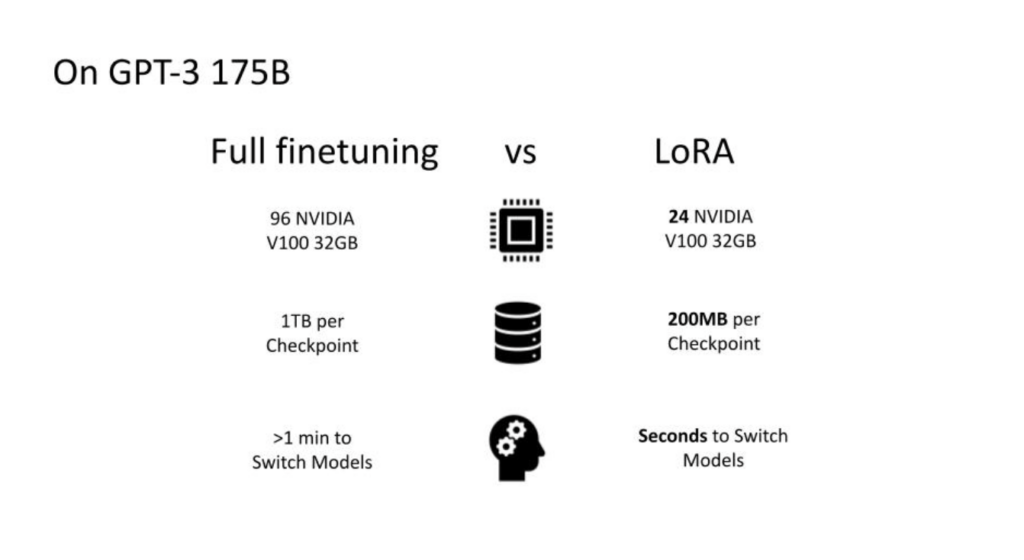
To elucidate, it required at least 96 Nvidia V100s, which was cutting-edge technology at the time and very hard to come by, to start the training process with a small batch size, which was far from optimal. Furthermore, every checkpoint saved was a terabyte in size, which meant that the storage cost was non-negligible, even compared to the GPUs’ cost. The challenges did not end there. Deploying the model into a product presented additional hurdles. If you wanted to customize per user, you had to switch models, a process that took about a minute with such large checkpoints. The process was super network-intensive, super I/O-intensive, and simply too slow to be practical.
Under this pressure, we sought ways to make the model suitable for our production environment. We experimented with many existing approaches from academia, such as adapters and prefix tuning. However, they all had shortcomings. With adapters, the added extra layers led to significant latency, a nontrivial concern given the scale of 175 billion parameters. For prefix tuning and other methods, the issue was performance, as they were not on par with full fine-tuning. This led us to think creatively about other solutions, and ultimately to the development of LoRA.
Aparna: That sounds like a big scaling problem, one that must have prevented LLMs from becoming real products for millions of users.
Edward: Yes, I’ll proceed to elaborate on how we solved these challenges, and I will discuss some of the core functionalities and innovations behind LoRA.
Our exploration with LoRA led to impressive efficiencies. We successfully devised a setup that could handle a 175 billion parameter model. By fine-tuning and adapting it, we managed to cut the resource usage down to just 24 V100s. This was a significant milestone for our team, given the size of the model. This newfound efficiency enabled us to work with multiple models concurrently, test numerous hyperparameter combinations, and conduct extensive model trimming.
What further enhanced our production capabilities was the reduction in checkpoint sizes, from 1 TB to just 200 megabytes. This size reduction opened the door to innovative engineering approaches such as caching in VRAM or RAM and swapping them on demand, something that would have been impossible with 1 TB checkpoints. The ability to switch models swiftly improved user experience considerably.
LoRA’s primary benefits in a production environment lie in the zero inference latency, acceleration of training, and lowering the barrier to entry by decreasing the number of GPUs required. The base model remains the same, but the adaptive part is faster and smaller, making it quicker to switch. Another crucial advantage is the reduction in storage costs, which we estimated to be a reduction by a factor of 1000 to 5000, a significant saving for our team.
Aparna: That’s a substantial achievement, Edward, paving the way for many new use cases.
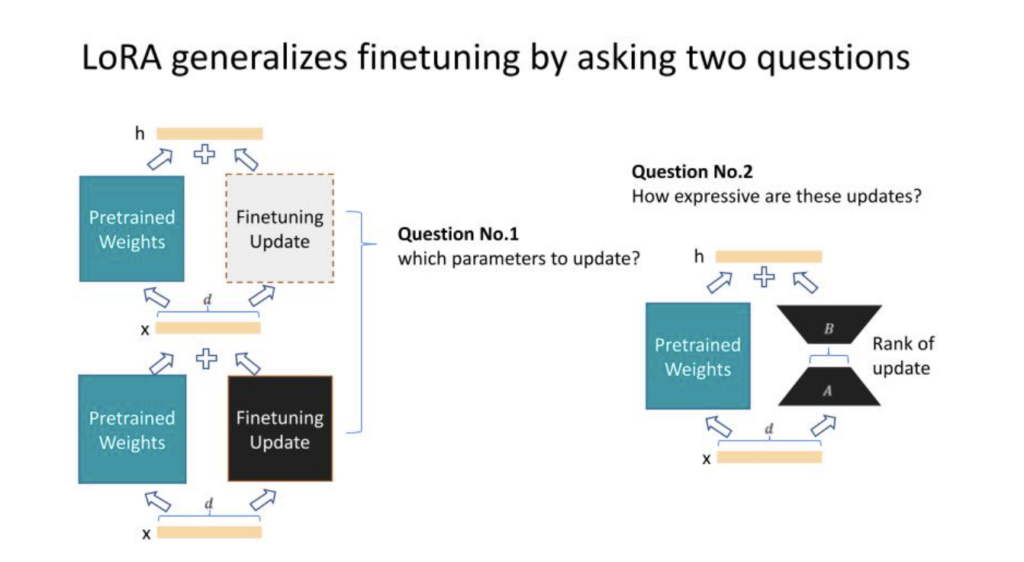
Edward: Indeed. Now, let’s delve into how LoRA works, particularly for those new to the concept. LoRA starts with fine-tuning and generalizes in two directions. The first direction concerns which parameters of the neural network – made up of numerous layers of weights and biases – we should adapt. This could involve updating every other layer, every third layer, or specific types of layers such as the attention layers or the MLP layers for a transformer.
The second direction involves the expressiveness of these adaptations or updates. Using linear algebra, we know that matrices, which most of the weights are, have something called rank. The lower the rank, the less expressive it is, providing a sort of tuning knob for these updates’ expressiveness. Of course, there’s a trade-off here – the more expressive the update, the more expensive it is, and vice versa.
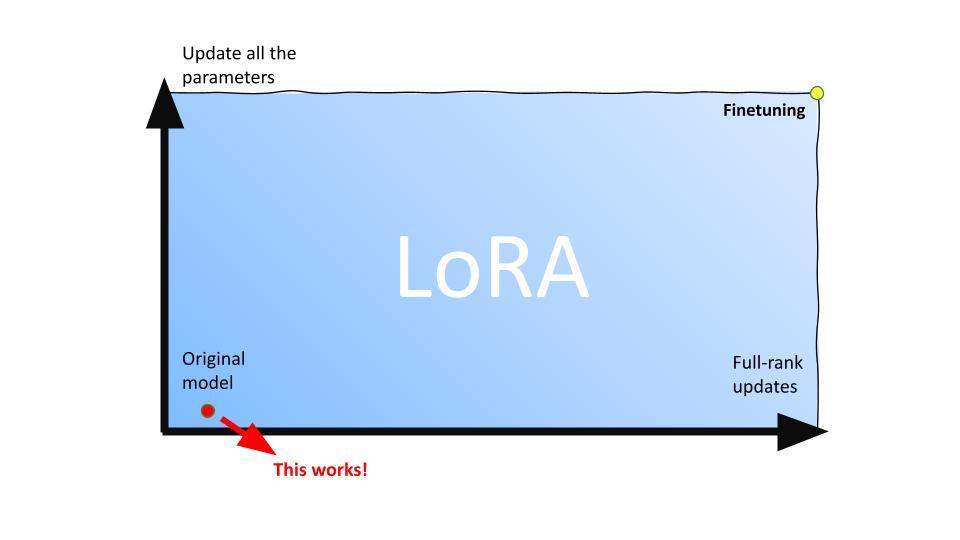
Considering these two directions, we essentially have a 2D plane to help navigate our model adaptations. The y-axis represents the parameters we’re updating – from all parameters to none, which would retain the original model. The parameters of our model exist on a plane where the x-axis signifies whether we perform full rank updates or low rank updates. A zero rank update would equate to no updating at all. The original model can be seen as the origin, and fine tuning as the upper right corner, indicating that we update all parameters, and these updates are full rank.
The introduction of LoRA allows for a model to move freely across this plane. Although it doesn’t make sense to move outside this box, any location inside represents a LoRA configuration. A surprising finding from our research showed that a point close to the origin, where only a small subset of parameters are updated using very low rank, can perform almost as well as full fine tuning in large models like GPT-3. This has significantly reduced costs while maintaining performance.
Aparna: This breakthrough is not only significant for the field as a whole, but particularly for OpenAI and Microsoft. It has greatly expanded the effectiveness and efficiency of large language models.
Edward: Absolutely, it is a significant leap for the field. However, it’s also built on a wealth of preceding research. Concepts like Adapters, Prefix Tuning, and the like have been proposed years before LoRA. Each new development stands on the shoulders of prior ones. We’ve built on these works, and in turn, future researchers will build upon LoRA. We will certainly have better methods in the future.
Aparna: From my understanding, LoRA is already widely used. While initially conceived for text-based models, it’s been applied to diffusion models, among other things.
Edward: Indeed, the beauty of this approach is its general applicability. Whether deciding which layers to adapt or how expressive the updates should be, these considerations apply to virtually any model that incorporates multiple layers and matrices, which is characteristic of modern deep learning. By asking these two questions, you can identify the ideal location within this ‘box’ for your model. While a worst case scenario would have you close to the upper right, thereby not saving as much, many models have proven to perform well even when situated close to the lower left corner. LoRA is also supported in HuggingFace nowadays, so it’s relatively easy to use.
Aparna: Do you foresee any potential challenges or limitations in its implementation? Are there any other domains or innovative applications where you envision LoRA making a significant impact in the near future?
Edward: While LoRA presents exciting opportunities, it also comes with certain challenges. Implementing low rank adaptation requires precision in crafting the smaller module, ensuring it aligns with the larger model’s structure and objectives. An imprecise implementation could lead to inefficiencies or suboptimal performance. Furthermore, adapting to rapidly changing domains or highly specialized fields may pose additional complexities.
As for innovative applications, I envision LoRA being utilized in areas beyond visual arts and language. It could be applied in personalized healthcare, where specific patient data can be integrated into broader medical models. Additionally, it might find applications in real-time adaptation for robotics or enhancing virtual reality experiences through customizable modules.
In conclusion, while LoRA promises significant advancements in the field of AI, it also invites careful consideration of its limitations and potentials. Its success will depend on continued research, collaboration, and innovative thinking.
Aparna: For many of our founders, the ability to efficiently fine tune models and customize them according to their company’s unique personality or data is fundamental to constructing a moat. What your work has done is optimize this process through tools like Lora and μTransfer. Would you tell us now about μTransfer, the project you embarked upon post your collaboration with Greg Yang on the theory of infinity with neural networks.
Edward: The inception of μTransfer emerged from a theoretical proposition. The community has observed that the performance of a neural network seemed to improve with its size. This naturally kindled the theoretical question, “What happens when the neural network is infinitely large?” If one extrapolates the notion that larger networks perform better, it stands to reason that an infinitely large network would exhibit exceptional performance. This, however, is not a vacuous question.
When one postulates an infinite size, or more specifically, infinite width for a neural network, it becomes a theoretical object open to analysis. The intuition being, when you are summing over infinitely many things, mathematical tools such as convergence of random variables come into play. They can assist in reasoning about the behavior of the network. It is from this line of thought that μTransfer was conceived. In essence, it not only has practical applications but is also a satisfying instance of theory and empirical applications intersecting, where theory can meaningfully influence our practical approaches.
I’d like to touch upon the topic of hyperparameter training. Training large AI models often involves significant investments in terms of money and compute resources. For instance, the resources required to train a model the size of GPT-3 or GPT-4 are substantial. However, a frequently overlooked aspect due to its uncertainty is hyperparameter tuning. Hyperparameters are akin to knobs or magic numbers that need to be optimized for the model to train efficiently and yield acceptable results. They include factors like learning rate, optimizer hyperparameters, and several others. While a portion of the optimal settings for these has been determined by the community through trial and error, they remain highly sensitive. When training on a new dataset or with a novel model architecture, this tuning becomes essential yet again, often involving considerable guesswork. It turns out to be a significant hidden cost and a source of uncertainty.
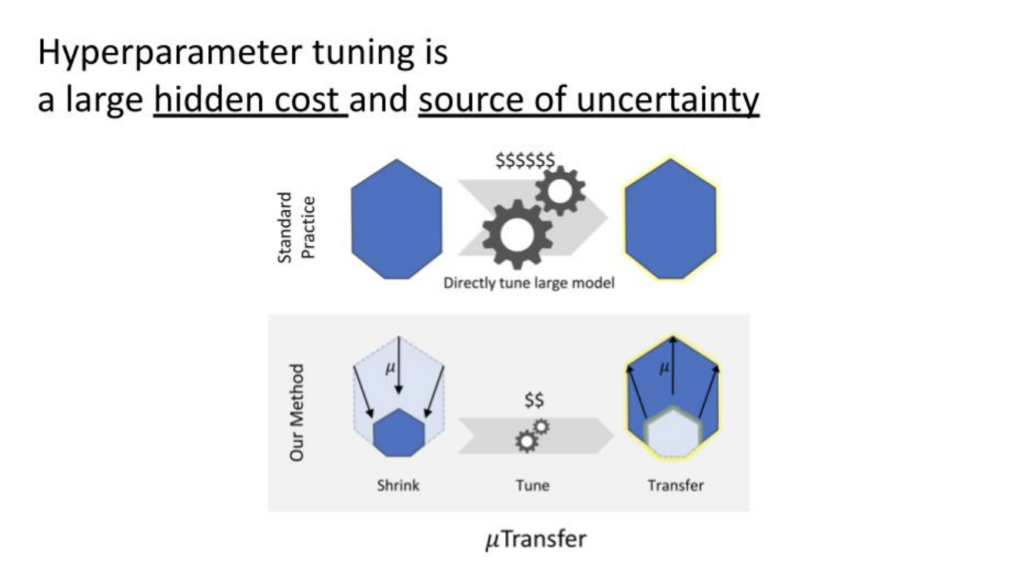
To further expound on this, when investing tens of millions of dollars to train the next larger model, there’s an inherent risk of the process failing midway due to suboptimal hyperparameters, leading to a need to restart, which can be prohibitively expensive. To mitigate this, in our work with μTransfer, we adopt an alternative approach. Instead of experimenting with different hyperparameter combinations on a 100 billion parameter model, we employ our method to reduce the size of the model, making it more manageable.
In the past, determining the correct hyperparameters and setup was akin to building proprietary knowledge, as companies would invest significant time experimenting with different combinations. When you publish a research paper, you typically disclose your experimental results, but rarely do you share the precise recipe for training those models. The working hyperparameters were a part of the secret. However, with tools like μTransfer, the cost of hyperparameter tuning is vastly reduced, and more people can build a recipe to train a large model.
We’ve discovered a way to describe a neural network that allows for the maximal update of all parameters, thus enabling feature learning in the infinite-width limit. This in turn gives us the ability to transfer hyperparameters, a concept that might need some elucidation. Essentially, we make the optimal hyperparameters the same for the large model and the small model, making the transfer process rather straightforward – it’s as simple as a ‘copy and paste’.
When you parameterize a neural network using the standard method in PyTorch, as a practitioner, you’d observe that the optimal learning rate changes and requires adaptation. However, with our method of maximal update parameterization, we achieve a natural alignment. This negates the need to tune your large model because it will have the same optimal hyperparameters as a small model, a principle we’ve dubbed ‘mu transfer’. Indeed, “μ” in “μTransfer” stands for “maximal update,” which is derived from a parameterization we’ve dubbed “maximal update parameterization”.
To address potential prerequisites for this transfer process, for the most part, if you’re dealing with a large model, like a large transformer, and you are shrinking it down to a smaller size, there aren’t many restrictions. There are a few technical caveats; for instance, we don’t transfer regularization hyperparameters because they are more of an artifact encountered when we don’t have enough data, which is usually not an issue when pretraining a large model on the Internet.
Nonetheless, this transfer needs to occur between two models of the same architecture. For example, if we have GPT3 175 B for which we want to find the hyperparameters, we would shrink it down to GPT3 10 mil or 100 mil to facilitate the transfer of hyperparameters from the small model to the large model. It doesn’t apply to transferring hyperparameters between different types of models, like from a diffusion model to GPT.
Aparna: A trend in recent research indicates that the cost of training foundational models is consistently decreasing. For instance, training and optimizing a model at a smaller scale and then transferring these adjustments to a larger scale significantly reduces time and cost. Consequently, these models become more accessible, enabling entrepreneurs to utilize them and fine-tune them for various applications. Edward, do you see this continuing?
Edward: Techniques like μTransfer, which significantly lower the barrier to entry for training large models, will play a pivotal role in democratizing access to these large models. For example, I find it particularly gratifying to see our work being used in the scaling of large language models, such as the open-source Cerebras-GPT, which comprises around 13 billion parameters or more.
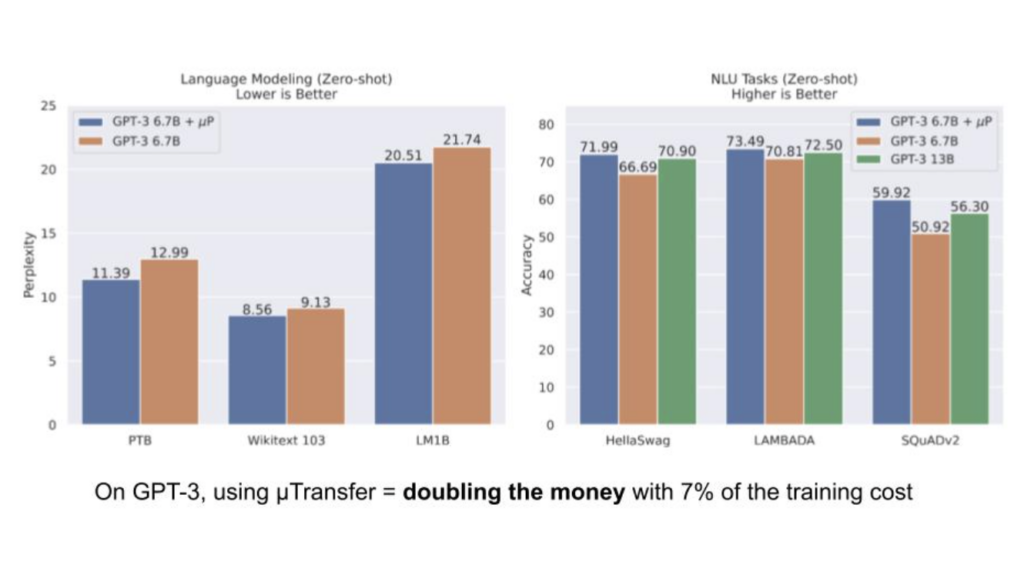
In our experiments, we found that using μTransfer led to superior hyperparameters compared to those discovered through heuristics in the GPT-3 paper. The improved hyperparameters allowed a 6.7 billion parameter model to roughly match the performance of a 13 billion parameter model, effectively doubling the value of the original model with only a 7% increase in the pre-training cost.
Aparna: It appears that the direction of this technology is moving towards a world where numerous AI models exist, no longer monopolized by one or two companies. How do you envision the utilization of these models evolving in the next one or two years?
Edward: It’s crucial to comprehend the diverse ways in which computational resources are utilized in training AI models. To begin with, one could train a large-scale model on general domain data, such as the Pile or a proprietary combination of internet data. Despite being costly, this is typically a one-time investment, except for occasional updates when new data emerges or a significant breakthrough changes the model architecture.
Secondly, we have domain-specific training, where a general-purpose model is fine-tuned to suit a particular field like law or finance. This form of training doesn’t require massive amounts of data and, with parameter-efficient fine-tuning methods like LoRA, the associated costs are dropping significantly.
Finally, there’s the constant use of hardware and compute in inference, which, unlike the first two, is an ongoing cost. This cost may end up dominating if the model or domain isn’t changed frequently.
Aparna: Thank you for the comprehensive explanation. Shifting gears a bit, I want to delve into your academic pursuits. Despite your significant contributions that have been commercialized, you remain an academic at heart, now back at Mila focusing on your research. I’m curious about your perspectives on academia, the aspects of research that excite you, and what you perceive to be the emerging horizons in this space.
Edward: This question resonates deeply with me. Even when I was at Microsoft, amidst exciting projects and the training of large models, I would often contemplate the next significant advancements in the principles and fundamentals underpinning the training of these models. There are myriad problems yet to be solved.
Data consumption and computational requirements present unique challenges to current AI models like GPT-4. As these models are trained on increasingly larger data sets, we might reach a point where we exhaust high-quality internet content. Moreover, despite their vast data processing, these models fail at executing relatively simple tasks, such as summing a long string of numbers, which illustrates the gap between our current AI and achieving Artificial General Intelligence (AGI). AGI should be able to accomplish simple arithmetic effortlessly. This gap is part of what motivates my research into better ways to structure computation and enhance reasoning capabilities within AI.
Shifting back to the topic of reasoning, it’s an exciting direction since it complements the scaling process and is even enabled by it. The fundamental question driving our research is, “How can we convert computations, or flops, into intelligence?” In the past, AI was not particularly efficient at transforming compute into intelligence, primarily due to limited computational resources and ineffective methods. Although we’re doing a better job now, there’s still room for improvement.
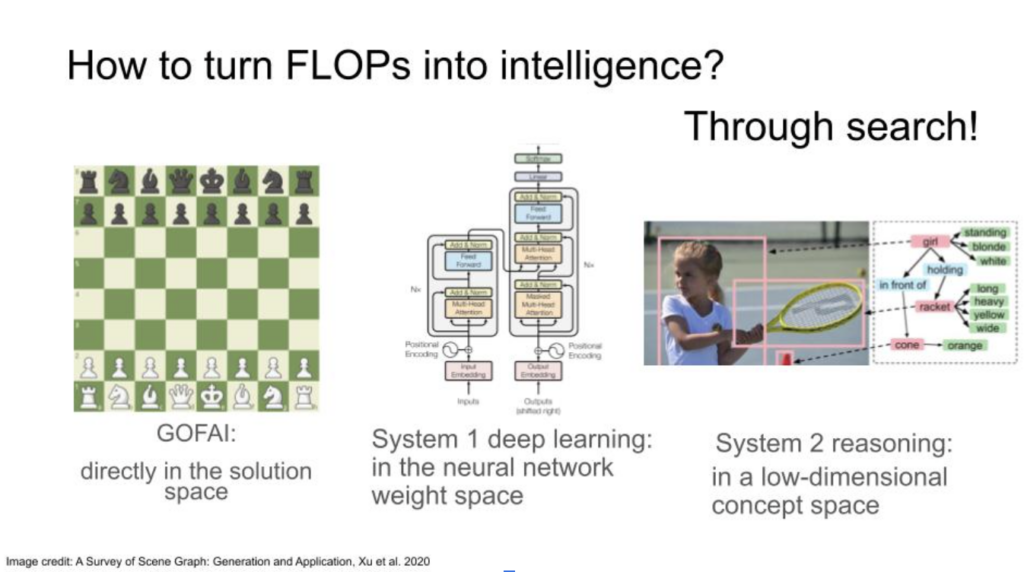
The key to turning flops into intelligence lies in the ability to perform effective search processes. Intelligence, at its core, represents the capability to search for reasons, explanations, and sequences of actions. For instance, when devising a move in chess, one examines multiple possible outcomes and consequences—a form of search. This concept is not exclusive to games like chess but applies to any context requiring logical reasoning.
Traditional AI—often referred to in research communities as “good old fashioned AI” or “GOFAI”—performed these search processes directly in the solution space. It’s analogous to playing chess by examining each possible move directly. However, the efficiency of these processes was often lacking, which leads us to the development of modern methods.
The fundamental challenge we face in computational problem-solving, such as in a game of chess, is that directly searching the solution space for our next move can be prohibitively expensive, even when we try to exhaustively simulate all possibilities. This issue escalates when we extend it to complex domains like language processing, planning, or autonomous driving.
Today, deep learning has provided us with an effective alternative. Although deep learning is still a form of search, we are now exploring in the space of neural network weights, rather than directly in the solution space. Training a neural network essentially involves moving within a vast space of billions of parameters and attempting to locate an optimal combination. While this might seem like trading one immense search space for another, the introduction of optimization techniques such as gradient descent has made this search more purposeful and guided.
However, when humans think, we are not merely searching in the weight space. We are also probing what we might call the ‘concept space.’ This space consists of explanations and abstract representations; we formulate narratives around the entities involved and their relationships. Therefore, the next frontier of AI research, which we are currently exploring at Mila with Yoshua, involves constructing models capable of searching this ‘concept space.’
Building on the foundations of large-scale, deep learning neural networks, we aim to create models that can autonomously discover concepts and their relationships. This approach harkens back to the era of ‘good old fashioned AI’ where researchers would manually construct knowledge graphs and scene graphs. However, the major difference lies in the model’s ability to learn these representations organically, without explicit instruction.
We believe that this new dimension of search will lead to better ‘sample complexity,’ meaning that the models would require less training data. Moreover, because these models have a more structured, lower-dimensional concept space, they are expected to generalize much better to unseen data. Essentially, after seeing a few examples, these models would ideally know how to answer the same type of question on unseen examples.
Aparna: Thank you, Edward. Your insights have been both practical, pertaining to present technologies that our founders can utilize, as well as forward-looking, providing a glimpse into the ongoing research that is shaping the future of artificial intelligence. Thank you so much for taking us through your inventions and making this information so accessible to our audience.
Join me for the next Perspectives in AI fireside, hosted monthly at Pear for up to date technical deep dives on emerging areas in Artificial Intelligence. You can find an archive of previous talks here.