
Founders often ask us what kind of AI company they should start and how to start something long lasting?
Our thesis on AI and ML at Pear is grounded in the belief that advances in these fields are game-changing, paralleling the advent of the web in the late ’90s. We foresee that AI and ML will revolutionize both enterprise software and consumer applications. A particular area of interest is generative AI, which we believe holds the potential to increase productivity across many verticals by five to ten times. Pear has been investing in AI/ML for many years, and in generative AI more recently. That said, there’s still a lot of noise in this space, which is part of the reason we host a “Perspectives in AI” technical fireside series to cut through the hype, and connect the dots between research and product.
Much of the progress in Generative AI began with the breakthrough invention of the transformer in 2017 by researchers at Google. This innovation combined with the at-scale availability of GPUs in public clouds paved the way for large language models and neural networks to be trained on massive datasets. When these models reach a size of 6 billion parameters or more, they exhibit emergent behavior, performing seemingly intelligent tasks. Coupled with training on mixed domain data such as the pile dataset, these models become general-purpose, capable of various tasks including code generation, summarization, and other text-based functions. These are still statistical models with non zero rates of error or hallucination but they are nevertheless a breakthrough in the emergence of intelligent output.
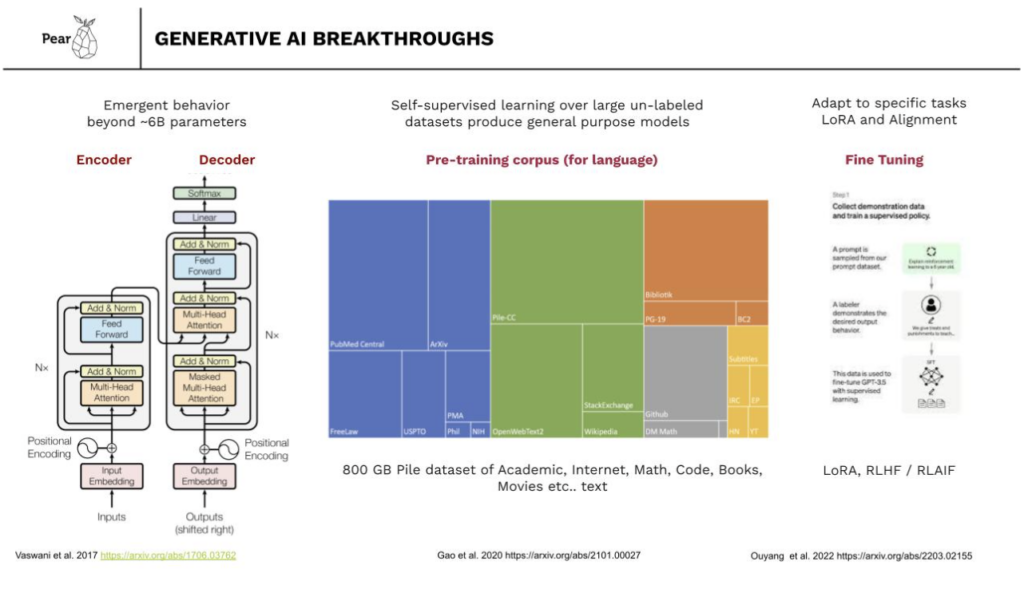
Another related advancement is the ability to employ these large foundational models and customize them through transfer learning to suit specific tasks. Many different techniques are employed here, but one that is particularly efficient and relevant to commercial applications is fine tuning using Low Rank Adaptation. LoRA enables the creation of multiple smaller fine tuned models that can be optimized for a particular purpose or character, and function in conjunction with the larger model to provide a more effective and efficient output. Finally one of the most important recent innovations that allowed the broad public release of LLMs has been RLHF and RLAIF to create models that are aligned with company-specific values or use-case-specific needs. Collectively these breakthroughs have catalyzed the capabilities we’re observing today, signifying a rapid acceleration in the field.
Text is, of course, the most prevalent domain for AI models, but significant progress has been made in areas like video, image, vision, and even biological systems. This year, in particular, marks substantial advancements in generative AI, including speech and multimodal models. The interplay between open-source models (represented in white in the figure below) and commercial closed models is worth noting. Open-source models are becoming as capable as their closed counterparts, and the cost of training these models is decreasing.

Our thesis on AI breaks down into three parts: 1. applications along with foundation / fine tuned models, 2. data, tooling and orchestration and 3. infrastructure which includes cloud services software and hardware. At the top layer we believe the applications that will win in the generative AI ecosystem will be architected using ensembles of task specific models that are fine tuned using proprietary data (specific to each vertical, use case, and user experience),along with retrieval augmentation. OrbyAI is an early innovation leader in this area of AI driven workflow automation. It is extremely relevant and useful for enterprises.We also believe that tooling for integrating, orchestrating, evaluating/testing, securing and continuously deploying model based applications is a separate investment category. Nightfall understands this problem well and is focused on tooling for data privacy and security of composite AI applications. Finally, we see great opportunity in infrastructure advances at the software, hardware and cloud services layer for efficient training and inference at larger scales across different device form factors. There are many diverse areas within infrastructure from specialized AI chips to high bandwidth networking to novel model architectures. Quadric is a Pear portfolio company working in this space.
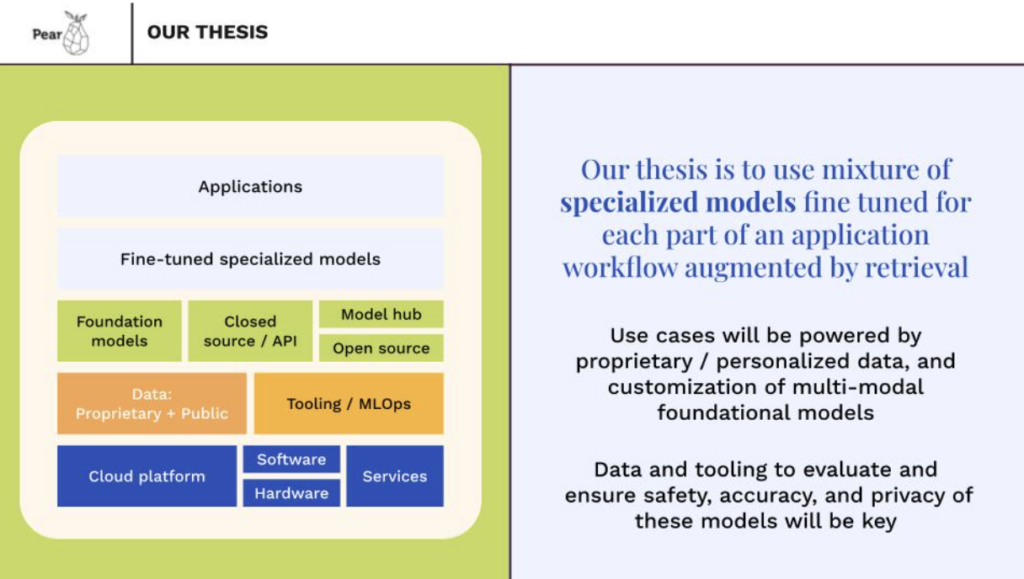
Successful entrepreneurs will focus on using a mixture of specialized models fine tuned using proprietary or personal data, to a specific workflow along with retrieval augmentation and prompt engineering techniques to build reliable, intelligent applications that automate previously cumbersome processes. For most enterprise use cases the models will be augmented by a retrieval system to ensure a fact basis as well as explainability of results. We discuss open source models in this context because these are more widely accessible for sophisticated fine tuning, and they can be used in private environments for access to proprietary data. Also they are often available in many sizes enabling applications with more local and edge based form factors. Open source models are becoming progressively more capable with new releases such as Llama2 and the cost of running these models is also going down.

When we talk about moats, we think it’s extremely important that founders have compelling insight regarding the specific problem they are solving and experience with go-to market for their use case. This is important for any start up, but in AI access to proprietary data and skilled human expertise are even more important for building a moat. Per our thesis, fine tuning models for specific use cases using proprietary data and knowledge is key for building a moat. Startups that solve major open problems in AI such as providing scalable mechanisms for data integration, data privacy, improved accuracy, safety, and compliance for composite AI applications can also have an inherent moat.
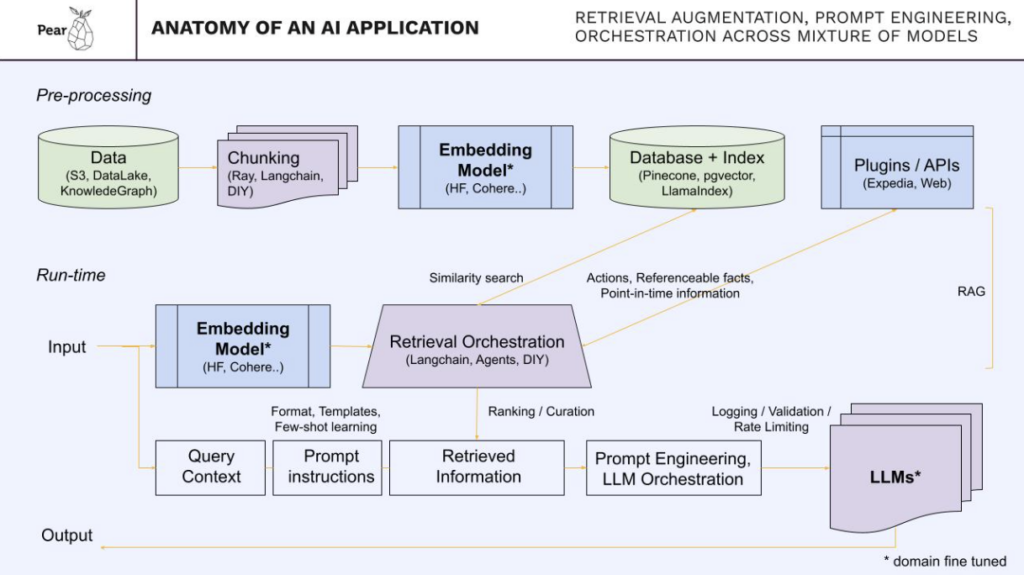
A high level architecture or “Anatomy of a modern AI application” often involves preprocessing data, chunking it and then using an embedding model, putting those embeddings into a database, creating an index or multiple indices and then at runtime, creating embeddings out of the input and then essentially searching against the index with appropriate curation and ranking of results. AI applications pull in other sources of information and data as needed using traditional APIs and databases, for example for real time or point in time information, referenceable facts or to take actions. This is referred to as RAG or retrieval augmented generation. Most applications require prompt engineering for many purposes including formatting the model input/output, adding specific instructions, templates, and providing examples to the LLM. The retrieved information combined with prompt engineering is fed to an LLM or a set of LLMs/ mixture of large language models, and the synthesized output is communicated back to the user. Input and output validation, rate limiting and other privacy and security mechanisms are inserted at the input and output of LLMs. I’ve bolded the Embedding model, and the LLMs, because those benefit from fine tuning.
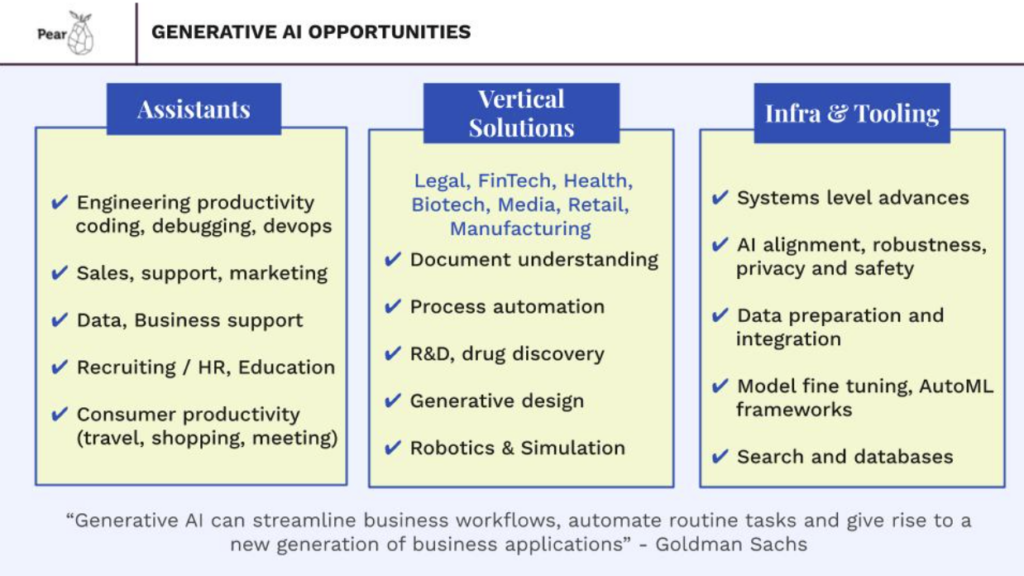
In terms of applications that are ripe for disruption from generative AI, there are many. First of all, the idea of personalized “AI Assistants” for consumers broadly will likely represent the most powerful shift in the way we use computing in the future. Shorter term we expect specific “assistants” for major functional areas. In particular software development and the engineering function overall will likely be the first adopter of AI assistants for everything from code development to application troubleshooting. It may be best to think of this area in terms of the jobs to be done (e.g., SWE, Test/QA, SRE etc), while some of these are using generativeAI today, there is much more potential still. A second closely related opportunity area is data and analytics which is dramatically simplified by generative AI. Additional rich areas for building generative AI applications are all parts of CRM systems for marketing, sales, and support, as well as recruiting, learning/education and HR functions. Sellscale is one of our latest portfolio companies accelerating sales and marketing through generative AI. In all of these areas we think it is important for startups to build deep moats using proprietary data and fine tuning domain specific models.
We also clearly see applications in healthcare, legal, manufacturing, finance, insurance, biotech and pharma verticals all of which have significant workflows that are rich in text, images or numbers that can benefit greatly from artificial intelligence. Federato is a Pear portfolio company that is applying AI to risk optimization for the insurance industry while VizAI uses AI to connect care teams earlier, increase speed of diagnosis and improve clinical care pathways starting with Stroke detection. These verticals are also regulated and have a higher bar for accuracy, privacy and explainability all of which provide great opportunities for differentiation and moats. Separately, media, retail and gaming verticals offer emerging opportunities for generative AI that have more of a consumer / creator goto market. The scale and monetization profile of this type of vertical may be different from highly regulated verticals. We also see applications in Climate, Energy and Robotics longer term.
Last but not least, at Pear we believe some of the biggest winners from generative AI will be at the infrastructure and tooling layers of the stack. Startups solving problems in systems to make inference and training more efficient, pushing the envelope with context lengths, enabling data integration, model alignment, privacy, and safety and building platforms for model evaluation, iteration and deployment should see a rapidly growing market.
We are very excited to partner with the entrepreneurs who are building the future of these workflows. AI, with its recent advances, offers a new capability that is going to force a rethinking of how we work and what parts can be done more intelligently. We can’t wait to see what pain points you will address!