Here at Pear, we specialize in backing companies at the pre-seed and seed stages, and we work closely with our founders to bring their breakthrough ideas, technologies, and businesses from 0 to 1. Because we are passionate about the journey from bench to business, we created this series to share stories from leaders in biotech and academia and to highlight the real-world impact of emerging life sciences research and technologies.This post was written by Pear PhD Fellow Sarah Jones.
Today, we’re excited to share insights from our discussion with Dr. Ivan Dimov, CEO and co-founder of Orca Bio. Ivan has co-founded three high-tech companies and two R&D centers, and he is now working to make next-generation cell therapies safer and more efficacious at Orca.
More about Ivan:
Ivan earned a Ph.D. in Applied Biophysics from Dublin City University and has since worked as a postdoc at UC Berkeley and as a visiting instructor and senior scientist at Stanford. His passion for translating his work and his tech-heavy background have made him an expert in electronics and bio-microelectromechanical systems (bio-MEMS) and have helped him to work on numerous projects and companies including Blobcode Technologies, Lucira Health, and Orca Bio.
If you prefer listening, here’s a link to the recording!
Insight #1: Instead of building a technology and then searching for the right application, it’s much more efficient to identify the right problem prior to creating a solution.
There are many approaches to starting a company and making new, impactful discoveries. As someone with a strong tech and engineering background, Ivan was trained to find and create interesting, powerful new technologies and go hunting for applications; he made hammers and went searching for nails.
However, when working with Dr. Irv Weissman at Stanford as a postdoc, Ivan learned to do things a little differently.
Though Ivan’s background was primarily in applied biophysics and bioengineering, the Weissman lab’s focus was medicine and biomedical research. Ivan acknowledged that when you work in medicine, you are exposed to an over-abundance of problems, and in this environment, Ivan learned that the most effective solutions are those that are tailor-made to fulfill a clearly defined need.
Working with physicians was a huge change in mentality for me…you’re seeing suffering everywhere and you have all these problems, and you sort of have to figure out, okay, which problem do you want to focus on, and what’s the best solution or technology you can come up with for that problem? I think that’s probably the better way of doing innovation…rather than trying to squeeze in some technology that was thought of in a different context and trying to make it work.
One such problem was related to the poor outcomes of stem cell transplants, a procedure in which a donor’s stem cells are harvested and administered to a recipient. Ivan explained that there wasn’t a way to sort out the good cells from the bad and ensure that the recipient was only receiving cells that would therapeutically benefit them and minimize unwanted side effects.
The idea of creating precise and well-defined stem cell therapies would become the central theme of Ivan’s work at Stanford and later of Orca Bio.
Insight #2: Academia is great for exploring, learning, and making mistakes. However, industry is where you can iron out the more mundane details of company creation and focus on impact and real-world use cases.
Having started three companies–Blobcode Technologies, Lucira Health, and Orca Bio–Ivan has extensive experience in taking ideas from academia to industry.
Lucira Health, a diagnostics company that has since been acquired by Pfizer, was spun out of Ivan’s work at Berkeley. The goal was to miniaturize a microfluidic chip that could be utilized as an at-home diagnostic. Notably, the company received approval from the FDA for their at-home COVID test that could read out results in about 30 minutes.
While at Berkeley, Ivan spent time fine-tuning the idea and conducting proof-of-concept experiments for the chip. However, it became apparent that this academic setting wasn’t necessarily conducive to the less thrilling aspects of the project. Spinning out and starting Lucira allowed the team to more efficiently work on the ‘mundane’ details like reproducibility and clinical trial design.
[Academia is a safe place where] there’s a lot of openness to trying out new things… and the greatest thing about it is that you can try it and you can make a mistake and that’s okay. You can come up with a better alternative.
While Ivan agrees that academic labs are a great place for ideation and company incubation, it’s important to be vigilant and humble enough to realize when it’s time to take the next step. Industry and academia each have their respective strengths, and Ivan learned that both were crucial to the growth and future success of his companies.
Insight #3: Stem cell therapies don’t have to be so risky: by cherry-picking the cells that a patient receives, long-term outcomes can be significantly improved.
In leukemia, cells in the bone marrow and lymphatic system become cancerous and rapidly multiply. To treat this type of malignancy, patients often go through multiple rounds of chemotherapy, radiation, or targeted immunotherapy and may receive an allogeneic stem cell transplant.
Essentially, a conventional allogeneic transplant begins when the patient receives chemotherapy and/or radiation to wipe out all of the cancerous blood cells together with the patient’s healthy blood and immune cells. Once the cancer can no longer be detected, stem cells from the bone marrow of a healthy donor will be administered. These new cells can multiply and grow into mature, functioning blood and immune cells.
For some patients, this treatment is curative and wipes out any trace of cancer from their systems. However, even after chemotherapy and radiation, some cancer cells may go undetected and cause a patient to relapse.
The problem with cancer is that if you leave even a little bit of it behind, even a single cell that hides and survives, it has the potential to reinitiate and restart your cancer from scratch… When you get into full remission–meaning we can’t measure any more cancer in you–it just means that our tests aren’t sensitive enough to see if it’s there or not there.
Once the stem cell transplant is complete, it takes a couple of weeks for the new immune and blood systems to get up and running. The hope is that these new immune cells can wipe out any remaining cancer cells that may be hiding out.
In addition to the potential for relapse, patients frequently develop either acute or chronic Graft-vs-host-disease (GVHD), complications in which the new immune cells from the donor start to attack the patient’s (host’s) own cells and tissues. GVHD can affect many parts of the body and can even lead to death.
In a standard transplant, your chances of surviving for twelve months free of relapse or free from GVHD is somewhere around 30-40%. With Orca Bio… we can get rates somewhere between 70-80% ideal survival rates.
So how do they do it? Ivan’s goal at Orca Bio is to revolutionize the cell therapy space by creating a high-precision cell therapy that gives patients only the most efficacious donor cells.
Orca’s unique platform identifies and sorts for donor cells that have the highest therapeutic benefit. By removing cells that either harm or don’t help the patient, the patient’s chances for relapse or developing GVHD are dramatically reduced.
With what they call their ‘designer immune system,’ Orca’s approach aims to help patients recover more quickly, prevent relapse, and be safe enough for older or sicker patients who can’t receive traditional stem cell transplants.
Insight #4: To solve the problems of current allogeneic stem cell transplants, you have to balance killing the remaining cancer cells with protecting the patient’s own tissues and cells.
When designing an immune system to infuse into patients with blood cancer, it can be difficult to kill cancer cells without harming other cells in the patient’s body.
In a healthy immune system, cells called regulatory T cells (T-regs) monitor and regulate what effector T cells are doing. Such effector T cells can help promote inflammation and eliminate cancer cells. However, when a patient has cancer, there is an imbalance between these two cell types, and the immune cells don’t effectively kill the cancer cells.
These types of cells are often involved in autoimmune disorders and can also play a role in the development of acute GVHD shortly following the stem cell transplant or in chronic GVHD, long after the treatment has concluded.
Orca Bio’s first product, Orca-T, helps to restore balance in the immune system by first bringing stem cells and T-reg cells into the patient’s body to let them set up the immunoregulatory environment. Once the T-regs and stem cells have had a chance to settle in and begin restoring the patient’s immune and blood systems, conventional T cells with cancer-killing capabilities are administered.
Orca-T has reached Phase III clinical trials for indications such as acute myeloid leukemia (AML), myelodysplastic syndrome (MDS), acute lymphoid leukemia (ALL), and mixed-phenotype acute leukemia (MPAL) in patients with matched donors who are younger than 65. Matched donors are those that share the same human leukocyte antigen (HLA) profile, and this means that these cells are less likely to be identified as intruders in the patient’s body, thus reducing the risk for GVHD.
Patients receiving Orca-T first receive chemotherapy and/or radiation to target cancer cells and suppress their immune systems. The first dose of Orca-T is an infusion of stem cells that regenerate the blood and T-regs that help set the immune landscape. Two days later, the patient receives an infusion of conventional T cells that can begin to attack any remaining cancer cells.
What’s amazing about this approach is that by doing that, you’re not turning off the effector T cells from destroying the cancer. You’re just turning off alloreactivity in the key organ sites where you might create GVHD, but you’re still keeping it on for wherever the cancer might be.
Moving forward, the company is continuing its work on Orca-T by expanding the age range of patients who can be treated with the drug.
The pipeline also includes next-gen cell therapy treatment, Orca-Q.
To solve the problem of limited matched donor availability, Orca-Q is a high-precision cell therapy that has been tailored for haploidentical, or half-matched donors. These donors are typically parents, children, or siblings and can be much easier to find. However, the risk for GVHD increases with a half-matched donor compared to a fully matched donor.
Orca-Q has so far shown positive results in Phase I in oncological indications and is being investigated for autoimmune and hematological indications, as well.
Insight #5: Sometimes science is personal: reflecting on Orca’s journey, Ivan and his team have a deep understanding of how their work can change lives.
Having treated more than 400 patients so far, Orca has seen firsthand how patients can benefit from their novel stem cell transplants.
In particular, patients who are too old or too sick for traditional transplants now have a fighting chance.
One of the most incredible stories was about my co-founder’s [Nate Fernhoff’s] father-in-law. He was 71 years old when he was diagnosed with myelodysplastic syndrome. He had an aggressive variant of the disease…however, physicians feel very skittish about treating folks at that age with a myeloablative allogeneic bone marrow transplant, so they’re offering a reduced protocol [with a much worse chance of controlling the cancer]. We started looking for clinical trials, anything that would cover folks of that age.
Dr. Fernhoff’s father–in-law, Mikhail Rubin, was diagnosed with a rare form of blood cancer and found that his options for treatment were extremely limited. The most successful and aggressive forms of treatment were offered only to younger patients.
Meanwhile, Orca’s clinical trials had so far proven to be safe and effective. The Orca team sprang into action and started working to convince physicians and the FDA to allow them to treat patients older than 65 and expand the enrollment criteria for the trial.
Ivan noted that this exclusion of the most dire patients stems from the industry’s hesitancy to add further risk to clinical trials.
In April of 2021, we were given the permissions, and were able to treat him. It’s been a phenomenal recovery. He recovered much faster than any of his younger counterparts even though a lot of physicians thought it would take months in the hospital for him to get out. Yet, in the first year after, he started riding his mountain bike and did 3,000 miles on his bike.
Not only is Mr. Rubin back to biking, he has also been cancer-free and GVHD-free for three years now.
While science tends to be objective in nature, personal connections and motivations help drive the mission and make work like this possible.
Today, raising capital is far more challenging than it was a few years ago. There are no fake Series A’s— most businesses require a good foundation, strong unit economics and growth as well as a moat to get there. We talked to three alums from our 2019 PearX cohort to hear how they raised capital this year: Andrew Powell from Learn to Win, John Dean from Windborne, and Parth Shah from Polimorphic.
PearX is our exclusive, small batch, 14 week program. 90% of our companies go on to raise a successful seed round from top tier investors. PearX alumni companies include Affinity (S14), Viz.ai (S16), Cardless (S19), Federato (S20), Valar Labs (S21), and more.
Learn to Win is a training platform that empowers companies to design, deliver and assess the impact of employee training. They serve customers across commercial and government markets in primarily high-intensity training situations. Learn to Win closed a $30M Series A round in June 2024, led by the Westly Group and joined by Pear and Norwest Venture Partners.
Windborne is a full-stack, vertically-integrated weather intelligence company. They operate the largest balloon constellation on the planet, running a base weather forecast with the data they collect from those balloons. Windborne raised a $15M Series A round, led by Khosla Ventures and joined by existing investors Footwork VC, Pear VC, and Convective Capital.
Polimorphic digitizes government operations, helping governments provide a great customer service experience to their residents and businesses. AI-powered search and voice software empowers municipal employees with saved time and resources, while delivering a modern service experience that delights residents. Polimorphic raised a $5.6M round, led by M13 with participation from existing investors Shine Capital and Pear VC.
It’s been five years since you went through PearX. What did you learn from this accelerator program that still provides you value today?
Windborne: Mar played a big role in us even founding a company. Our very first check came from Pear Dorm. Fundamentally, we learned how to be entrepreneurs, and every connection in those early days came through Pear.
Polimorphic: One of the most interesting pieces of it was thinking about how venture-scale businesses are different. When we came into PearX, we didn’t even have a company yet, and we hadn’t even landed on this iteration of Polimorphic.
It takes time to find product market fit. PearX supported us during the exploration phase— you need to be nimble, trying stuff until you find what clicks. COVID interfered with a lot of our plans to work with the government in the early days, and recently we’ve really found product market fit.
Where has Pear helped your company the most?
Learn to Win: Hiring and fundraising. Pear has helped hire our first few engineers and our first few executives.
Windborne: Especially in the last year and a half, Pear’s talent team has been insanely helpful with hiring. Beyond that, they offer general advice on people ops: compensation, policies, equity splits— everything around managing people. We use Ashby for free through Pear. It’s very convenient to have a VC you trust a lot to help you get set up with these things.
One of the single biggest challenges that all companies face is talent. If you’re good at talent, you’ll win. If you’re bad at talent, you’ll lose. To have a VC that stands out in talent is incredibly valuable.
What’s a piece of advice for founders trying to raise a Series A?
Learn to Win: When it comes to Series A, there’s certainly more of an emphasis on metrics and scalability. Talk to other folks in your sector and ask them what key metric they were gunning for, what pieces of evidence they gave to investors to help them understand your business opportunity.
At seed, we proved we could build a great product and deliver great value for customers. What needs to change is an engine that can repeatedly do that at scale.
Windborne: My biggest piece of advice is to be wary of advice that isn’t relevant to you. Think about where you want advice and where you don’t. For us, we disregard a lot of things people tell us when it comes to engineering and manufacturing when they don’t understand the way we run our business. You’re not going to win by only following commercial industry wisdom.
As the rounds progress, things definitely get harder— riskier, scarier, more challenging. But they also get so much more fun.
What sets Pear apart from other venture firms?
Polimorphic: Pear’s willingness to be involved. We were pre-idea, pre-company when we met Pear; we just knew we were interested in the political realm. Pear stuck with us as we started to explore government. Their ethos of investing in people manifested in sticking with us through a few different iterations.
Learn to Win: Pear is an expert at early stage— even what comes before it. We were still students at Stanford working out of our dorm room, and Pejman and Mar were some of the first people to believe in the potential of our business. In the early days, there’s so many people that could point out a million reasons why your startup will fail. Pear believed in the one reason out of a million and helped us understand how to dig into it.
What are your goals for the next phase of your company?
Learn to Win: We’re trying to ramp up our defense business and grow aggressively across the board. We’re just scratching the surface, and we’re excited to see what we can do with this new capital.
Windborne: We want to scale up data collection operations. We’re launching around 100 balloons a month, and we want to be doing a few hundred a month. By the next round, we want to be doing over 10 million a year in revenue. And more importantly, we want to be collecting more in situ weather observations than the rest of the world combined.
Polimorphic: We’re on path to having 100 government clients, which is a big milestone. We started with cities and counties and are about to do our first state-level deal. That’s the next big phase: acquiring more customers, delivering a new paradigm for governments to provide customer service to their residents.
All three of these companies were in the same PearX S19 cohort. At the time, these startups were all just a few founders and an idea. It’s amazing to see their growth and to see them collectively raise $50M+ over the last quarter. Read more about PearX here. Applications for PearX W25 open on August 20th.
Here at Pear, we specialize in backing companies at the pre-seed and seed stages, and we work closely with our founders to bring their breakthrough ideas, technologies, and businesses from 0 to 1. Because we are passionate about the journey from bench to business, we created this series to share stories from leaders in biotech and academia and to highlight the real-world impact of emerging life sciences research and technologies. Read more about Pear’s approach in biotech here.
In this review, we look back at the top 50 biotech companies of the past 15 years. This post was written by Pear Partner Eddie and Pear PhD Fellows Alan Tung, Ami Thakrar, and Gary Li.
Introduction:
Life sciences companies have the unique opportunity to transform scientific discoveries into drugs, diagnostics, and technologies that can substantially improve people’s well being. In the past decade and a half, we’ve seen dramatic progress in the sector: the approval of several highly impactful drugs (e.g., COVID vaccines, checkpoint inhibitors, GLP-1 agonists), the rapid maturation of emerging therapeutic modalities (gene therapies, cell therapies, gene editing, protein degraders, ADCs, radiopharma, etc.), and the increasing adoption of technologies used in biology research and in diagnostics (NGS, epigenetics, transcriptomics, proteomics, single cell biology, spatial biology, organoids, etc.).
We were motivated to highlight 50 biotech startups that have recently generated tremendous value for patients, for investors, and for the sector. Given the long development timelines involved in biotech, we focused this review on companies founded within the past 15 years, and we limited the scope to life sciences startups developing therapeutics, diagnostics, or tools.
As an admittedly imperfect indicator for the value generated, the top 50 startups were selected and ranked based on the valuations actually realized during the period via an exit by acquisition or a public financing. For the companies that went public and remained independent, we looked at the maximum of either the market cap at IPO or the market cap achieved at the end of the period.
To get a better sense of what these companies look like, we surveyed these “biotech behemoths” below with respect to their key products, the profiles of the founding CEOs and scientific founders, the origins of their lead programs and technologies, the founding location, the time to an initial exit, and several other characteristics of interest.
Methods:
Using Pitchbook, we screened for therapeutics, diagnostics, and life sciences tools companies founded between Jan 1, 2009 – Dec 31, 2023 in the US, Canada, and Europe. The top 50 companies were selected based upon the maximum of: the upfront or guaranteed value realized at the time of acquisition, or the company market capitalization either at IPO or at the end of the period on Dec. 31, 2023.
This approach means that a few companies were included that had a very high valuation at IPO, but ultimately did not retain this value (e.g., because of a subsequent disappointing clinical trial outcome). Given that different investors have different strategies when it comes to unwinding their positions in public companies, our intent in using this particular criterion was to prioritize those companies throughout the period that were likely to have been most meaningful in terms of financial value returned back to investors.
Spinouts from major companies were generally excluded; notable exclusions include Cerevel Therapeutics, spun out of Pfizer in 2018 and acquired by AbbVie in 2023 for $8.7B, and Viela Bio, spun out of AstraZeneca also in 2018 and bought by Horizon for $3B in 2021. However, we decided to include Grail, spun out of Illumina to work on a product application quite distinct from Illumina’s main NGS tool platform, as well as Telavant and Immunovant, spinouts of Roivant – which is itself a startup.
A handful of companies were identified and added to the list based on cross referencing Crunchbase, Pitchbook’s public company screener, and relevant biotech industry news sources and reports. Additional data pertaining to company and founder characteristics were obtained from company websites, press releases, SEC filings, available news sources, or where possible, primary research.
Constraints:
1) The valuation metric we applied for ranking is neither an intrinsic measure of value nor impact.
2) Many companies that ultimately generate tremendous benefits for patients or the industry get acquired or exit at an earlier stage at a lower value.
3) As noted above, some companies included in this ranking that were highly valued at the time of IPO or acquisition did not live up to this valuation due to clinical setbacks or commercial challenges.
4) We exclusively focused on the outliers in terms of success, and we did not run a comparison against companies that were not as successful. Accordingly, we would caution against any tendencies to form conclusions that suffer from survivorship bias.
5) Our data and results are limited by the available resources that we had access to as noted above. (Note: if we made any omissions or errors, please kindly let us know!)
6) The valuations were not adjusted for inflation.
Pear VC’s Biotech Behemoth rankings:
Product Impact
Among the behemoths, a whopping 46 (92%) were therapeutics companies, 3 (6%) were diagnostics companies, and 1 (2%) was a life sciences tools company. In the sections below, we survey some of their key products.
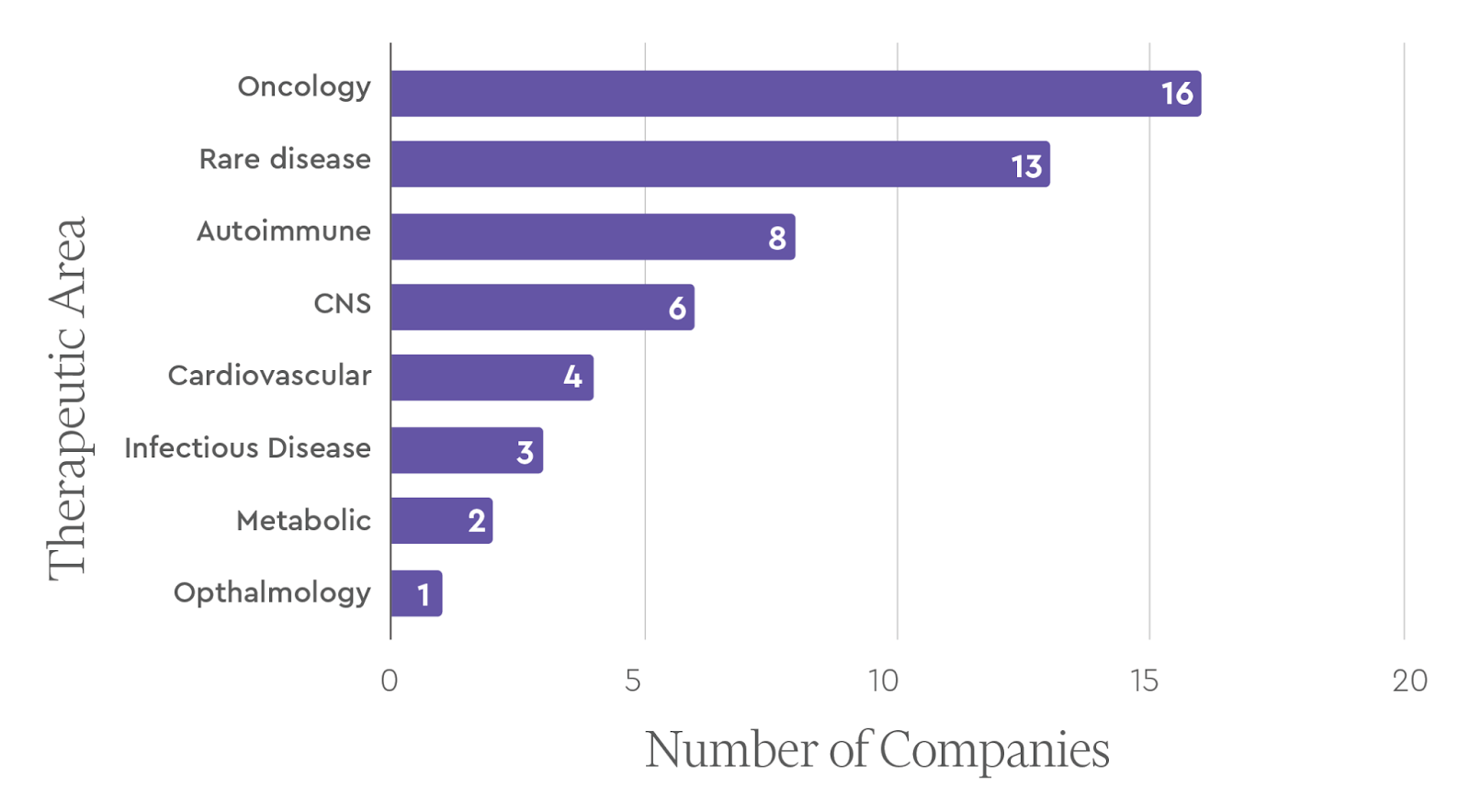
Therapeutics Companies – Indication Focus
The 46 therapeutics behemoths spanned all of the major indication areas including oncology, immunology, CNS diseases, and infectious diseases. Oncology was the most common lead therapeutic area (16 companies, 34.78%), followed by rare diseases (13 companies, 28.26%).
Current Clinical Stage of Therapeutics Behemoths (EOY 2023)
Among the top therapeutics companies, a majority (52%) achieved FDA approval for their lead drug programs by the end of 2023, with about a quarter reaching Phase 3 and the remainder in earlier clinical stages.
Snapshot of approved drugs by the top drug companies
We surveyed the approved drugs developed by the top therapeutics startups in our rankings. Company valuation was generally positively correlated with projected peak sales of the corresponding company’s approved drug.
Developer
Brand Name
Generic Name
Projected Peak Sales* ($B)
Therapeutic Area(s)
Commercial Lead
Approval Year(s)
1
Moderna
SpikeVax
Moderna COVID Vaccine
18.4B (2022)
Infectious Disease
Moderna
2020
2
MyoKardia
Camyzos
Mavacamten
2.3B (2030)
Cardiovascular
BMS
2022
3
Biohaven
Nurtec
Remigepant
2.8B (2030)
CNS
Pfizer
2020
4
Juno
Breyanzi
Lisocabtagene maraleucel
2B (2030)
Oncology
BMS/Celgene
2021
5
Kite
Yescarta
Axicabtagene ciloleucel
2.6B (2029)
Oncology
Gilead
2017
6
Roivant
Vtama
Tapinarof
0.41B (2032)
Autoimmune
Pfizer
2022
7
Avexis
Zolgensma
Onasemnogene abeparvovec-xioi
2.1B (2029)
Rare Disease
Novartis
2019
8
Receptos
Zeposia
Ozanimod
1.7B (2030)
CNS, Autoimmune
BMS
2020
9
Apellis
Empaveli, Syfovre
Pegcetacoplan
0.66 (2029, Empaveli), 2B (2029, Syfovre)
Rare Disease: Ophthalmology
Apellis
2021, 2023
10
Loxo
Vitrakvi, Retevmo
larotrectinib,selpercatinib
0.56 (2028, Vitrakvi), 0.76 (2029, Retevmo)
Oncology
Eli Lilly
2018, 2020
*Source: GlobalData
Platform or asset driven?
Among the top therapeutics companies, there were slightly more platform-driven companies (24 of 46) compared with asset-driven companies (22 of 46), but it is a fairly even split, especially considering that the definition of a platform is subject to a wide degree of interpretation. Here, we defined a platform as a key technology or discovery method that can lead to more than one asset. There are a few major themes among the platform-driven companies including those focused on cell therapies (Juno, Kite, Sana, Lyell, Arcellx); gene therapies (Avexis, Spark, Krystal Biotech, Audentes); CRISPR technology (CRISPR Therapeutics, Intellia); and computationally-driven drug discovery (Nimbus, Recursion).
Dx & Tools Products
There were just four diagnostics or tools companies out of the top 50 companies. Grail (founded in 2018) developed and launched the Galleri test for multi-cancer early detection. 10X Genomics (founded in 2012) commercialized instruments and reagents related to detailed sequencing and characterization of cellular genomes and transcriptomes. Foundation Medicine (founded in 2010) developed multiple tissue-based oncology genetic tests and was acquired by Roche in 2015. Guardant Health (founded in 2012) developed several liquid biopsy-based oncology tests for both early and advanced cancer.
Company
Founded
Key Products
Grail
2015
Galleri blood-based genomic test for early cancer screening
10X Genomics
2012
1. Chromium Single Cell: profile single cell gene expression 2. Visium Spatial: spatial whole transcriptome analysis 3. Xenium In Situ: detecting and imaging RNA
Foundation Medicine
2010
1. FoundationOne CDx: tissue-based companion diagnostic genomic test for solid tumors 2. FoundationOne Liquid CDx: blood-based companion diagnostic genomic test for solid tumors 3. FoundationOne Heme: comprehensive genomic profiling test for hematologic malignancies, sarcoma and certain solid tumors
Guardant Health
2012
1. Guardant360 and Guardant 360CDx: blood-based comprehensive genomic profiling test for therapy selection for solid tumors 2. Reveal: blood-based genomic test for minimal residual disease detection and recurrence monitoring 3. Shield: blood-based genomic test for colorectal cancer screening
Founding profiles:
Founding CEO Age
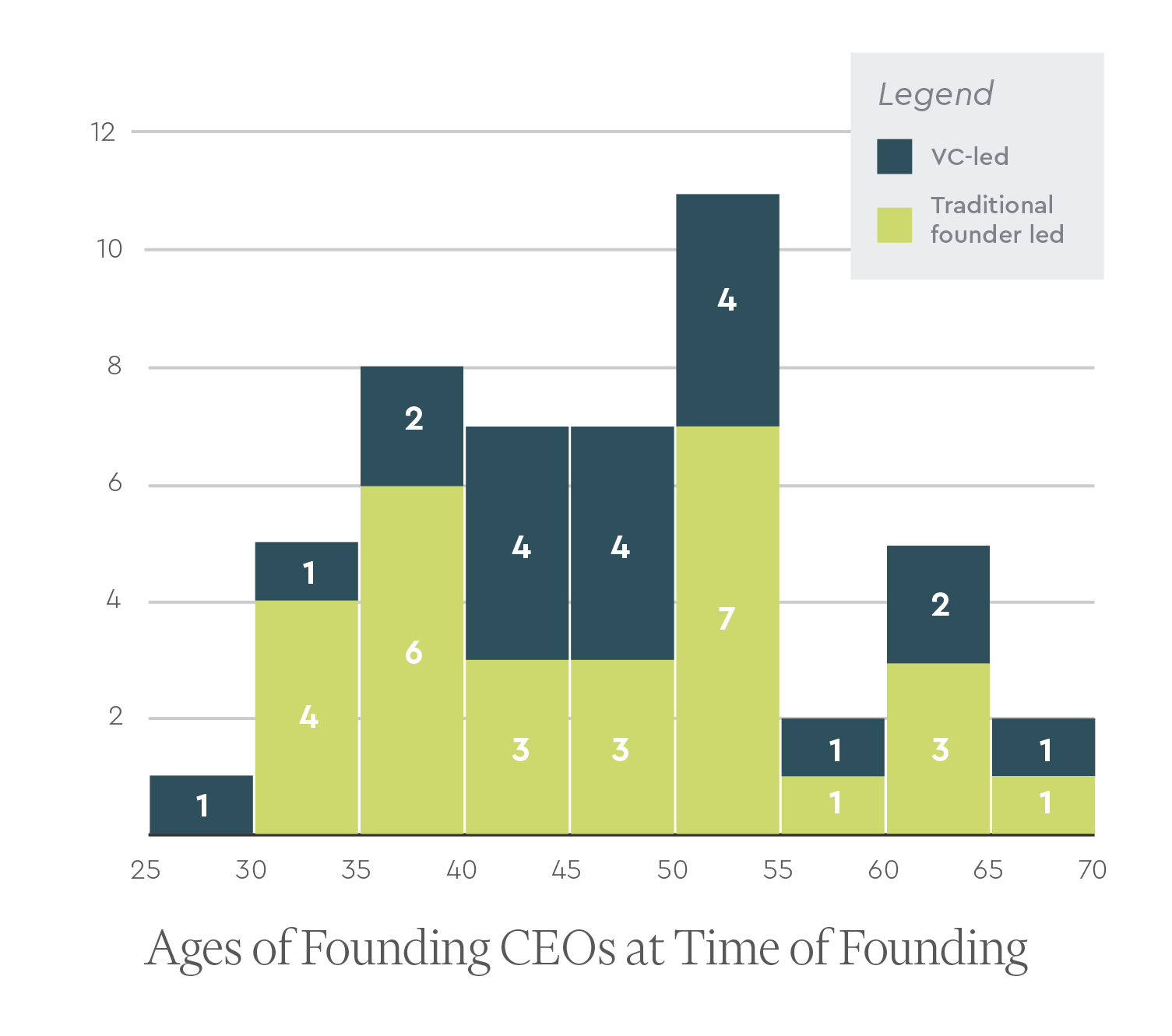
We were able to find data on the age of the founding CEO (+/- 1 year) at the time of founding for 47 of the 50 companies we profiled. We found that across these 47 companies, the average age of the founding CEO at the time of founding was ~46 years old (+/- 10 years). In the diagnostics/tools space (only 4 companies), the average age dropped to 38 (+/- 5 years old), but in therapeutics, the sector that dominates the rankings, the average age was 47 (+/- 10 years old).
We also found no substantial difference in the average age of the CEO at founding for companies that were or were not VC incubated. For companies that were VC-led, the average age of the CEO at founding was ~48 (+/- 10 years old). This is only slightly older than the founding CEOs of companies that were not VC-led, who were on average ~46 years old (+/- 10 years).
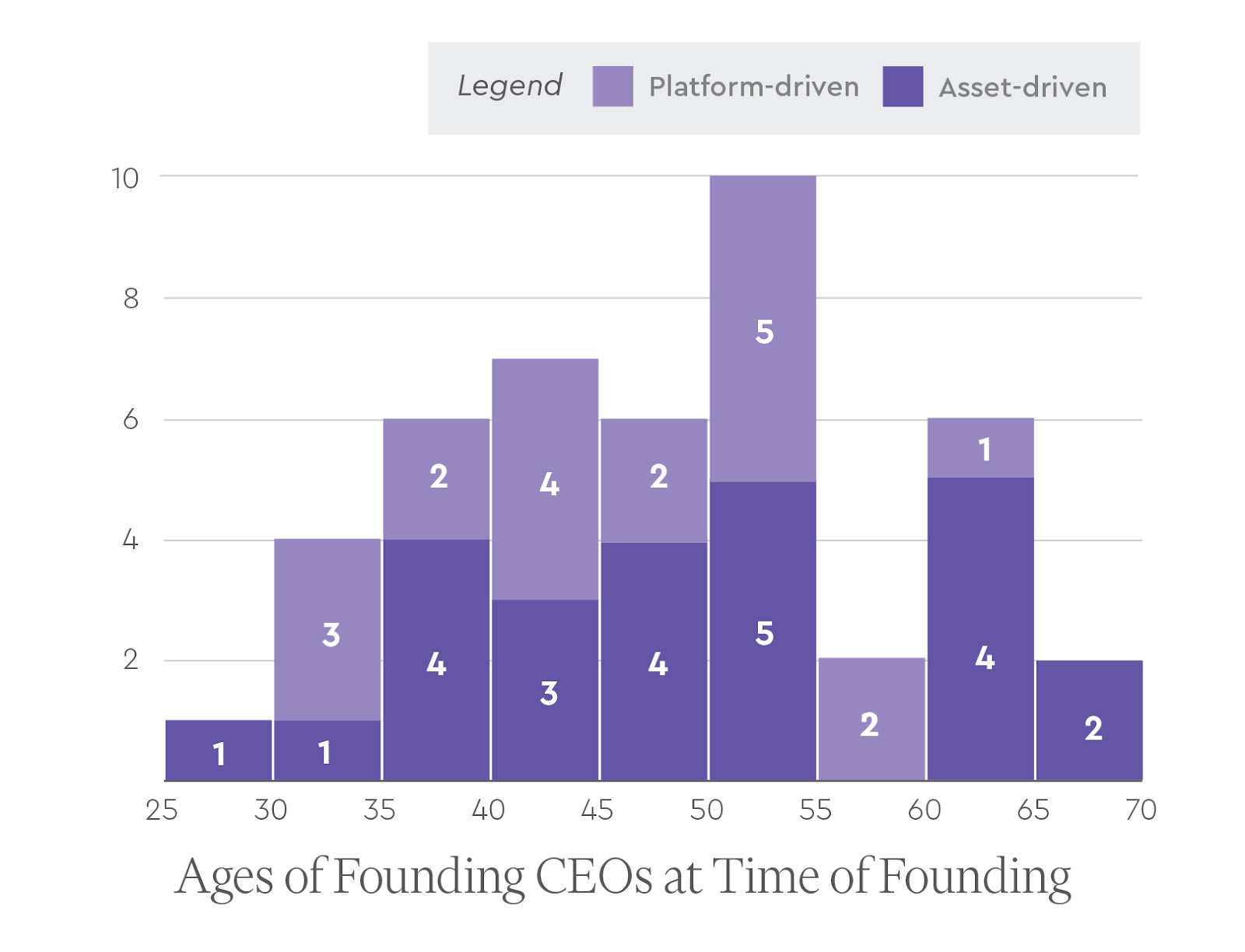
We sought to understand if the founding CEO ages were different for platform-driven vs. asset-driven companies. On average, the founding CEOs of platform-driven companies were slightly but not significantly younger at 46 years old (+/- 9 years) compared with those of asset-driven companies at 49 years old (+/- 11 years).
Experienced vs. First-Time CEOs
Interestingly, a little more than half (~53%) of the founding CEOs of the behemoths appeared to be first-time CEOs, and the remainder had previous CEO experience at one or more companies.
Did the Founding CEO Remain as the Exit CEO?
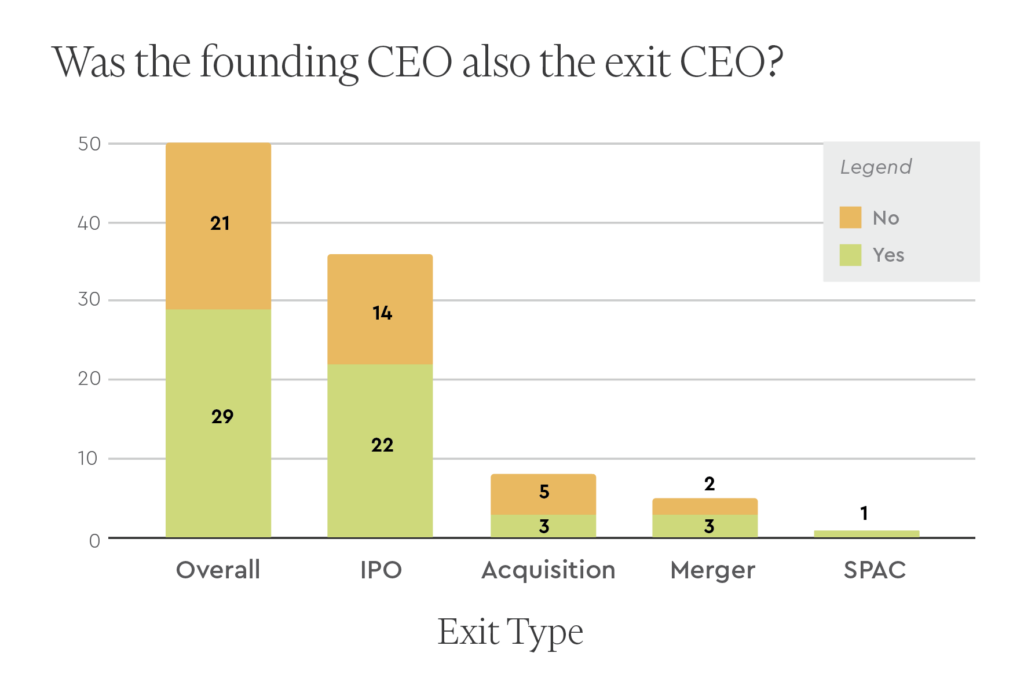
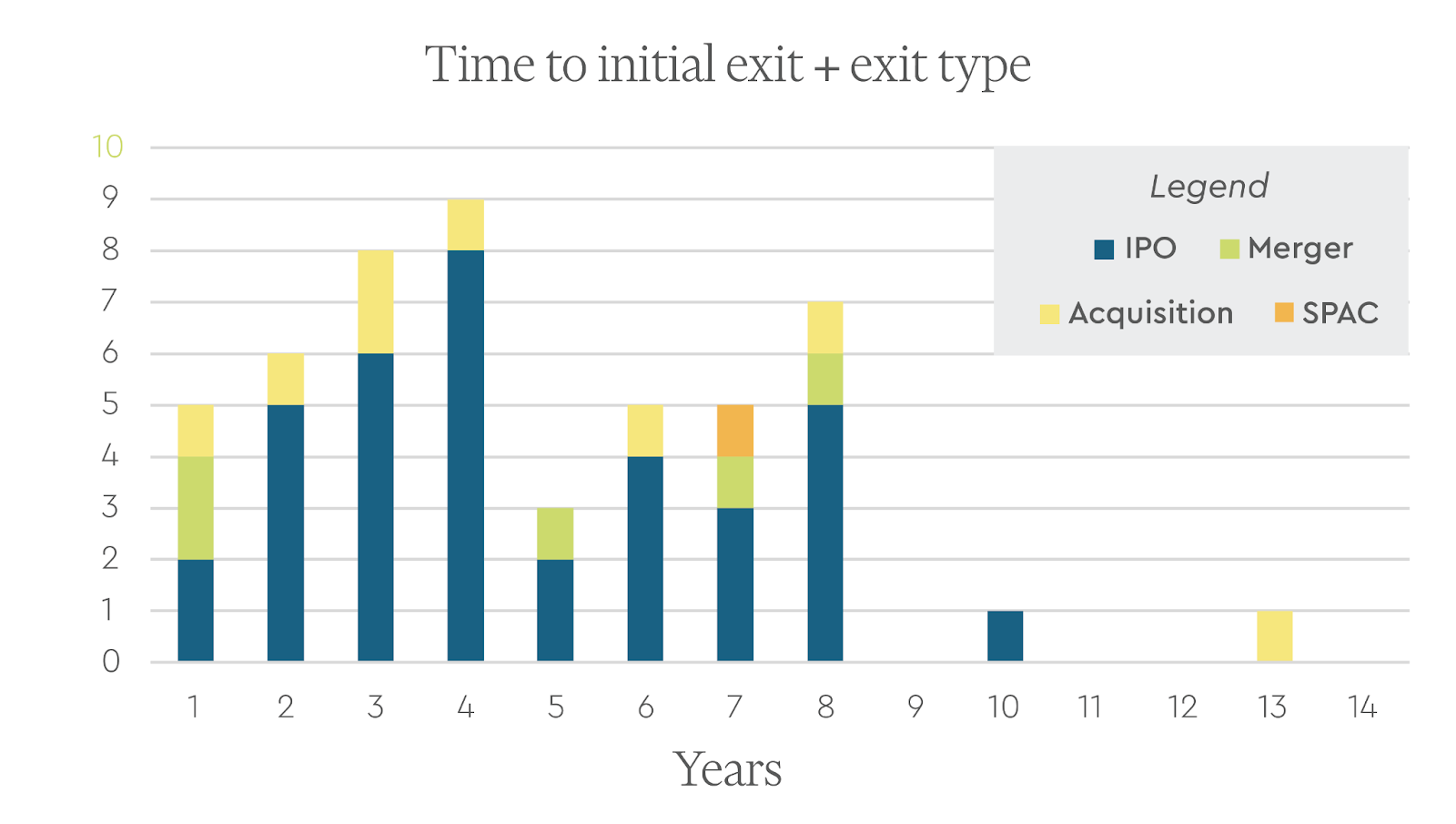
For 29 of the 50 behemoths, the founding CEO remained the CEO at least until the company’s initial exit (defined here as either a public financing event or an acquisition). This was more common in the case of IPOs (22 out of 36), mergers (3 out of 5), SPACs (1 out of 1), and less so for acquisitions (3 out of 8).
VC Incubation
One unique aspect of biotech venture capital is the strong tradition of hands-on company formation and incubation. To the extent we could determine based on publicly available information, the majority of the behemoths were not VC incubated, but a sizable minority (44%) were created and built by VC firms.
Among the 21 companies that were VC incubated, the firms represented most commonly were Third Rock (5 companies), ARCH (4), Atlas (3), Flagship (3), and Versant (3).
Founding CEO Equity Ownership
For those behemoths that went public, and that retained the founding CEO at IPO, we examined the founding CEO equity ownership just before the IPO. As shown below, the median CEO stake for these behemoths overall was 5.6%. Perhaps as expected, the median CEO ownership for those companies that were VC incubated (4.2%) was lower than those that were founder-led (7.4%).
Founding CEO Equity Just Before IPO
Biotech Behemoths (n=29)
VC-Led Behemoths (n=13)
Traditional Founder-Led Behemoths (n=16)
Median
5.6%
4.2%
7.4%
Mean
10.0%
6.1%
13.1%
Standard Deviation
11.5%
5.9%
14.0%
Max
54.6%
22.5%
54.6%
Min
1.0%
1.0%
2.4%
Educational Backgrounds of Founding CEOs
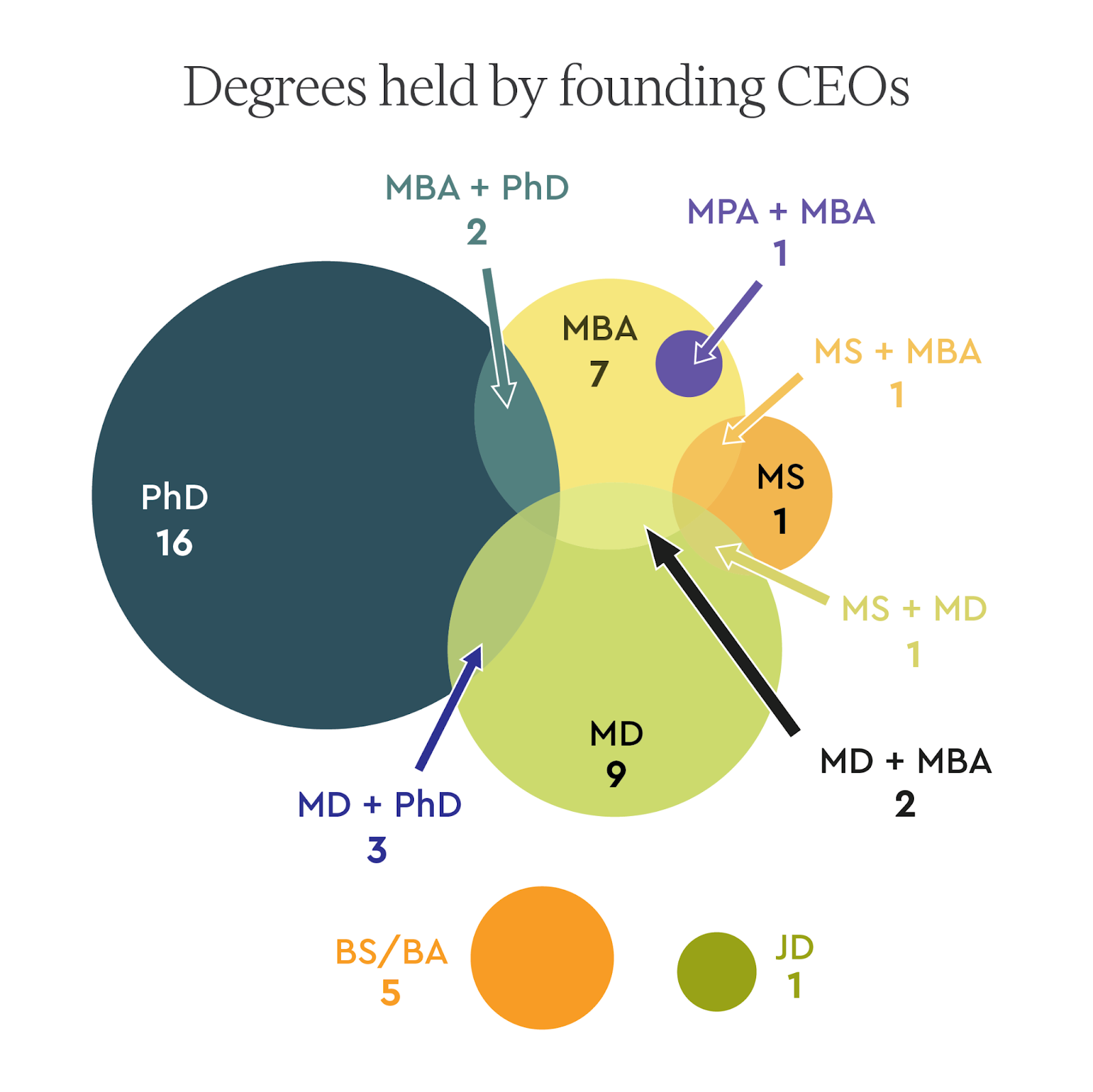
We reviewed the educational backgrounds of the founding CEOs. Of the 49 founding CEOs for whom we were able to find detailed educational data, the PhD was by far the most commonly held degree (21). The next most commonly held degree was an MD (15), followed by an MBA (13). The majority of founders held only one of these degrees, but there were a handful of MD/PhDs (3), MD/MBAs (2), and PhD/MBAs (2). Nearly all founding CEOs held a graduate degree (43), and most had specialized technical or scientific training via graduate school prior to starting their biotech company (35).
Academic Affiliations of Scientific Founders
Many biotech companies have academic roots. From our list of 50 companies, 30 had founders affiliated with at least one academic institution. The institutions that boasted the most founders were Harvard (7), Stanford (4), and UCLA (3). After these were Mass General Hospital (2), Fred Hutchinson Cancer Center (2), UCSF (2), and MIT (2).
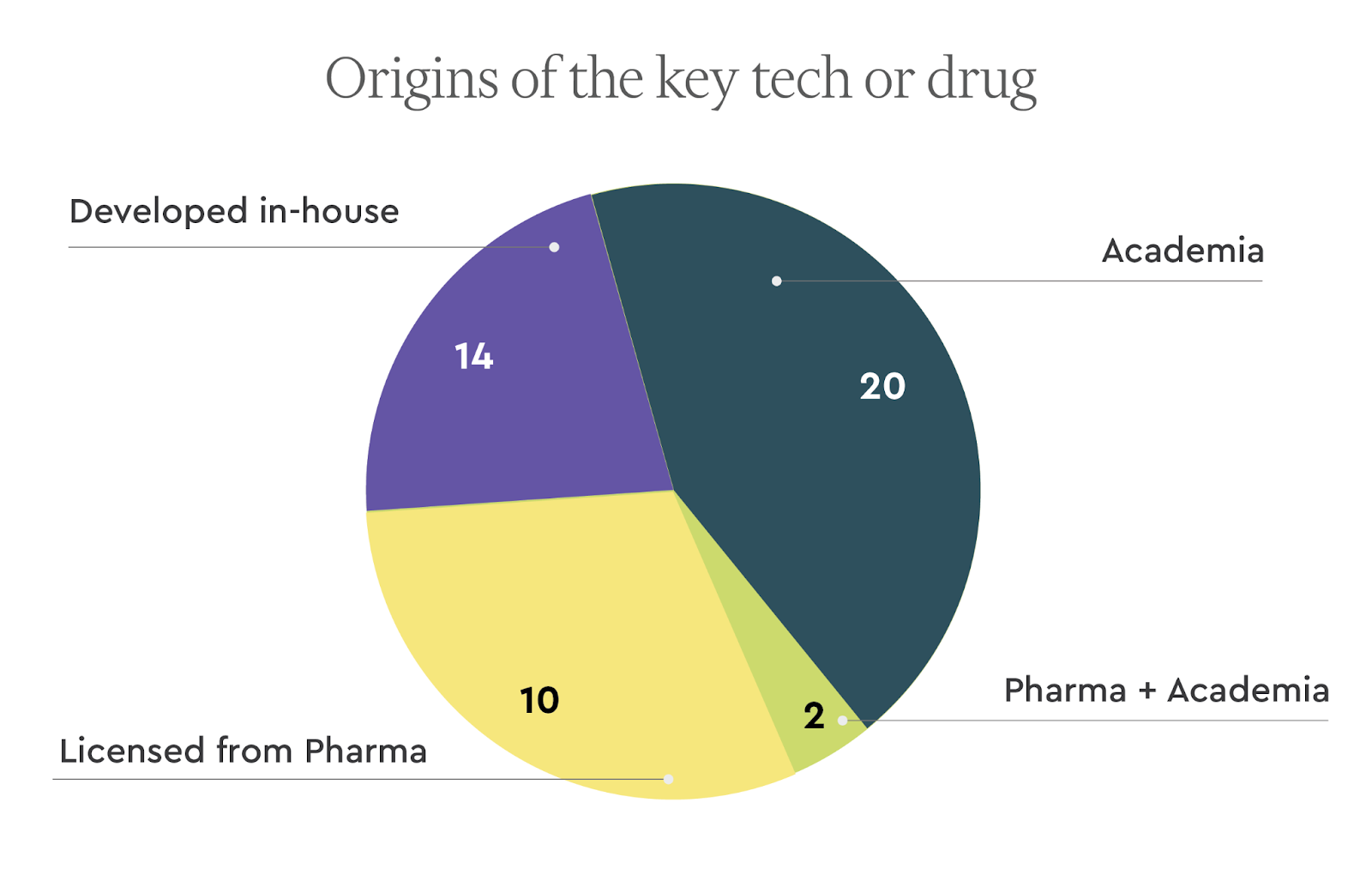
Institutions giving rise to the key technologies/drugs
Among the top therapeutics companies, the lion’s share of leading drugs originated from academic institutions. We find it interesting that 12 of these startups licensed drugs from pharma.
The research institutions that licensed out the key drugs or technologies are widely spread. The top two originating academic institutions were Stanford (4 companies) and the University of California, San Francisco (3 companies). (We combined BridgeBio and Eidos Tx here)
Global Blood Therapeutics, Sana, Revolution Medicines
Fred Hutchinson Cancer Center
2
Juno, Lyell
University of Pennsylvania
2
Moderna, Apellis
Cedars-Sinai
1
Prometheus
Children’s Hospital of Philadelphia
1
Spark Therapeutics
City of Hope
1
Juno
Genethon
1
Audentes
Harvard
1
Sana
Massachusetts Institute of Technology
1
Translate Bio
Memorial Sloan Kettering Cancer Center
1
Juno
National Cancer Institute
1
Kite
Nationwide Children’s Hospital
1
Avexis
St. Jude Children’s Hospital
1
Juno
The Chinese University of Hong Kong
1
Grail
The Scripps Research Institute
1
Receptos
UC Berkeley
1
Intellia
UC San Diego
1
VelosBio
University of British Columbia
1
Abcellera
University of Chicago
1
Provention Bio
University of Florida
1
Audentes
University of Utah
1
Recursion
University of Washington
1
Sana
Geography
Half of these behemoths were founded either in the Bay Area (15 of 50) or the Greater Boston Area (10 of 50). A significant portion was also founded in Southern California (7 of 50 in San Diego and Los Angeles).
Only three of the 50 companies were founded outside of the US: AbCellera (Canada), CRISPR Therapeutics (Switzerland), and Acerta Pharma (Netherlands), although the latter two grew to establish significant presence in Boston and the Bay Area, respectively.
Company financial characteristics:
Valuations
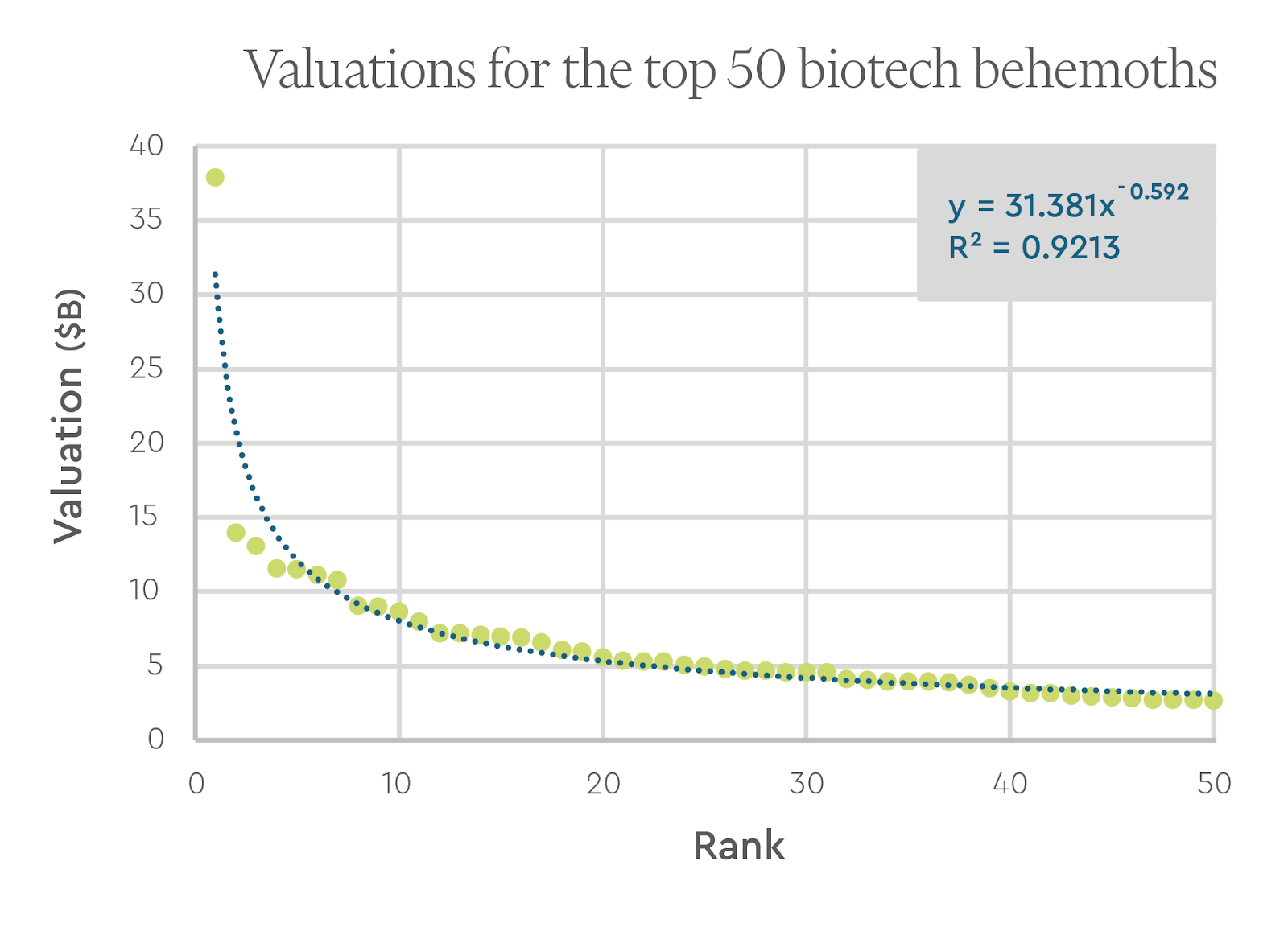
A valuation of ~$2.7B was required to make it into the top 50 companies, which represented the top 0.17% of all therapeutics and diagnostics/tools companies (~28,000) founded during the 15 year time frame. These top 50 companies also represented roughly 2.5% of all therapeutics and diagnostics/tools companies that had raised more than $50M.
These biotech behemoths are no doubt outliers. In the business of venture capital, such outliers overwhelmingly drive fund returns, and the distribution of company returns have been described by a power law. As seen below, a power law equation provides a fairly good fit for the valuations of the behemoth, although the companies in the long tail need to be included for a better estimation of the full trend.
Aggregate Multiple on Invested Capital (MOIC)
The top 50 biotech startups achieved an aggregate value of ~$322B with a total of ~$43B raised (unadjusted dollars), for a rough MOIC (here simply defined as total valuation/total investment) of ~7.5.
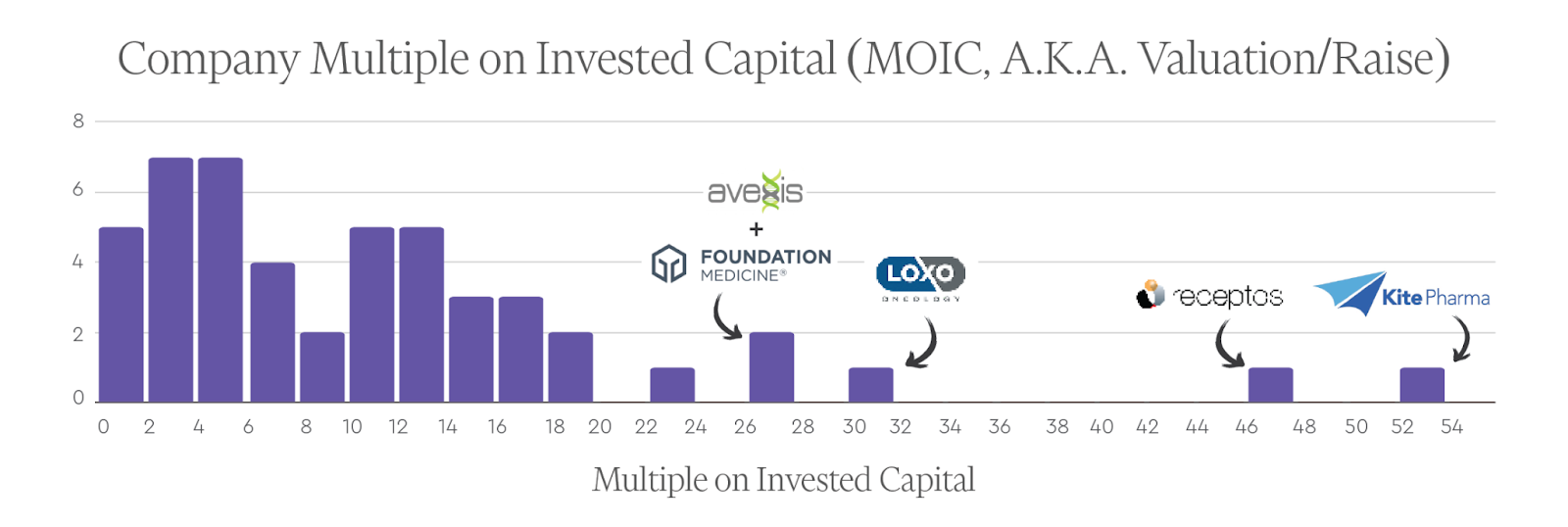
Individual Company MOICs
The average individual company MOIC (also defined as valuation/investment for each company) for the top 50 companies was ~11.7 and the median was ~9.7. The companies with the highest MOICs were Kite (~52.5x), Receptos (~46.2x), Loxo (~30.8x), Avexis (~27.6x), and Foundation Medicine (~26.8x).
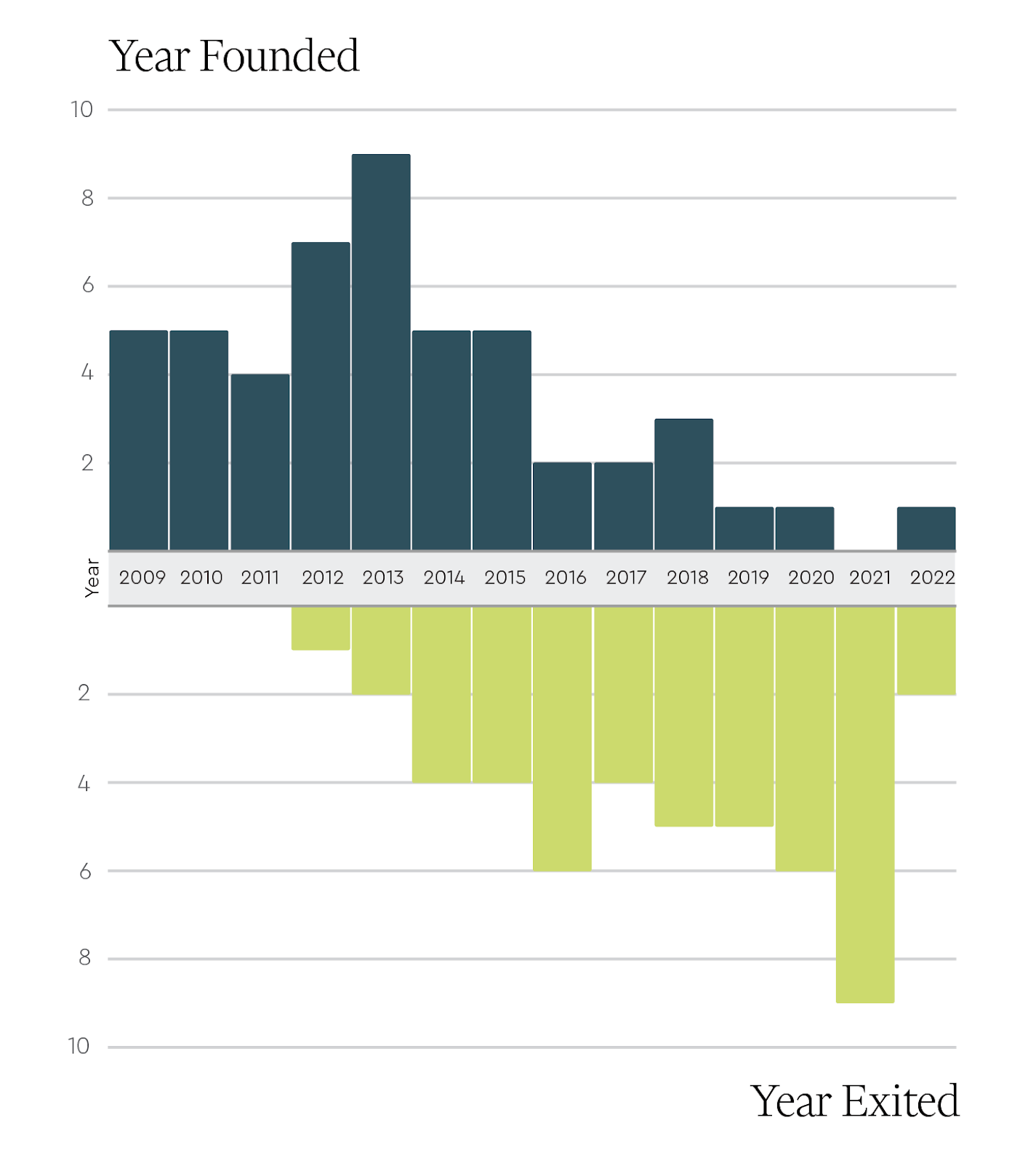
Founding Year and Exit Year
Given the time it takes for biotech companies to accrue value, the histogram of number of companies by founding year is not surprisingly skewed toward earlier years within the 2009-2023 period. Among these behemoths, the most common founding year was 2013 with 9 companies (Biohaven, Juno, Loxo, Vaxcyte, CRISPR, Spark, Turning Point, Eidos, and Recursion).
Also not unexpectedly, the year of initial exit (again, defined as either a public financing event or an acquisition) for these top 50 companies skewed later in the 15 year period and clustered around years representing favorable capital markets for biotech. 2021 was the most common initial exit year, followed by 2020 and 2016.
Time to Initial Exit
We looked at the number of years it took for these companies to get to an initial exit. Among these behemoths, the mean number of years was 4.7 years with a standard deviation of 2.7 years. Remarkably, 5 companies achieved an initial exit the next year after founding (Juno, Telavant, Loxo, Immunovant, and Chinook).
Comparison to top tech startups:
To contextualize selected data regarding these top biotech startups, we ran an analogous search for the top 50 tech companies founded during the same period.
The top 50 tech companies (“the tech titans”) had a higher average valuation than the biotech behemoths. Notably, the most valuable tech company on the list was Uber ($156B), worth almost 4x the most valuable biotech company, Moderna ($38B), and also worth almost half of the behemoths combined. The lowest valuation among the tech titans was $3.2B (representing the top 0.2% of all tech companies founded in the period), whereas it was $2.7B for the biotech behemoths (also representing slightly under 0.2% of biotech companies founded in the period).
For the tech titans, the average company MOIC was 23.2 and the median was 9.4. The average was driven up by companies like WhatsApp (~317x), the TradeDesk (~197x), and Honey (~56x). The average company MOIC for the biotech behemoths was lower at 11.7, though the median company MOIC was comparable at 9.7.
In aggregate, despite the many differences across these two industries, the rough MOICs of the top startups as a class looked surprisingly similar (~7.4 for tech & ~7.5 for biotech).
One key difference, however, was that the average time to an initial exit for the titans (8.2 +/-2.1 years) was considerably longer than that for the behemoths ( ~4.7 +/- 2.7 years).
Additionally, M&A was a much more important type of exit for the behemoths vs. the titans. For the biotech startups, acquisitions represented 24% of initial exits, and ultimately 52% were acquired. Only 18% of the tech companies went on to an ultimate acquisition.
We next compared the ages of the founding CEOs. The average age of the CEOs at founding for the titans was significantly younger at ~36 +/- ~8 years vs. that of the behemoths at ~46 +/- ~10 years.
Lastly, for those companies that went public, and that retained the founding CEO at IPO, we compared the CEO stake just before IPO. As seen in the summary below, the founding CEOs of the titans tended to retain more equity in their companies compared with those of the behemoths, with the median ownership in tech (11.7%) approximately double that in biotech (5.6%).
Founding CEO Equity Just Before IPO
Biotech Behemoths(n=29)
Tech Titans(n=30)
Median
5.6%
11.7%
Mean
10.0%
12.8%
Standard Deviation
11.5%
8.6%
Max
54.6%
41.5%
Min
1.0%
2.6%
Discussion and takeaways:
In this review of the top 50 biotech startups across therapeutics, diagnostics, and life sciences tools, the biotech behemoths were overwhelmingly drug companies. Even though diagnostics and tools companies undoubtedly create enormous value for patients and for the industry at large, the realities of their business models (generally lower pricing power and lower margins) render them arguably worse at capturing and retaining this value compared with therapeutics companies.
How did these particular biotech behemoths accrue such value? It’s clear that there was no one pathway to success.
Many companies focused on specialty drugs in oncology or rare disease, but two of the biggest behemoths focused on COVID and migraine, respectively – rather common indications.
Some companies developed their own products and technologies in-house, but most licensed them from academia or from other pharma companies. Some companies were VC-incubated, while many others were founder-led. Some companies brought flashy platforms to bear, but many others were asset-focused.
Some companies had experienced CEOs, but many others had first-time CEOs. Some companies boasted scientific founders from Stanford or Harvard, but the vast majority did not.
While there was an abundance of behemoths located in the key biotech hubs where capital, innovation, and management talent converge, i.e. the Bay Area and Boston, there was still a rather wide geographical spread – at least in the US. There were remarkably only 3 behemoths founded outside of the US.
Regarding the comparison between the biotech behemoths and the tech titans, most would agree that the two types of companies look radically different with respect to capital intensity, technical risk, degree of regulation, preponderance of binary outcomes, the market sizes addressed, and so on. Indeed, the most stunning successes for the behemoths paled in comparison with some of the titans in terms of both valuations and the multiples on invested capital achieved.
Yet when it came to the metric of total value created to total investment for the entire class, the overall showing for the behemoths was surprisingly similar to that of the titans.
The behemoths also tended to return capital faster than the titans due to the greater role that M&A has in biopharma (thanks to drugs continually losing exclusivity) and due to the availability of robust public capital markets to help fund expensive and risky late-stage clinical development. These findings should give prospective founders of biotech behemoths some relief.
Ultimately, what draws many to our industry is the prospect of bringing forth a new medicine that completely changes the existing standard of care; a diagnostic that adds years to a patient’s life because the disease was caught early or the right therapy was selected; or a technology that uncovers unknown biology and paves a path toward a better treatment.
By this measure, the biotech behemoths highlighted here were certainly the standard bearers for the past 15 years, developing, among other achievements, the first mRNA vaccine brought to market at a breakneck pace to address a global pandemic; a treatment for schizophrenia that precisely targets a novel pathway in the brain, while carefully avoiding side effects elsewhere in the body; the first gene therapy to restore vision to patients with an inherited blindness disorder; the first cell therapies to potentially cure a portion of patients suffering from an intractable blood cancer; genetic tests to better guide care for cancer patients; and technologies to measure the variations in the genome and the transcriptome at the level of individual cells.
What will the next generation of behemoths look like? We have a handful of predictions.
Therapeutics companies will continue to dominate. While there are headwinds with the IRA and other pricing pressures, at a high level the business model still looks favorable relative to that of diagnostics or life sciences tools, and the science is continuously progressing. We hope that we have in fact, as some data suggest, turned a corner on Eroom’s law.
Given pharma’s appetite to build on the breakthrough successes of drugs such as GLP-1 agonists for diabetes/obesity and anti-amyloid antibodies for Alzheimer’s, we can easily see several $5-15B companies being built that focus on first-in-class or best-in-class assets within metabolic disease, neurology, and immunology.
As has been the case since the birth of the biotech industry with recombinant DNA technology and companies like Genentech and Amgen, we will continue to see well-funded therapeutics behemoths founded on innovative platforms: new target discovery platforms, new methods for drug design, and new and improved modalities. For example, with the right business model and execution, a company that can truly solve extrahepatic, tissue-specific IV delivery of large nucleic acid cargoes could be worth billions in light of the plethora of valuable therapeutic payloads just wanting for delivery and the concomitant diseases that could be addressed.
We will see a few software companies for biopharma reach $3-5B. Pharma spends over $200B globally on R&D, but very little on software, and it shows. Much of the software stack in use today by biopharma R&D teams is outdated, clumsy, or fragmented. This current state, paired with the expectation that AI will impact many parts of the drug development value chain beyond target or drug discovery, suggests that eventually pharma companies will have to spend significantly more on software or risk losing their edge.
The Bay Area and Boston will continue to dominate the rankings as network effects in these hubs compound over time.
The founding CEOs of behemoths will continue to trend older than those of the titans. We think this difference in part reflects the substantial education and experience that can be crucial for founders to succeed in the complex, regulated industry of biotechnology. Perhaps as importantly, access to the substantial amounts of capital needed to achieve important value inflection points in therapeutics companies will likely continue to be gate-kept by blue chip investors who are reluctant to take on significant team risk, in addition to the many other types of risk present in these businesses.
However, we expect the founding CEO list to grow more diverse across both race and gender thanks to industry-wide efforts to promote diversity and inclusion among company boards and senior leadership teams.
We here at Pear are excited to back the next generation of such behemoths, and we can’t wait to see the impact they make on patients and our industry.
Acknowledgements:
We thank Mar Hershenson, Sarah Jones, Daniel Simon, Elliot Hershberg, and Curt Herberts for their helpful feedback and comments on earlier drafts of this review, as well as Joanna Shan for optimizing the graphics.
Here at Pear, we specialize in backing companies at the pre-seed and seed stages, and we work closely with our founders to bring their breakthrough ideas, technologies, and businesses from 0 to 1. Because we are passionate about the journey from bench to business, we created this series to share stories from leaders in biotech and academia and to highlight the real-world impact of emerging life sciences research and technologies.This post was written by Pear PhD Fellow Sarah Jones.
Today, we’re excited to share insights from our discussion with Dr. Kevin Parker, CEO and co-founder of Cartography Biosciences. Kevin is a first-time founder working to identify new cancer immunotherapy targets and to make precision cancer treatment a reality.
More about Kevin:
After receiving his bachelor’s degree in human development and regenerative medicine from Harvard, Kevin completed his PhD in just over four years in the lab of Prof. Howard Chang at Stanford. As a trailblazer and successful technical founder, Kevin has also been named to the Forbes 30 under 30 healthcare list and Endpoints 20 under 40 in biopharma. His scientific interests span immuno-oncology, genetics, precision medicine, and single-cell characterization methods. In 2020, he made the decision to take his work in the Chang lab from academia to industry and officially started Cartography Biosciences.
If you prefer listening, here is the recording:
Key takeaways:
1. Most immuno-oncology drug discovery programs are focused on the exact same targets. Instead of racing toward these well-known targets, Kevin Parker and his team at Cartography are working to create a platform that unlocks new targets.
During his PhD training, Kevin realized that he was most passionate about working on projects that could have a direct impact on the lives of patients. While working in Prof. Howard Chang’s lab, he had the chance to join a collaborative project with Prof. Carl June’s lab at the University of Pennsylvania.
The goal of that project, which was published in the esteemed scientific journal Cell, was to understand why CD19-directed chimeric antigen receptor (CAR) T cell treatments for cancer had high rates of neurotoxicity. Essentially, CAR T cells are immune cells that have been modified to specifically target and kill cancer cells. However, CD19-targeted CAR T cell therapies can have negative effects on the brain and cause neurotoxicity.
The team utilized a technology called single-cell RNA sequencing, or sc-RNAseq, to characterize the gene expression of individual cells in the brain. Ultimately, they were able to gain insight into CD19 expression and better understand what caused the neurotoxicity.
That initial project where we looked at single-cell sequencing of the human brain made us appreciate how complex it was to really understand target biology and how important it was to be able to use tools like single-cell genomics to understand cell expression across the genome. Some of these ideas ended up percolating into the realization that we didn’t just need to be able to understand existing targets better, but we needed to find new targets that had better specificity.
While cancer immunotherapies can be transformative for certain subsets of patients, the rate at which we are discovering new targets–and thus expanding the range of patients we can treat effectively–has slowed dramatically. In other words, we’re seeing a whole lot of new hammers being made, but not a lot of nails.
The growing immuno-oncology landscape is now ripe with companies and pipelines that look increasingly similar to one another.
Companies are competing against the same targets and the same patients, which is great for those patients, but it leaves a lot of patients behind.
New target identification is not a simple task, but Kevin and his team have made it their mission to find novel ways of killing cancer cells and sparing healthy cells.
To do this, they are mapping out every single cell in the healthy body and every cell in a patient’s tumor. They believe that this in-house data set holds the keys to unlocking new biological targets that are only found on cancer cells.
The way that we do that is by building up this data set that encompasses effectively every major cell type across the body and every cell in a patient’s tumor so that you can go and kind of line up the genomic profiles of every single one of these populations and say, ‘okay, these are the cells I’m trying to target.’ Now, we can look at this from a data-driven, ground-up computational approach and [find] the most specific way to target them.’
2. Platform-based companies must strike a balance between building a strong platform and focusing on the advancement of a lead program or drug candidate.
Inherently baked into Cartography’s approach is a huge amount of data generation and analysis. Much like finding a needle in a haystack, new targets have to be identified and carefully characterized across all the healthy cells in the body to ensure drugs won’t have nasty, off-target effects.
For the first couple of years after the company’s creation, efforts were centered primarily around building up a robust data set that could feed their pipeline and serve as the basis for multiple lead programs.
Now that we have [a strong data set], we found some targets that are really compelling, and we can focus on building those out in our pipeline.
To overcome the technical challenges associated with new target identification, Kevin noted that access to high-quality primary viable tissue samples has been critical for them. However, it can take time to build necessary agreements and collaborations to gain access to these types of samples.
Kevin also acknowledged the value in balancing pipeline generation with platform development. While Cartography may be particularly adept at identifying new targets, it is also important to build programs around the targets they have the most confidence in.
We’ve got to build a pipeline if we believe in our targets, which we do… There’s this tradeoff between wanting to give [the platform] enough freedom to explore and make those serendipitous discoveries that we might not otherwise make, and wanting to actually do something with it and build a pipeline out of it.
When identifying new targets and making decisions about which to pursue, it is also important to consider what patients will benefit most and what indications you are likely to have success in.
Hypothetically, Kevin explained that there’s no clear cut way to decide between a target that hits 60% of patients 40% well and a target that hits 40% of patients 60% well.
There’s no right answer to that. It’s something that every company has to wrestle with and figure out for themselves. For us, the general approach is to first pick an indication where we want to make a difference and where we think we can make a difference.
3. It is becoming increasingly common to see companies leverage both wet and dry lab approaches to increase the pace of scientific discovery. One of Cartography’s distinct advantages is its ‘dampness,’ or its blurred lines between its wet and dry lab efforts.
Kevin shared that one of his main priorities as CEO is bringing in people who can play in both worlds and conduct research in both the wet and dry lab. They have a certain level of ‘dampness.’
Instead of having a wet lab team focused only on biology and a dry lab team focused only on computation, it’s important to allow both teams to interface and work closely with one another.
We’ve actually been merging those teams closer over time… Because there is a lot [of overlap] between them, they have to work together, sync their timelines, and work together as a group.”
It’s no secret that an early-stage technical founder has to wear a lot of hats and fulfill many different roles. Hiring is one crucial job that comes into play extremely early on.
Many employees specialize either in wet lab techniques like single-cell sequencing or in dry lab computation; however, Kevin notes that he specifically looks for scientists who have a breadth of training and experience and can operate at multiple levels in the discovery process.
This helps to create a feedback loop and speed up the overall rate of target identification. Though, making good hires is often easier said than done and is more of an art than a science.
The major thing that I try to look for and think about is to understand what the person that I’m talking to is trying to solve for… To what extent are they solving for a salary or a job title? Do they only want to manage people or do bench science? Of course they want to grow in their career, but their goal should be to make the company successful irrespective of what it is [they] need to do or need to change.
4. Though a lack of previous experience can be challenging, being a technical founder can be a very rewarding experience.
Many aspects of company-building can be daunting to new founders, particularly technical founders. Getting your PhD doesn’t necessarily prepare you for the numerous roles and responsibilities a CEO and founder must fulfill.
However, in the early days, Kevin explained that the ability to dig deep, ask questions, and interface with the science is incredibly important in deciding how the company should move forward.
I think that [being a technical founder] gives you an ability to really understand what is working and what isn’t working… You can only really do that as well as you possibly can if you can understand the technical details and can go into the weeds there.
One thing that helps keep Kevin grounded is the fact that most CEOs are first-time CEOs: even people who have worked in industry for 15-20 years most likely haven’t been a CEO either.
This point was solidified for Kevin when he went to a conference and was in a room full of other founders. They were asked to raise their hands if they were first-time CEOs, and about two thirds of the audience’s hands went up.
Even though it might seem like an uphill battle, it can be helpful to surround yourself with other CEOs who might be one or two steps ahead of you in their career who can provide advice and mentorship.
I feel very fortunate to be able to go on the journey. I think that being a technical founder gives you a lot of advantages. It also gives you a lot to learn.
Advice for early-stage founders:
Hiring good people quickly becomes job #1 as an early-stage CEO.
As you go through the hiring process, take the time to understand what someone’s goals and mindset are. It’s important to find alignment and find people willing to put the company’s priorities first.
Don’t forget that most CEOs are first-time CEOs.
While you might wear a lot of different hats in the very early days, it is important to grow into the CEO role and learn to manage and lead your team.
Build your network intentionally and thoughtfully.
Find yourself a personal advisory board of people who have walked in your shoes – other CEOs a few steps ahead who can provide invaluable insight and mentorship.
Here at Pear, we specialize in backing companies at the pre-seed and seed stages, and we work closely with our founders to bring their breakthrough ideas, technologies, and businesses from 0 to 1. Because we are passionate about the journey from bench to business, we created this series to share stories from leaders in biotech and academia and to highlight the real-world impact of emerging life sciences research and technologies.This post was written by Pear PhD Fellow Sarah Jones.
Today, we’re excited to share insights from our discussion with Dr. Shelley Force Aldred, CEO and co-founder of Rondo Therapeutics. Shelley is a serial founder and prominent figure in the antibody drug development space.
More about Shelley:
Shelley earned a Ph.D. in genetics from Stanford where she worked on the human genome and ENCODE projects in the lab of Rick Myers. She spun her first company SwitchGear Genomics out of Stanford in 2006 with a grad school colleague who has since become her long-term business partner. After selling SwitchGear in 2013, Shelley shifted her focus from producing genomics tools to developing therapeutics: she helped build TeneoBio from the ground up, leading preclinical development of the company’s T-cell engager platform for treating liquid tumors, a platform that has generated $1.5 billion in upfront payments to date from multiple big pharmas. Shelley then moved on to start yet another company, Rondo Therapeutics, where she currently serves as CEO. There, she leads a team that develops innovative therapeutic antibodies for the treatment of solid tumors.
1. The therapeutic window in immuno-oncology is narrow: tuning the immune system in the case of solid tumor treatment can be like playing with fire. To overcome this, Rondo has focused on using bispecific antibodies to find the ‘Goldilocks’ zone between efficacy and toxicity.
Previously at Teneobio, Shelley spearheaded efforts in preclinical development of immune cell engaging antibodies for liquid tumors. However, the lessons they learned and the molecules they developed couldn’t make a dent in solid tumors. Wanting to attack this problem head-on, Shelley and her long-time colleague Nathan Trinklein made the decision to start Rondo Therapeutics.
One characteristic behavior of solid tumors that makes them particularly difficult to treat is their ability to trick the immune system into thinking they aren’t a threat. To combat this, Rondo is creating immuno-oncological therapies that can re-activate the immune cells that reside in the tumor microenvironment.
Rondo’s efforts have been focused on the development of bispecific antibodies which are Y-shaped molecules with two arms that each can grab on and bind to different substrates. Rondo engineers these antibodies so that one arm recognizes and binds to proteins on the tumor cells while the other arm grabs onto immune cells. This brings the cells into close proximity so that the immune cells can recognize and kill the cancer cells.
Shelley noted that other strategies such as checkpoint inhibitors and antibody drug conjugates often lack efficacy in solid tumors. In addition, CAR-T and other cell therapies have shown some promising preliminary results, but they can’t be administered in an off-the-shelf manner and are difficult to scale up.
Where we felt like we fit is as an off-the-shelf solution to driving tumor and immune cell engagement in a way that’s targeted specifically to the location of the tumor and isn’t body wide.
However, modulating the immune response is no easy feat. If pushed too far, the immune cells can start to attack healthy cells and tissues elsewhere in the both. Rondo’s cutting-edge bispecific antibodies ‘thread the needle’ and strike a balance between sparing healthy cells and killing tumor cells. Shelley noted that Rondo has been making steady progress in preclinical development and plans to be in the clinic in 2025.
I think within other kinds of immune cell-engaging bispecifics, what we have a reputation for and are really good at is tuning and finding the Goldilocks zone. So, we’re going to be best in class in terms of this therapeutic window.
2. The ability to pivot and change directions is critical; one of Shelley’s strengths is her ability to follow the science and rely on the advice of her team.
Being a founding member of three companies is quite an accomplishment. Shelley explained that joining a new company and growing it from the ground up is simultaneously an incredible opportunity and a ‘trial by fire.’ One of the advantages of working in a small start-up is the chance to take on roles that you might not otherwise have access to.
[In a smaller company], you get to see more pieces than you would in a larger company. Inherently, when you’re in a group of only 10 or 20 people, there’s so much more visibility into what’s happening in other groups or in other people’s responsibility spheres. It’s really hard to get that in a larger company.
Each member within a smaller team has more responsibility in guiding the company and achieving critical milestones. Early founders and employees have to wear a lot of different hats to solve problems and ultimately push the company forward.
For example, Shelley noted that she had to spend a lot of time thinking not only about the science, but also about choosing the right targets and indications to pursue.
Part of that is staying humble and realizing you might not always be choosing the right targets on the first pass. We do high-throughput genomic space discovery, and so we always have a lot of targets in the mix; we have our lead program, but we also have backup programs. Particularly in this field, targets can go cold really quickly, depending on clinical results that are coming out from other companies.
Shelley also emphasized the importance of finding those who are willing to ride the roller-coaster with you. Bringing in experts and team members with different strengths can help keep the company agile. There are many reasons why a pivot might be necessary, and it is important to be willing to follow the science and the market.
Even at Switchgear, the first company Shelley founded, an early pivot led to their eventual success and acquisition. In the initial view for the company, they anticipated having a small number of customers placing very large orders. However, it turned out that the market was asking that they have thousands of customers, each placing small orders through an e-commerce platform. By being willing to change their vision, the company ended up being extremely successful.
3. Your team is your most valuable resource, especially early on in company creation, and it’s important to surround yourself with a supportive community and a team you fully trust.
It’s not a coincidence that Shelley found herself working alongside Nathan Trinklein at three of her companies – Switchgear, Teneobio, and Rondo. After running operations at Switchgear and overseeing its acquisition, the pair found themselves wanting to transition to therapeutics to get closer to patients and into a bigger market.
Company building is a heavy lift, and being able to do that with someone with great capability that I trust deeply has increased my enjoyment of doing this quite a bit. But I also think it’s increased our likelihood of success at every step: we both have deep respect for each other and enough confidence that we just push on each other all the time. I mean, there’s constant pressure testing of ideas and conclusions. And I think what comes out the other side is always better than it would have been if only one of our brains was attacking it.
Another important relationship that needs to be established early on is between the founding team and the investor syndicate. Ideally, early-stage companies will have the opportunity to choose investors that support their long-term vision for the company – though the funding environment will likely determine exactly how much of a choice a founder has.
At Rondo, Shelley prioritized investors who were deeply versed in therapeutics and understood the relevant risks and timelines for milestones. Biotech tends to move at a slower pace, and finding firms that understand this can make a huge difference in the long run.
I am grateful for my current funding syndicate at Rondo… they are all really experienced therapeutics investors, and this is important because it means they have realistic expectations about what we’re going to be able to achieve on what timelines and what amount of capital this is going to take. It also means that their deep expertise and their networks help support us quite a bit.
4. It’s not a secret that starting a company is hard, but Shelley highlights a few ways she stays motivated. Explaining that she prioritizes bringing high quality talent into her companies, she says it’s a good thing to ‘feel a little bit stupid, at least once a day.’ Being challenged to do better and learn more is one of her favorite things about the job.
Looking back over the summation of her experience as an operator, CEO, and co-founder, Shelley acknowledged that she grew and learned a lot about herself, “realizing with the exquisite mix of joy and pain that is starting a company, it was indeed the right place for me.”
Her motivation comes from keeping herself always on the steep phase of the learning curve. Instead of focusing on what she doesn’t know or isn’t able to do, she pushes herself to learn constantly from her team and to bring in people who are experts in their roles.
Not only does Shelley spend a lot of time recruiting and finding good employees, she also spends a considerable amount of time finding community within the broader biotech ecosystem to help keep her motivated.
We all fight different battles in our professional careers… and my network of other entrepreneurs has kept me afloat during a fundraising process when you’ve gotten a 50th no and you’re not sure you can get up and do it again. Talking to someone who’s been there and says, ‘I know you can get up to pitch number 51,’ is really important.
Shelley also explained the importance of finding people with shared experiences who can support you. While she enjoys challenging herself and pushing her limits, she also gives credit to her network and support system for keeping her grounded. For example, she regularly meets with her group of women biotech CEOs, and she’s found a sisterhood of women through her HiPower women’s group where she serves as an executive member.
These groups of women have been life-saving, sanity-saving in 100 different ways: primarily because they know exactly what it feels like to operate in shoes just like mine. So whatever battles you are fighting, finding people who have fought similar battles is really important.
5. Not all technical founders make great, long-term CEOs. However, with commitment to leadership development and a willingness to learn on the go, Shelley has shown that it’s possible to grow into the role and successfully lead a company.
Depending on the company structure, size, sector, and investor preference, there are a number of reasons founder-CEOs may not stay at the helm of their company long-term. However, Shelley has shown that technical founders, with the right experiences and mindset, can be effective leaders.
While Shelley did admit to having a propensity for leadership growing up, she has made the conscious decision to invest in her own development: she reads countless books, has an executive coach, a therapist, and a willingness to apologize for her mistakes. Her humility and compassion also foster a positive team culture at Rondo.
What I’ve tried to do is own those mistakes, apologize, … and do better later. I think that people are really wonderful and supportive when you say, ‘you’re in a learning process, you can have some compassion for me, as I’m learning to be a better leader. Just like I will have compassion for you.’ It’s like you’re learning to do your job better, and it’s really opened the gates to excellent feedback.
Before stepping into her role as CEO, Shelley gained invaluable experience in operational positions as a founding team member of Switchgear and Teneobio. When asked about her decision to take the CEO role at Rondo, Shelley explained that she had always known she wanted to get a chance at the job and put herself in a position to take that opportunity.
When it comes to particular skills that have helped her to be an effective CEO, she explains that her strength isn’t in one particular area she excels at; instead, she is a jack of all trades.
I’m not off the charts in any one particular area, I think my advantage is that I’m good at a lot of things. So like I said, I’m a good scientist, I’m a good operator, I’m good at managing finances, I have a pretty natural sense of managing people, and I can kind of put all these things together. I think I also am good at synthesizing information that I get from a lot of different places, I’m willing to make hard decisions, and I have a pretty high risk tolerance.
Getting to know Shelley:
In her free time, Shelley likes to travel and is a voracious reader, with a particular affinity for mystery or detective novels or historical fiction. One thing people are surprised to learn about her is that she can drive a boat much better than she can drive a car because she grew up water skiing and boating regularly with her family.
Some advice she would give someone looking to follow in her career footsteps would be to create your own opportunities and to not waste time being miserable in your work. She noted that even in your best jobs, not every day will be a good one. However, she said if you regularly wake up and dread going to work, it’s okay to look for something else.
Last week, Pear portfolio company BioAge Labs announced its $170M Series D round led by Sofinnova Investments, with participation from a strong syndicate of new investors including Longitude Capital, RA Capital, OrbiMed Advisors, RTW Investments, Eli Lilly, and Amgen, among others, in addition to many existing investors.
To mark this occasion, we wanted to share more about Pear’s partnership with BioAge Labs and its co-founders, Kristen Fortney (CEO) and Eric Morgen (COO).
Pear’s founders, Pejman and Mar, first met Kristen in 2015 through an introduction by another company founder associated with the Stanford Genome Technology Center. At that time, Kristen was a postdoc at Stanford in Professor Stuart Kim’s lab, where she studied the genetics of extreme human longevity. At the time, Kristen had published extensively in the space of genetics and longevity, but the company was merely an idea. She was pondering the question: could we use genetic information and new machine learning techniques to develop a therapy discovery platform for longevity? Kristen’s vision at the time was just as clear as it is today.
That year, Pear invested in BioAge’s initial seed financing, and we have gone on to successively back BioAge at every subsequent round, including the Series D.
As it’s not common for a seed-stage focused firm like ours to invest up until the Series D round, why have we continued to support BioAge?
Significant unmet need and large market opportunity in obesity and metabolic disease
The company’s lead drug program, azelaprag, addresses obesity and metabolic diseases. A staggering 40% of American adults are considered obese, and many suffer from a host of comorbidities including diabetes, heart disease, and stroke.
One of the most exciting recent medical advances has been the remarkable success of GLP-1 receptor agonist drugs in achieving dramatic weight loss in such patients, while still being generally safe and well tolerated.
With this drug class expected to eventually exceed $150 billion in sales annually, the top two developers, Eli Lilly and Novo Nordisk, have catapulted to become the first and second largest pharma companies by market capitalization (~$740B and $550B, respectively, as of mid-Feb. 2024).
As impressive as GLP-1 drugs are, one downside is that they can result in suboptimal body composition, in that they lead to the loss of both fat and muscle. BioAge’s preclinical studies have shown that azelaprag, which is a first-in-class oral apelin receptor agonist, can enhance body composition when combined with a GLP-1 drug. In a Phase 1b study sponsored by BioAge, azelaprag prevented muscle deterioration and promoted muscle metabolism in healthy older volunteers at bedrest.
A second limitation is that oral GLP-1 drugs have so far lagged behind the injectable versions in efficacy. Of course, most patients would strongly prefer orally dosed medications over injectables. In BioAge’s preclinical studies, azelaprag combined with a GLP-1 drug has been shown to double the weight loss achieved by the GLP-1 drug alone. Because it can be orally administered and has been well tolerated, azelaprag in combination with an oral GLP-1 drug may help to close this efficacy gap.
Human-first target discovery platform enabled by multi-omic analysis of aging human cohorts
BioAge didn’t initially begin with a focus on a lead therapeutic asset in obesity. In fact, BioAge started as a target discovery company within the longevity space, with the ambitious goal of understanding the biology of human aging in an effort to extend human lifespan and healthspan.
Although the longevity field has recently attracted much attention and investment, not all therapeutic strategies pursued have been equally scientifically rigorous. Many approaches rely on attempting to translate into humans tantalizing life extension or rejuvenation effects obtained in model organisms with very short lifespans like nematodes and mice.
But the biology of aging differs dramatically across species, and BioAge’s unique strategy was to partner with special biobanks that collected and stored blood from cohorts of people from middle age until death and that retained associated health records. By deploying multi-omics (primarily proteomics) and AI to interrogate the factors correlating with healthy human aging, the company generated unique insights into particular therapeutic targets of interest.
From this platform, one of the strongest targets that emerged was the peptide that azelaprag is designed to mimic – apelin. Exercise stimulates release of apelin from skeletal muscle into the blood, and in BioAge’s cohorts, middle-aged people with more apelin signaling were living longer, with better muscle function, and better brain function. Correspondingly, in mice, azelaprag protected elderly mice from muscle atrophy & preserved function in vivo.
Strong leadership team, advisors, and partners
As one might imagine, the team at BioAge has grown and matured substantially since inception in 2015. The leadership team today has world-class experience across biopharma. And in pursuing its Phase 2 study of azelaprag in combination with Eli Lilly’s GLP-1/GIP drug tirzepatide (Zepbound), BioAge will receive support from Eli Lilly’s Chorus organization, including the supply of tirzepatide and clinical trial design and execution expertise.
It’s certainly uncommon for a postdoc straight out of the lab to lead a therapeutics company until a Phase 2 clinical study. But as Kristen relayed during a fireside chat at our Pear office, she learned a lot about what she needed to know on the job progressively over time, and she was not afraid to surround herself with experts specializing in the many functional domains required to take a drug program from a target to the clinic.
This dedication to continual self-improvement and learning has been a hallmark of the many strong founders that we are fortunate to back at Pear. We are grateful that Kristen is helping to guide the next generation of such founders as part of our Pear Biotech Industry Advisory Council.
Pear Biotech Industry Advisory Council
For these reasons, we remain excited to support BioAge Labs. We eagerly anticipate the results of its mid-stage clinical trials of azelaprag in obesity, as well as the development of additional programs nominated from its unique human aging target discovery platform.
Here at Pear, we specialize in backing companies at the pre-seed and seed stages, and we work closely with our founders to bring their breakthrough ideas, technologies, and businesses from 0 to 1. Because we are passionate about the journey from bench to business, we created this series to share stories from leaders in biotech and academia and to highlight the real-world impact of emerging life sciences research and technologies.This post was written by Pear Partner Eddie and Pear PhD Fellow Sarah Jones.
Today, we’re excited to share insights from our discussion with Dr. Jim Collins, Termeer Professor of Medical Engineering and Science at MIT. Jim is a member of the Harvard MIT Health Sciences Technology faculty, a founder of the Wyss Institute for Biologically Inspired Engineering at Harvard, and a member of the Broad Institute of MIT. His work has been recognized with numerous awards and honors over the course of his career, such as the MacArthur “Genius” Award and the Dickson Prize in Medicine.
Hailed as one of the key pioneers of synthetic biology, Dr. Collins has not only published numerous high-profile academic papers, but also has a track record of success as a founder and as an entrepreneur, co-founding companies such as Synlogic, Senti Biosciences, Sherlock Biosciences, Cellarity, and Phare Bio. If all that wasn’t enough, he’s even thrown the first pitch at a Boston Red Sox game. We were lucky to sit down and chat with Jim about his experiences and his perspective on the future of synthetic biology.
If you prefer listening, here’s a link to the recording!
Key takeaways:
1. At its conception, synthetic biology was simply a ‘bottom-up’ approach to molecular biology utilized by collaborative, interdisciplinary scientists.
In the late 90’s, Jim’s focus in biology began to shift: rather than continuing to explore biology at the whole organism or tissue level, he found himself more excited about molecular-scale biology. After speaking with some bioengineering faculty members at Boston University who were interested in his background in physics and engineering, Jim was quickly invited to join the department. From there, his interest in designing and engineering natural networks and biological processes flourished.
At that time, however, bioengineers weren’t yet able to reverse engineer biological systems and exert precise control at the molecular scale. He asked,
Could we take a bottom-up approach to molecular biology? Could we build circuits from the ground up as ways to both test our physical and mathematical notions and also to create biotech capabilities?
Though it didn’t start out as a quest to launch a new scientific field, Jim’s work contributed heavily to what would become the foundation of synthetic biology. He noted the value in bringing together scientists with diverse backgrounds to work on the same problems; for example, neuroscience had greatly benefitted from the introduction of mathematical models to describe complex neural systems. In a similar way, physicists, mathematicians, and molecular biologists began to find themselves interested in the same sorts of complex biological questions that could not be answered by any one discipline alone.
Jim also acknowledged that in the early days, the tools to engineer gene networks and molecular pathways did not exist, yet his team could envision a future in which gene networks could be described and designed using elegant mathematical models and a modular set of biological tools. This goal helped to propel synthetic biology into existence.
2. The ability to program genetic circuits marked the beginning of synthetic biology and allowed efforts within the field to quickly progress.
One notable 1995 publication in Science authored by Lucy Shapiro and Harley McAdams that was titled ‘Circuit simulation of genetic networks’ helped to shape Jim’s efforts in programming genetic circuits. The paper explored parallels between electrical circuits and genetic circuits and used mathematical modeling to accurately describe the bacteriophage lambda lysis-lysogeny decision circuit. In this circuit, bacteriophages that have infected bacteria cells must decide whether they are going to kill the cell or remain dormant, sparing the cell’s life.
Such work helped to bridge the gap between bioengineering and molecular biology at a time when many bioengineers felt largely excluded from the world of molecular biology.
To prove that genetic engineering was possible, the Collins lab worked to develop a genetic toggle switch in the form of a synthetic, bi-stable regulatory genetic network that could be switched ‘on’ or ‘off’ by applying heat or a particular chemical stimuli. This is significant because researchers could now add well-defined genetic networks to cells in order to precisely control their behavior or output.
This work by Gardner et al. was published in 2000 in the prestigious scientific journal, Nature and was titled “Construction of a genetic toggle switch in Escherichia coli.” Interestingly, in the same issue of Nature, work by Mike Elowitz’s lab at Caltech also outlined the development of a synthetic gene circuit in E. coli. Their system, dubbed the ‘Repressilator,’ was also a regulatory network in which three feedback loops could oscillate over time and change the status of the cells. Basically, it was three genes in a ring where gene A could inhibit gene B, which could inhibit gene C, which could then inhibit gene A, creating an oscillatory network.
This critical body of work and scientific discovery both demonstrated that genetic engineering was possible and highlighted tools and methods that could be used to modulate molecular systems.
3. To expand the repertoire of synthetic biology, Jim has co-founded two companies, Synlogic and Senti Biosciences, that are aimed at targeting the gut microbiome and engineering the mammalian system.
While initial excitement for synthetic biology applications centered on biofuel generation, the small scale bioreactors were never a match for fossil fuel companies. The paradigm in synthetic biology started shifting away from biofuel generation in the early 2000s to focus on the microbiome and its role in human disease.
As local venture capitalists approached Jim and asked about what could actually be done with synthetic biology, it became clear to Jim that there were two main directions he could pursue.
One was…an opportunity to create a picks and shovels company in synthetic biology. So, coming to create additional components or capacity to address a broad range of indications and applications, be it biofuels, industrial applications, therapeutics. The second was that you could engineer microbes to be living therapeutics, and in some cases, living diagnostics.
Jim partnered with Tim Lu, his former student and eventual coworker at MIT, to start Synlogic. One early direction of Synlogic was tackling a rare genetic metabolic disorder, phenylketonuria (PKU), that causes the amino acid phenylalanine to build up in the body. The idea was that they could engineer a microbe that could break down this byproduct and thereby eliminate the negative effects of the disease. This approach relied on the ability of the synthetic biologist to directly harness and control cell behavior via genetic engineering.
Synlogic is also working on enzymes that produce therapeutic molecules instead of degrading toxic ones. The company now has efforts in inflammatory bowel disease and Lyme disease and has partnered with Roche to advance its pipeline.
By around 2015, synthetic biology had continued to grow as an academic discipline and had moved beyond microbes to mammalian cells. Jim had since moved his lab from Boston University to MIT, and it wasn’t long before he was once again collaborating with Tim Lu, this time to apply synthetic biology in a mammalian system. This marked the start of Senti Biosciences, a company aimed at creating ‘smart medicines’ using genetic circuits.
We began to consider the possibility that we could do a mammalian version of Synlogic. Could we begin to really advance the development of human cell therapy and gene therapy using synthetic genes and gene circuits to create smart medicines? Having therapeutics that could sense their environment, sense the disease state or sense the disease target and produce therapeutics in a meaningful, decision-making way… was an exciting notion.
4. Historically, a lack of support from the venture community and insufficient infrastructure have been challenges for the diagnostics space.
Another company Jim helped start, Sherlock Biosciences, also leverages synthetic biology but operates in the diagnostic space. Although the diagnostic space is a notoriously challenging one, Sherlock was founded with the goal of combining approaches from synthetic biology and CRISPR technology to develop next-generation molecular diagnostics for at-home tests.
While many of the companies started right before the COVID-19 pandemic ultimately didn’t make it long-term, the team at Sherlock was able to quickly pivot and develop a CRISPR-based COVID-19 diagnostic that gained FDA-approval in May 2020. Notably, this test was the very first FDA-approved CRISPR product.
Jim explained that the difficulties facing a company trying to operate in the diagnostics space are twofold:
(1) there is a lack of infrastructure for things like at-home testing, point-of-care testing, or nucleic acid tests
(2) there is a general lack of support for diagnostic companies in the venture community
Diagnostics companies are essentially valued as a multiple of revenue. In contrast, therapeutic companies can be valued based on projections 10-20 years in the future without the requirement of existing revenue. Combine this with the fact that wins tend to be much larger in the therapeutics space, diagnostic discovery and development have largely been set to the side.
While COVID-19 did help to bring interest to the sector, funding and infrastructure continue to limit breakthroughs in diagnostics.
5. Desperate for new antibiotics: a combination of synthetic biology, Machine Learning (ML) and in silico modeling has so far been fruitful.
With a challenging funding landscape, antibiotics have also been long-neglected by VC and industry. Despite this, Jim’s team was able to secure funding through The Audacious Project, a philanthropic effort put together by TED to support their work in antibiotic discovery. The funded project involved developing deep learning based models that could both discover and design novel antibiotics against some of the world’s nastiest pathogens. In fact, the team found success when they discovered a very powerful antibiotic called halicin.
Jim stressed the urgency for new antibiotic development: the pipeline has been drying up, but the demand has only increased. Acquired antibiotic resistance is also a significant problem that hasn’t yet been resolved.
As new, powerful antibiotics are developed, they become the last-line of defense against the worst, most deadly pathogens. However, drugs used as a last-line of defense don’t make it off the shelves very often: this means that there is less financial motivation to develop particularly potent antibiotics. To address this, Jim noted that we are going to need a new financial model to sufficiently support research in this space.
6. Past the hype cycle: the synthetic biology of tomorrow.
The field has experienced its fair share of ups and downs. In speaking with Jim, it’s clear that the roller coaster of high expectations and disappointing failures has not diminished his excitement about the future of synthetic biology.
In 2004, the initial hype cycle was centered on biofuels and their potential to replace fossil fuels. Unrealistic expectations combined with the high cost of biofuel production led to disappointment; people began to question whether or not synthetic biology could deliver.
In the second hype cycle, bold claims and an attitude that synbio could solve every problem in the world led to yet another massive let-down and shift in attitude towards the field.
I think the markets haven’t kept pace with the public statements that are being made by some of the high priests in the field. And that’s a shame. I do think synthetic biology will emerge as one of the dominant technologies of this century. Our ability to engineer biology gives us capabilities that can address many of the big challenges that we have. But it’s still going to take a lot of time, it’s still very hard to engineer biology, and biology is not yet an engineering discipline.
Successes in areas where biology still outcompetes chemistry have helped to put some points back on the board for synthetic biology. Increasing utilization in therapeutic development has leveraged the efficiency of biological systems and will help to pave the way for the next way of discoveries in the field.
Technologies like cell-free systems also have Jim excited about the future of synthetic biology.
Get to know Jim Collins:
Early career and developing a passion for science:
Jim comes from a family of engineers and mathematicians and has always found himself wanting to do science. Jim explained that when he was four years old, his dad was a part of a team that designed an altimeter for Apollo 11.
Another seminal event that influenced Jim’s decision to become a scientist was the decline of his grandfather’s health after a series of strokes left him hemiplegic. After watching someone he loved not receive the care or have treatment options that could restore function, Jim was inspired to pursue biomedical engineering.
Once he realized that he could interface with clinicians, entrepreneurs, and policy-makers as a professor, he realized that was the path for him.
Advice for early-stage founders:
Find a strong business team early on to help find market fit and to guide the development of your final product. Young scientists are not trained to be good CEO’s, and it’s often challenging to navigate these decisions if you don’t have the experience.
Make sure your strategy has a real market pull and is differentiated from other approaches.
At Pear, we recently hosted a Perspectives in AI fireside chat with Kamil Rocki, Head of Performance Engineering at Stability AI. We discussed breakthroughs at the hardware-software interface that are powering generative AI. Kamil has extensive experience with GPU hardware and software programming from his PhD research and his work at IBM, Nvidia, Cerebras, Neuralink, and of course now StabilityAI. Read a recap of that conversation below:
Aparna: Kamil, thank you for joining us. You’ve accomplished many amazing things in your career, and we’re excited to hear your story. How did you choose your career path and what led you to work on the projects you’ve been involved with?
Kamil: My journey into the world of technology began in my 20s. After a few years of rigorous mathematical studies, I found myself in a robotics lab. I was tasked with enabling a robot to solve a Rubik’s cube. The challenge was to detect the cube’s location in an image captured by a camera, and this had to be done at a rate of 100 frames per second.
I was intrigued by the work my peers were doing in computer graphics using Graphics Processing Units (GPUs). They were generating landscapes and waves, manipulating lighting, and everything was happening in real-time. This inspired me to use GPUs to process the images for my project.
The process was quite challenging. I had to learn OpenGL from my friends, write images to the GPU, apply a pixel shader, and then read data back from the GPU. Despite the complexity, I was able to exceed the initial goal and run the process at 200 frames per second. I even developed a primitive version of a neural network that could detect the cube’s location in the image.
In 2008, around the time I graduated, CUDA came out and there was a lot of excitement around GPUs. I wanted to continue exploring this field and heard about a supercomputer being built in Japan based on GPUs and ended up doing a PhD in supercomputing. During this time, I worked on an algorithm called Monte Carlo Tree Search, deploying it on a cluster of 256 GPUs. At that time, not many people were familiar with GPU programming, which eventually led me to the Bay Area and IBM Research in Almaden.
I spent five years at IBM Research, then moved to the startup world. I had learned how to build chips, design computer architecture, and build computers from scratch. I was able to go from understanding the physics of transistors to building a software stack on top of that, including an assembler, compiler, and programming what I had built. One of my goals at IBM was to develop a wafer scale system. This led me to Cerebras Systems, where I co-designed the hardware. Later I joined Neuralink and then Nvidia, where I worked on the Hopper architecture. I joined Stability, as we are currently in a transition to Hopper GPUs. There is a significant amount of performance work required, and with my extensive experience with this architecture, I am well-equipped to contribute to this transition.
Aparna: GPUs have become one of the most profitable segments of the AI value chain, just looking at Nvidia’s growth and valuation. GPUs are also currently a capacity bottleneck. How did we arrive at this point? What did Nvidia, and others, do right or wrong to get us here?
Kamil: Nvidia’s journey to becoming a key player in the field of artificial intelligence is quite interesting. Initially, Nvidia was primarily known for its Graphics Processing Units (GPUs), which were used in the field of graphics. A basic primitive in graphics involves small matrix multiplication, used for rotating objects and performing various view projection transformations. People soon realized that these GPUs, efficient at matrix multiplications, could be applied to other domains where such operations were required.
In my early days at the Robotics Lab, I remember working with GPUs like the GeForce 6800 series. These were primarily designed for graphics, but I saw potential for other uses. I spent a considerable amount of time writing OpenGL code to set up the entire pipeline for simple image processing. This involved rasterization, vertex shader, pixel shader, frame buffer, and other complex processes. It was a challenging task to explore the potential of these GPUs beyond their conventional use.
Nvidia noticed that people were trying to use GPUs for general-purpose computing, not just for rendering images. In response, they developed CUDA, a parallel computing platform an application programming interface model. This platform significantly simplified the programming process. Tasks that previously required 500 lines of code could now be achieved with a program that resembled a simple C program. This opened up the world of GPU programming to a wider audience, making it more accessible and flexible.
Around 2011-12, the ImageNet moment occurred, and people realized the potential of scaling up with GPUs. Before this, CPUs were the primary choice for most computing tasks. However, the realization that GPUs could perform the same operations on different data sets significantly faster than CPUs led to a shift in preference. This was particularly impactful in the field of machine learning, where large amounts of data are processed using the same operations. GPUs proved to be highly efficient at performing these repetitive tasks.
This realization sparked a self-perpetuating cycle. As GPUs became more powerful, they were used more extensively in machine learning, leading to the development of more powerful models. Nvidia continued to innovate, introducing tensor cores that further enhanced machine learning capabilities. They were smart in making their products flexible, catering to multiple markets including graphics, machine learning, and high-performance computing (HPC). They supported FP64 computation, graphics, and tensor cores, which could be used for ray tracing and FP64. This adaptability and flexibility, combined with an accessible programming model, is what sets Nvidia apart in the field.
In the span of the last 15 years, from 2008 to the present, we have seen a multitude of different architectures emerge in the field of machine learning. Each of these architectures was designed to be flexible and adaptable, capable of being executed on a GPU. This flexibility is crucial as it allows for a wide range of operations, without being limited to any specific ones.
This approach also empowers users by not restricting them to pre-built libraries that can only run a single model. Instead, it provides them with the freedom to program as they see fit. For instance, if a user is proficient in C, they can utilize CUDA to write any machine learning model they desire.
However, some companies have lagged behind in this regard. Their mistake was in not providing users with the flexibility to do as they please. Instead, they pre-programmed their devices and assumed that certain architectures would remain relevant indefinitely. This is a flawed assumption. Machine learning architectures are continuously evolving, and this is a trend that I foresee continuing into the future.
Aparna: Could you elaborate more on the topic of special purpose chips for AI? Several companies, such as SambaNova Systems and Cerebras, have attempted to develop these. What, in your opinion, would be a successful architecture for such a chip? What would it take to build a competitive product in this field? Could you also shed some light on strategies that have not worked well, and those that could potentially succeed?
Kamil: Reflecting on my experience at Cerebras Systems, I believe one of the major missteps was the company’s focus on building specialized kernels for specific architectures. For instance, when ResNet was introduced, the team rushed to develop an architecture for it. The same happened with WaveNet and later, the Transformer model. At one point, out of 500 employees, 400 were kernel engineers, all working on specialized kernels for these architectures. The assumption was that these models were fixed and optimized, and users were simply expected to utilize our library without making any changes.
However, I believe this approach was flawed. It did not take into account the fact that architectures change frequently. Every day, new research papers are published, introducing new models and requiring changes to existing ones. Many companies, including Cerebras, failed to anticipate this. They were so focused on specific architectures that they did not consider the need for flexibility.
In contrast, I admire NVIDIA’s approach. They provide users with tools and allow them to program as they wish. This approach is more successful because it allows for adaptability. Despite the progress made by companies like Cerebras, Graphcore, and others, I believe too much time and effort is spent on developing prototypes of networks, rather than on creating tools that would allow users to do this work themselves.
Even now, I see companies building accelerators for the Transformer architecture. I would advise these companies to rethink their approach. They should aim for flexibility, ensuring that their architecture can accommodate changes. For instance, if we were to revert to recurrent nets in two years, their architecture should still be programmable.
Aparna: Thank you for your insights. Shifting gears, I’d like to talk about your work at Stability. It’s an impressive company with a thriving open-source community that consistently produces breakthroughs. We’ve observed the quality of the models and the possibilities with image generation. Many founders are creating companies using Stability’s models. So, my question is about the future of this technology. If a founder is building in this space and using your models as a foundation, where do you see this foundation heading? What’s the future of image generation technology at Stability?
Kamil: The potential of technology, particularly in the field of artificial intelligence, is immense. Currently, we’re seeing significant advancements in image generation models. The quality of these generated images is often astounding, sometimes creating visuals that are beyond reality, thereby accelerating creativity and content creation. We’re now extending this capability into 3D and video space. We’re actively working on models that can generate 3D scenes or objects and extend to video space. Imagine a scenario where you can generate a short clip of a dog running or even create an entire drama episode from a script.
We’re also developing audio models that can generate music. This can be combined with video generation to create a comprehensive multimedia experience. These applications have significant potential in the entertainment industry, from content generation for artists to the movie industry and game engine development.
However, I believe the real breakthrough will come when we move towards more industrial applications. If we can generate 3D representations and add video to that, we could potentially use this technology to simulate physical phenomena and accelerate R&D in the manufacturing space. For instance, generating an object that could be printed by a 3D printer. This could optimize and accelerate prototyping processes, potentially revolutionizing supply chains.
Recently, I was asked if a space rocket could be designed with generative AI. While it’s not currently feasible, the idea is intriguing and could potentially save a lot of money if we could solve complex problems using this technology.
In relation to hardware, I believe that generative AI and language models can be used to accelerate the discovery of new kinds of hardware and for generating code to optimize performance. With the increasing complexity and variety of models and architectures, traditional approaches to optimizing code and performance modeling are struggling. We need to develop more automated, data-driven approaches to tackle these challenges.
Aparna: You’ve broadened our understanding of the potential of generative AI. I’d like to delve deeper into the technical aspects. As the head of Performance Engineering at Stability, could you elaborate on the challenges involved in building systems that can generate video and potentially manufacture objects without error, performing exactly as intended?
Kamil: From a performance perspective, the issue of being limited by computational resources is closely related to the first question. At present, only a few companies can afford to innovate due to the high costs involved.
This situation might actually be beneficial as it could spark creativity. The scarcity of resources, particularly GPUs, could trigger innovations on the algorithmic side. I recall a similar situation in the early days of computer science when people were predicting faster clock speeds as the solution to performance issues. It was only when they hit a physical limit that they realized the potential of parallelization, which completely changed the way people thought about performance.
Currently, the cost of building a data center for training state-of-the-art language models is approaching a billion dollars, not including the millions of dollars required for training. This is not a sustainable situation. I miss the days when I could run models and prototype things on a laptop.
One of the main problems we face is that we’ve allowed our models to become so large, assuming that compute infrastructure is infinite. These larger models are becoming slower because more time is spent on moving data around rather than on the actual computation. For instance, when I was at Nvidia, anything below 90% of the so-called ‘speed of light’ was considered bad. However, in many cases, large language models only utilize about 30-40% of the peak performance that you can achieve on a GPU. This means a lot of compute power is wasted.
People often overlook this issue. When I suggest optimizing the code on a single GPU and running it on a small model before scaling up, many prefer to simply run it on multiple GPUs to make it faster. This lack of attention to optimization is a significant concern.
Aparna: As we wrap up, I’d like to pose a final question related to your experience at Neuralink, a company focused on brain-to-robot interaction. This technology has potential applications in assisting differently-abled individuals. Could you share your perspective on this technology? When do you anticipate it will be ready, and what applications do you foresee?
Kamil: My experience at Neuralink was truly an exciting adventure. I had the opportunity to work with a diverse team of neuroscientists, physicists, and biologists, all of whom were well-versed in computing and programming. Despite the initial intimidation, I found my place in this team and contributed to some groundbreaking work.
One of the primary challenges we aimed to address at Neuralink was the communication barrier faced by individuals whose cognitive abilities were intact, but who were physically unable to express themselves. This issue is exemplified by renowned physicist Stephen Hawking, who could only communicate by typing messages very slowly using his eyes.
Our initial project involved training macaque monkeys to play a Pong game while simultaneously feeding data from their motor cortex. This allowed us to decode brain signals and enable the monkeys to control something on the screen. Although it may not seem directly related to human communication, this technology could potentially be used to control a cursor and type messages, thus bypassing physical limitations.
We managed to measure the information transfer rate from the brain to the machine in bits per second, achieving a rate comparable to that of people typing on their cell phones. This was a significant milestone and one of the first practical applications of our technology. It could potentially benefit individuals who are paralyzed due to spinal injuries, enabling them to communicate despite their physical limitations.
However, our work at Neuralink wasn’t limited to decoding brain signals and reading data. We also explored the possibility of stimulating brain tissue to induce physical movements or visual experiences. This bidirectional communication could potentially allow individuals to interact with computers more efficiently, bypassing the need for physical input devices. It could even pave the way for a future where VR goggles are obsolete, as we could stimulate the visual cortex directly. However, the safety of these techniques is still under investigation, and it’s crucial that we continue to prioritize this aspect as we push the boundaries of what’s possible.
There’s a significant spectrum of disorders that this technology could address, particularly for individuals who struggle with mobility or communication. We were also considering mental health issues such as depression, insomnia, and ADHD. One of the concepts we were exploring is the ability to read data from the brain, identify its state, and stimulate it. This could potentially serve as a substitute for medication or other forms of treatment.
However, it’s important to note that the technology, while progressing, is not entirely clear-cut. The safety aspect is crucial and cannot be ignored. At Neuralink, we’ve done a remarkable job ensuring that everything we develop is safe, especially considering these devices are implanted in someone’s head.
When we consider brain stimulation, we must also consider potential negative scenarios. For instance, if we stimulate a certain region of the brain to alleviate depression, we could inadvertently create a dependency, similar to injecting dopamine. This could potentially lead to a loop where the individual becomes addicted to the stimulation. It’s a complex issue that requires careful consideration and handling.
In addressing these challenges, we’ve engaged in extensive conversations with physicians, neuroscientists, and other experts. While some companies may have taken easier paths, potentially compromising safety, we’ve chosen a more cautious approach. Despite the slower progress, I can assure you that whatever we produce will be safe. This commitment to safety is something I find particularly impressive.
Kamil: For those interested, it’s worth noting that Neuralink is currently hiring. They’ve recently secured another round of funding and are actively seeking new talent. This is indeed a glimpse into the future of technology.
Aparna: Earlier, you mentioned an intriguing story about monkeys and reading their brainwaves. This story is related to the AI that’s been implanted in their brains and how it communicates. Could you elaborate on what happens with the models in this context?
Kamil: In our initial approach to decoding brain signals, we utilized a simple model. We had a vector of 1024 electrodes and our goal was to infer whether the monkey was attempting to move the cursor up, down, or click on something. We used static data from what we termed a pre-training session, which was essentially data recorded from the implant. The model was a two-layer perceptron, quite small, and could be trained in about 10 seconds. However, the brain’s signal distribution changes rapidly, so the model was only effective for about 10 to 15 minutes before we observed a degradation in performance. This necessitated the collection of new data and retraining of the model.
Recently, Neuralink has started exploring reinforcement learning-based approaches, which allow for on-the-fly identification and retraining of the model on the implant. During my time at Neuralink, my focus was primarily on the inference side. We trained the model outside the implant, and my role was to make the inference parts work on the implant. This was a significant achievement for us, as we were previously sending data out and back in. Given our battery limitations, performing tasks on the implant was more cost-effective. The ultimate goal was to move the entire training process to the implant.
Every day, our brains produce varying signals due to changes in our moods and environments. These factors could range from being in a noisy place, feeling tired, or engaging in different activities. This results in a constantly shifting distribution of brain signals, which presents a significant challenge. This phenomenon is not only applicable to the brain but also extends to other applications in the medical field.
Aparna: We’ve discussed a wide range of topics, from hardware design to image and video generation, and even brainwaves and implant technology. Thank you so much for these perspectives Kamil!
Thank you to Kamil for his perspectives on these exciting AI topics. To read more about Pear’s AI focus and previous Perspectives in AI talks, visit this page.
Here at Pear, we specialize in backing companies at the pre-seed and seed stages, and we work closely with our founders to bring their breakthrough ideas, technologies, and businesses from 0 to 1. Because we are passionate about the journey from bench to business, we created this series to share stories from leaders in biotech and academia and to highlight the real-world impact of emerging life sciences research and technologies.This post was written by Pear Partner Eddie and Pear PhD Fellow Sarah Jones.
Today, we’re excited to share insights from our discussion with Dr. James Zou, Assistant Professor of Biomedical Data Science at Stanford University, who utilizes Artificial Intelligence (AI) and Machine Learning (ML) to improve clinical trial design, drug discovery, and large-scale data analysis. We’re so fortunate at Pear to have James serve as a Biotech Industry Advisor for us and for our portfolio companies.
James received his Ph.D. from Harvard in 2014 and was a Simons Research Fellow at UC Berkeley. Prior to accepting a position at Stanford, James worked at Microsoft and focused on statistical machine learning and computational genomics. At Stanford, his lab focuses on making new algorithms that are reliable and fair for a diverse range of applications. As the faculty director of the Stanford AI for Health program, James works across disciplines and actively collaborates with both academic labs and biotech and pharma.
If you prefer listening, here’s a link to the recording!
Key Takeaways:
1. James and his team employed generative AI not only to predict novel antibiotic compounds, but also to produce a facile ‘recipe’ for chemical synthesis, representing a new paradigm of drug discovery.
Antibiotic discovery is challenging for at least a couple of reasons: reimbursement strategies do not incentivize companies to pour resources, time and money into R&D, and antibiotic resistance has made it difficult to create lasting, efficacious products. To accelerate discovery and meet the critical need for new antibiotics, James and his team created a generative AI algorithm that could generate small molecules that were predicted to have high activity. Not only could the model generate chemical structures, but it could also produce the instructions for chemists to make these compounds. By streamlining the process from structure generation to synthesis, James and his team were able to identify a potent antibiotic for pathogens that have developed resistance to existing antibiotics.
These ‘recipes’ that the algorithm generated laid out step-by-step instructions for over 70 lead compounds. After synthesizing and testing the molecules, they found that they achieved a hit rate above 80% and could synthesize 58 novel compounds. Of these 58, they found that six were validated as promising drug candidates. In addition, the model prioritized hits that had robust synthetic protocols and were predicted to have low toxicity. In this way, the model could prioritize certain small molecule features and generate both novel structures and complete recipes.
The generative model in this case used a Monte Carlo Tree search to come up with recipes for new small molecules. The same logic flow and reasoning can easily be applied to other settings. For example, James and his team are working with Stanford spin-outs to apply the algorithm to other diseases such as fibrosis or for applications requiring new fluorescent molecules.
I think it’s a good, reasonable model for AI and biotech in general to have this close feedback loop, where we start off with some experimental data. In our case, we have some experimental screening data, the actual data used to train the models, and then the model will produce some candidates or some hypotheses. Then we tried to have a more rapid turnaround to do the additional experiments … to further validate the AI’s reasoning and thinking.
2. James’ group has also used generative AI to design clinical trials that aim to be faster, cheaper, more diverse, and more representative.
Clinical trials are a critical bottleneck in the pipeline of therapeutic development. Patient enrollment is slow and labor intensive, and trial design can be biased against underrepresented groups or may exclude patients left out based on criteria that don’t necessarily relate to trial outcome or patient response. To outline trial criteria, a ‘monstrosity’ of a document must be generated to explicitly lay out the rules that will be followed in patient recruitment.
James noted that it’s very hard to balance all of the complicated factors required for a successful trial design. With collaborators at Genentech, James and his team have worked to develop a Generative AI algorithm called Trial Pathfinder that uses historical clinical trials and outcomes to create an optimized trial design, often including a more diverse patient population. Among groups that see more representation and inclusion in AI-generated clinical trials are women, elderly patients, patients from underrepresented groups, and patients who might be a bit sicker. These patients often end up responding just as well without experiencing the predicted adverse events.
When James first started partnering with Genentech, his first goal was to understand the pain points in clinical trial design. He learned that many trials are actually very narrow and essentially recruit for the so-called “Olympic athletes” of patients. He noted one study actually did try to recruit Kobe Bryant and several Olympians. To make clinical trial outcomes more inclusive and representative of a diverse range of patients, one strategy is the use of algorithms that account for such biases.
If we look more closely at how people design the protocols for clinical trials, often it is based on domain knowledge. But it’s also often quite heuristic and anecdotal, which is why a lot of different teams from different pharma companies–even if they’re looking at drugs of similar mechanisms–often end up with quite different trials and trial designs.
3. AI/ML in biology is only possible because biology is becoming increasingly data driven.
The data that we can gather from biological systems is becoming more and more rich and diverse. For example, high resolution spatial transcriptomics or single molecule experiments can now be captured alongside more traditional measurements such as RNA sequencing. Perturbation of biological systems with CRISPR/Cas-9 technology also enables a whole new suite of data that represents an area ripe for AI.
Even in the past year, James noted that he has seen tremendous advances in large language models and foundation models on the AI side. It’s also been interesting to see how these advances have enabled new insights in the biotech space. For example, high-throughput perturbation data collected at the single-cell resolution is something that can be extremely compatible with large language models. So far, collaborative efforts between AI and biotech have been extremely fruitful.
As a professor, James and his lab are always pursuing new and exciting research directions. In particular, one project that he’s excited about is fueled by recent progress in spatial biology. As we’ve seen interest skyrocket in single-cell transcriptomics and genomics, researchers have generated huge amounts of data that have led to a variety of different findings and results. However, single cells also reside in different neighborhoods, or local microenvironments. Understanding disease and healthy states in the context of groups of cells may unlock even more insight into how patients may respond to therapies.
Another promising direction James highlighted was the use of large language models to allow researchers to synthesize and analyze information across biological databases. Currently, data is often siloed, and the level of expertise required to utilize individual data sets makes it challenging to work across fields and specialties.
“But this is where we think that language models can really be a unifying framework that can then help us to access data and integrate data from all these different modalities on different knowledge bases. So that’s another thing we’re working on with my students.”
This is why we’re excited about techniques and ideas like large language models that harness data from different modalities, databases, and knowledge bases to help biomedical researchers make faster innovations.
4. Landmark results at the intersection of biology and engineering, such as the Human Genome Project and the discovery of Yamanaka factors for reprogramming stem cells, motivated James to pursue a career in academia and to start his lab at Stanford.
James always gravitated towards math and science and started his academic path with an undergraduate major in math. Although he didn’t start out with a focus in biology, he began spending a good deal of time at the Broad Institute during his time at Harvard. At that time, many great biotechnologists were working on projects like sequencing the human genome. James began to learn more about interesting problems at the intersection of AI and biotech.
As he learned about the discovery of Yamanaka factors for reprogramming induced pluripotent stem cells (iPSCs), James was fascinated by the idea that you could take these ‘biological computer programs’ and with only a few instructions, change the state of a cell. Essentially, the biological system became not just something you could study, but something you could engineer.
5. Translation of academic projects needs to happen thoughtfully in collaboration with the right partners.
Translation of academic projects can take a few different forms, and not every project is right for translation. James gave a few examples of projects that he knew could move beyond the Stanford campus. One project involved the development of an AI system for assessing heart disease based on cardiac ultrasound videos, or echocardiograms. Millions of these videos are collected each year in the US alone, so it’s one of the most routine and accessible ways to assess cardiovascular disease.
James and his students developed an AI system to help look at these videos and determine outcomes to help clinicians make more accurate diagnoses. Not only did the work result in two publications in the prestigious scientific journal, Nature, but it progressed to clinical trials.
James explained that he clearly sees the larger impact of his work; he wants not only to publish really good papers, but also to work closely with biotech and pharma companies or tech companies to ensure his findings and algorithms can actually impact human health. His focus on translation has led to at least four companies that have been spun out of his group.
“At least one of the things we are doing is developing these algorithms or coming up with some of these potential drug candidates, and to really take it to the next level, either as a viable drug, a platform, or a device that we can take to patients, is something often beyond the scope of an individual PhD.”
James enjoys leveraging the community and resources of the Chan-Zuckerberg Biohub, a non-profit initiative aimed at bringing together interdisciplinary leaders to advance our ability to observe and analyze biological systems. Opportunities and communities such as these played a large role in drawing James to the Bay Area. He has actively sought out projects through which he can collaborate with biotech and pharma, investors, and the start-up community.
At that point, it’s really important work. [Getting FDA approval] also requires more resources. That’s where it makes sense for us to have a company that is co-founded by my students. So, for us, in this case, it’s a perfect synergy between doing the early-stage research and development, developing the algorithms to the initial validations and then having the company take over and do the submissions and then do the scaling.
Get to know Dr. James Zou: the person behind the science
James and his wife love to take advantage of all the great outdoors in the Bay Area. Every week, they go on a hike and spend a lot of time swimming or biking. One thing people may be surprised to learn about James is that he used to moonlight as a theater and restaurant reviewer. When he was living in Europe, he would write reviews of movies or restaurants for local English-language newspapers.
For someone wanting to pursue a similar career to his, James says that it’s a very exciting time to be at the intersection of biology and AI. He encourages students in the space to develop a core technical strength in either field and then begin to explore the synergy between disciplines.
Automation opportunities from vertical software’s data gold mine mean it has never been a better time to create purpose-built operational tools for overlooked industries. Plus, our market map of AI-enabled vertical software new entrants.
Vertical software founders build applications across many industries but with a common mission: to empower expert operators and owners to streamline and grow their businesses with software purpose-built for their own industry.
Over the past decade, Pear has supported founders building powerful applications for industries ranging from supply chain (Expedock, Beyond Trucks), construction (Gryps, Miter, Doxel), energy (Aurora, Pearl Street) and insurance (Federato) to home services (Conduit), travel (JetInsight, Skipper), agriculture (FarmRaise, Lasso), real estate (Hazel) and live events (Chainpass) – and more. These companies and plenty of others we admire outside of our portfolio have created hundreds of billions of dollars in enterprise value for themselves and for their customers.
Today, with artificial intelligence capabilities easier than ever to deploy in B2B products, we think it has never been a better time to build vertical software that automates core aspects of customer operations.
Any new vertical software opportunity — any sector that is not well-served by purpose-built software for industry-specific workflows — now looks even more promising. And, many existing vertical software tools have a rare opportunity to ramp up ACVs, increase stickiness, and build a powerful moat.
To understand why we might be on the verge of a golden age of intelligently-automated vertical software, we’ll take a look at two problems: First, the ACV problem that has limited vertical software opportunities. Then, the defensibility problem afflicting new AI application entrants.
The ACV Problem
Vertical software companies often sell into fragmented industries with many small-to-medium businesses. These businesses operate on thin margins and have limited ability to pay for new operational software. Contract values – and therefore market size – for many verticals have historically been constrained, which means that many sectors remain underserved by purpose-built, cloud-based software.
Historically, vertical software companies have sought to increase the value of their customer relationships by adding bolt-on monetization features like payments or banking. Other vertical software companies have initially sold to the fragmented base of a sector and steadily added operational features to move upmarket to larger customers within their industry.
In either case, the fundamental margin structure of the end customer remains unchanged, and few vertical software companies can reliably claim to impact their customers’ profitability in a major way. A vertical software customer might love their software’s intuitive UI, centralized system of record, navigable scheduling tools, and modern payment processing system. But these benefits rarely reduce the customer’s overall operating cost in a significant way.
The Defensibility Problem
Despite the excitement over applications of large language models in late 2022 and early 2023, many initial products were dismissed as “thin wrappers” over an off-the-shelf model. Critics argued that these initial applications lacked product differentiation and long-term defensibility.
At Pear, we believe that proprietary data is one of the keys to a defensible AI application. Proprietary data behind B2B AI applications comes in three forms:
Many early tools built over groundbreaking LLMs offered no form of proprietary data. At best, some products built over lightly-adapted models offered bronze or silver-level data-based defensibility. But we’ve been on the hunt for game-changing applications that build an advantage in proprietary model-training data from the start.
The Vertical Software Data Gold Mine
Traditional vertical software products generate enormous amounts of gold-level data, capture substantial silver-level information, and often themselves aggregate bronze-level data within their products.
Customer business logic flows through vertical software features. From operational decisions and administrative record-keeping to sales and product performance, customers of vertical software deposit reams of data daily into a rich system of record.
The most impactful B2B applications in the next decade will rigorously structure, mine, and harness gold-level product-generated data to enable workflow automation for their end customers.
Any business process with decisions and steps encoded in a vertical software feature set will be a candidate for automation. We’re most excited about automation that enables faster information processing tied to sales growth or cost-saving opportunities for an end customer: instant diagnosis and repair commissioning for field technicians, predictive inventory capabilities embedded in B2B marketplaces, copilot-style knowledge bases that help small business owners understand the impact of every decision on their bottom line.
Automation across many business functions will mean that vertical software companies can finally impact their customers’ margin structure – and as a result, help these customers break any linear scaling trap they face when they otherwise expand their business.
Early entrants: A preliminary market map
We have seen a proliferation of promising AI-enabled vertical software products in a handful of sectors, and we are proud to be the earliest supporters of teams like Expedock, Pearl Street, Gryps, Hazel, and Federato.
Many initial intelligently automated vertical software products target the largest sectors of the economy (we’ve looked separately at the ecosystem of AI in healthcare companies here). We’ll update this market map over time, and we’re eager to include companies unlocking automation potential in industries that have seen fewer capable purpose-built tools in the past.
What we are looking for
We hope to support many more founders delivering on a new and bigger promise of vertical software. Standout teams that we currently support – or just simply admire – typically excel on a few dimensions:
They have an unfair data advantage.
They have identified substantial automation potential.
They can communicate their value without invoking AI.
We want to hear from you
If you share our conviction that we’re entering a new golden age of vertical software and you’re exploring startup ideas that help expert operators streamline and grow their businesses through intelligent automation, we would love to hear from you. Reach out at keith@pear.vc if you’re working on something impactful.