Last week, PearX S19 alum WindBorne Systems announced their $6M seed round led by Footwork Ventures and joined by Pear, Khosla Ventures, and others. We love WindBorne’s founding story as it embodies everything we believe at Pear about mission-driven, high perseverance founders.
I was lucky to meet the founders of WindBorne back in the spring of 2019, when they were undergraduate students at Stanford University. They showed up to my office hours with a balloon in tow, similar to the one pictured below.
Early prototype of a WindBorne balloon
I had no idea that the homemade-looking device was a low cost, highly durable weather balloon that could fly at a wide range of altitudes. They called this balloon ValBal for (Vent to sink, Ballast to rise).
We decided to partner with WindBorne for two reasons:
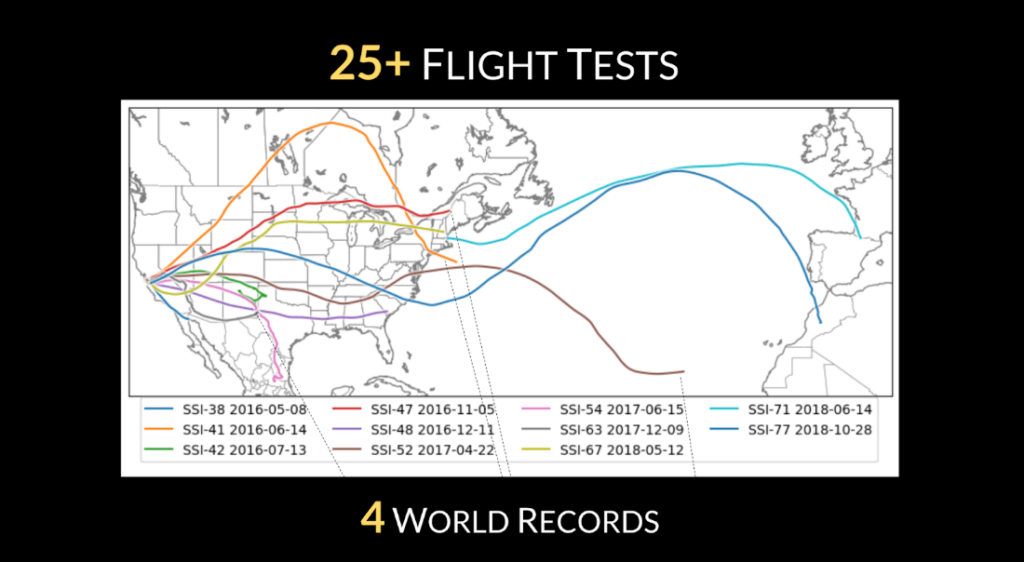
First, we believed in the founding team. They had demonstrated a clear mission, a strong passion, and an incredible ability to execute. They’d been addicted to this idea since they were freshman at Stanford as members of the Stanford Student Space Initiative. Constrained by a student budget, they used ingenuity and engineering to build weather balloons that would fly for a few hours and then pop. Over the years, they kept adding sensors and extending flight time, steadily improving their product. By the time I met them, they had already completed 26 test flights and broken four world records.
Map of flight tests the WindBorne team conducted while in college
Second, they were capturing data that no one else was capturing. At the time, we were not 100% sure of the value of such data, but after making a few calls, we discovered potential customers were interested in learning more about what the balloons could do.
WindBorne team testing balloons during their time at Stanford
With that, we invited WindBorne to join PearX’s Summer 2019 cohort, where we partnered closely with the founders to understand the most attractive market opportunity to go after. Through customer interviews, they discovered a massive data gap: only about 15% of the Earth’s surface has regular in-atmosphere observations, but weather is a global system. To better predict the weather, you need better weather data. Existing technologies couldn’t plug that gap, because the laws of physics prevent satellites from collecting the most critical weather observations. That’s where balloons come in: they’re able to collect data where satellites can’t.
Kai during PearX Summer 2019
Investors were convinced of the potential, and following S19 Demo Day, Windborne closed a successful seed round led by Khosla and Ubiquity Ventures. They spent the last four years growing the company: from iterating on their go-to-market strategy to team building to customer interviews to strategy sessions and more. We had the privilege to work side-by-side with John, Kai, Joan, Andre, and the entire WindBorne team every step of the way.
WindBorne team at PearX 2019 Demo Day
Last fall, the WindBorne team went out to begin raising their next round, in the midst of a tough economic climate. As PearX alums, we invited them to participate in our PearX S22 Demo Day, where Kai shared the latest happenings with thousands of investors in the Pear network. We’re so proud of the entire team for this next step in their journey.
PearX S22 Demo Day Presentation
I recently visited the new WindBorne HQ in Palo Alto, just a few weeks after the team moved in, and I left with a smile on my face. The offices were scrappy, the team was as determined as ever, and they were telling me all about the new advances with their product. I couldn’t help but look back and remember the first time they ever walked into my office as Stanford students and feel proud of how far they’ve come. I know this is just the beginning for WindBorne. We are so excited to continue to partner with them and to welcome Footwork and others to the team.
San Francisco and Los Angeles Tech Weeks are now complete, and we were excited to be a part of the celebration again this year! We hosted four events this year. Thank you to the founders and entrepreneurs who joined us at our events. Here’s a quick recap of our Tech Week events:
Hiring your first engineer
To kick us off, Pear’s Talent Partner Matt led a presentation and discussion on hiring your first engineer. Matt shared the strategy and process behind what hiring looks like for a first time founder – sharing advice and insight on timing, what to look for, and how to attract, find, assess and close your first hire.
Enterprise opportunities in generative AI
We pushed the capacity limits in our quaint SF office with nearly 100 guests for our Generative AI talk, led by Aparna. She presented on the latest trends, technologies, and applications in generative AI, specifically as it pertains to early founders.
The Gusto founding story
For our final SF Tech Week event, Pear’s Founding Managing Partner, Pejman, sat down with Gusto’s CEO and Co-founder, Josh Reeves. They discussed the journey building Gusto from the ground up into a platform for 300,000+ businesses that is worth $10B today. Josh’s biggest piece of advice is to always focus on the customer first and foremost.
What Apple Reality Pro means for XR
Last week we moved south for LA Tech Week, where Pear’s Partner Keith held a discussion in sunny Santa Monica exploring Apple Reality Pro and the ripple effects it will have on XR. It was great to meet so many XR founders, builders, and enthusiasts of the space!
Thanks to all who joined us for SF and LA Tech Weeks. We are so grateful to our community near and far!
Looking to connect with someone from the Pear team? Head over to our team page and feel free to reach out, we’d love to hear from you. If you’d like to join us at a future event, keep an eye on our events page.
Last month, I had the immense privilege of helping judge Pear VC’s Stanford student Competition. The event highlighted the brightest student founders from Stanford vying for their first check. The Pear Competition has a history of identifying and nurturing exceptional talent, supporting unicorn companies such as Viz.ai and other breakout companies including Nova Credit, Federato, Conduit Tech, and Wagr.
Pre-seed is a notoriously hard stage to invest, as startups often lack any metrics, product, traction, or proven revenue model. The excitement and challenge lies in the ability to identify hidden gems despite the uncertainty, requiring a skillset that combines intuition, experience, and a deep understanding of market landscapes across a wide range of industries.
With the invaluable experience of judging and doing diligence on close to 100 founders alongside renowned investors and proven operators, Mar Hershenson and Ilian Georgiev, I wanted to share 5 key takeaways in pre-seed investing from one of the best early-stage VCs:
1. Passion and Market Insight
Impressive founders had a deep understanding of their market, derived from a unique blend of professional experience, customer interviews, and thorough research. They could clearly pinpoint “hair on fire” problems and delve into pain points along the customer journey in excruciating detail, ultimately laying the foundation for a compelling vision for the problem they aim to solve.
These founders masterfully answered highly nuanced follow-up questions, while still demonstrating a humbling awareness of what they still needed to learn.
2. High Learning Rate
Another exciting key trait of founders was a demonstrated “high rate of learning”. These founders were unafraid to openly discuss assumptions and hypotheses that were proven wrong, providing insights into how their understanding of the market and potential solutions continually evolved. This grounded reflection illustrated their willingness to pivot when necessary, ensuring they could navigate the inevitable uncertainties of the startup journey.
3. Execution Velocity
Several founders stood out with their relentless drive to move fast. They leveraged no-code tools, pounded the pavement to connect with customers, and used smokescreen tests to gauge demand. These tenacious entrepreneurs consistently found ingenious, low-cost, and scrappy ways to rapidly test hypotheses, never allowing a single obstacle to halt their progress. They made do with what they had, not waiting on “ideal” resources or the “perfect team”.
4. Commitment
High commitment and perseverance was another trait we looked for in founders. Despite the glamour of eye-catching TechCrunch headlines, the reality is that the founder journey is an uphill marathon. Most startups must navigate the treacherous “pit of despair” for an average of 18 months before achieving product-market fit. A demonstrated ability to weather these upcoming challenging times after the initial excitement fades is a vital asset to tackle the inevitable hurdles of entrepreneurship.
Some of these founders had a history of starting previous businesses, often grappling with numerous setbacks and pivots. They could detail stories of struggles and challenges they faced in their founding journey, demonstrating a balance of grit and determination to continually refine their craft.
5. True Meaning of a “No”
Perhaps the most insightful lesson was that a “no” from a VC often does not mean that the founder or the business wasn’t exceptional. Many factors can contribute to a “no” despite an impressive company, such as a competing investment, the market size, or a mismatch with the VC’s sector focus. Founders often forget that building an outstanding business and securing funding from a specific VC are distinct pursuits. Never let a single “no” derail your founding journey. Embrace the challenge, learn from the feedback, and keep building. Success is not solely defined by the checks you secure but by the impact you create through the relentless pursuit of your vision.
In essence, the art of pre-seed investing lies in recognizing founders who possess a unique combination of passion, adaptability, and resilience. These entrepreneurs are driven by their vision and demonstrate an uncanny ability to navigate uncertainty, making them invaluable assets in the early-stage startup ecosystem, and proving that success is ultimately measured by the tenacity to transform a compelling idea into a lasting impact.
Guest post written by Alex Wu, a Pear Fellow at Stanford.
We’re excited to announce that Arpan Shah will be Pear’s newest Partner. A Visiting Partner for the last year, as well as former Robinhood founding engineer and founder of Flannel (acquired by Plaid), we couldn’t be more thrilled to have him permanently onboard.
An alumni of Pear Garage, Arpan has always embodied the people-first Pear ethos and now follows the operator-turned-investor journey. He will continue working on investments in his wheelhouse of Fintech, developer tools as well as data platforms and AI.
“I’m excited to find companies that have more innovative approaches that are both scalable and cost efficient in this world where more and more data will be used in more and more interesting ways.”
As a Visiting Partner, Arpan has supported portfolio companies at the intersection of Fintech, AI and Data. He’ll continue providing his expertise with PearX for AI (the first cohort of which is still open for applications).
“I really like working with founders who are trying to build companies that seem ridiculously hard. Those are the types of founders that I think are quite exciting, because they’re really motivated to not pursue small wins, but really make transformational change happen in an industry.”
We recently hosted a fireside chat on Generative AI with Nazneen Rajani, Robustness Researcher at HuggingFace. During the discussion, we touched on the topic of Open source AI models, the evolution of Foundation Models, and frameworks for model evaluation.
The event was attended by over 200 founders and entrepreneurs in our PearVC office in Menlo Park. For those who couldn’t attend in person, we are excited to recap the high points today (answers are edited and summarized for length). A short highlight reel can be also found here, thanks to Cleancut.ai who attended the talk.
Aparna: Nazneen, what motivated you to work in AI Robustness, could you share a bit about your background?
Nazneen: My research journey revolves around large language models, which I’ve been deeply involved in since my PhD. During my PhD, I was funded by the DARPA Explainable AI (XAI) grant, focusing on understanding and interpreting model outputs. At that time, I worked with RNNs and LSTMs, particularly in tasks involving Vision and language, as computer vision was experiencing significant advancements. Just as I was graduating, the transformer model emerged and took off in the field of NLP.
Following my PhD, I continued my work at Salesforce Research, collaborating with Richard Socher on interpreting deep learning models using GPT-2. It was fascinating to explore why models made certain predictions and generate explanations for their outputs. Recently, OpenAI published a paper using GPT4 to interpret neurons in GPT-2, which came full circle for me..
Currently, my focus is on language models, specifically on hallucination factuality, interpretability, robustness, and the ethical considerations surrounding these powerful technologies. I am currently part the H4 team at Hugging Face, working on building an open-source alternative to GPT, providing similar power and capabilities. Our goal is to share knowledge, artifacts, and datasets to bridge the gap between GPT-3-level models and InstructGPT or GPT-4, fostering open collaboration and accessibility.
Aparna: That’s truly impressive, Nazneen. Your background aligns perfectly with the work you’re doing at Hugging Face. Now, let’s dive deeper into understanding what Hugging Face is and what it offers.
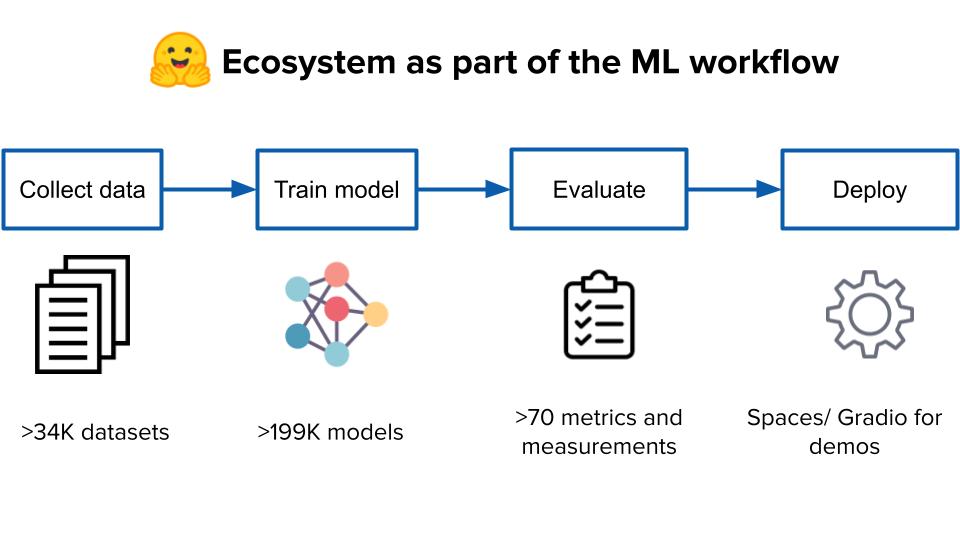
Nazneen: Hugging Face can be thought of as the “GitHub of machine learning.” It supports the entire pipeline of machine learning, making it incredibly accessible and empowering for users. We provide a wide range of resources, starting with datasets. We have over 34,000 datasets available for machine learning purposes. Additionally, we offer trained models, which have seen tremendous growth. We now have close to 200,000 models, a significant increase from just a few months ago.
In addition to datasets and models, we have a library called “evaluate” that allows users to assess model performance using more than 70 metrics. We also support deployment through interactive interfaces like Streamlit and Gradio, as well as Docker containers for creating containerized applications. Hugging Face’s mission is to democratize machine learning, enabling everyone to build their own models and deploy them. It’s a comprehensive ecosystem that supports the entire machine learning pipeline.
Aparna: Hugging Face has become such a vital platform for machine learning practitioners. But what would you say are the benefits of open-source language models compared to closed-source models like GPT-4.
Nazneen: Open-source language models offer several significant advantages. Firstly, accessibility is a key benefit. Open-source models make these powerful technologies widely accessible to users, enabling them to leverage their capabilities. The rate of progress in the field is accelerated by open-source alternatives. For example, when pivotal moments like the release of datasets such as RedPajama or LAION or the LLAMA weights occur, they contribute to rapid advancements in open-source models.
Collaboration is another crucial aspect. Open-source communities can come together, share resources, and collectively build strong alternatives to closed models. The compute is no longer a bottleneck for open source.. The reduced gap between closed and open-source models demonstrates how collaboration fosters progress. Ethical considerations also come into play. Open-source models often have open datasets and allow for auditing, risk analysis.
Open-source models make these powerful technologies widely accessible to users, enabling them to leverage their capabilities.
Aparna: Nazneen, your chart showing the various models released over time has been highly informative. It’s clear that the academic community and companies have responded strongly to proprietary models. Could you explain what Red Pajama is for those who might not be familiar with it?
Nazneen: Red Pajama is an open-source dataset that serves as the foundation for training models. It contains an enormous amount of data, approximately 1.5 trillion tokens. This means that all the data used to train the foundation model, such as the Meta’s LLaMA, is now available to anyone who wants to train their own models, provided they have the necessary computing resources. This dataset has made the entire foundation model easily accessible. You can simply download it and start training your own models.
Aparna: It seems that the open source community’s reaction to closed models, has led to the development of alternatives like Red Pajama. For instance, Facebook’s Llama had a restrictive license that prevented its commercial use, which triggered the creation of Red Pajama.
Nazneen: Absolutely, Aparna. Currently, powerful technologies like these are concentrated in the hands of a few, who can control access and even decide to discontinue API support. This can be detrimental to applications and businesses relying on these models. Therefore, it is essential to make such powerful models more accessible, enabling more people to work with them and develop them. Licensing plays a significant role in this context, as it determines the openness and usability of models. At Hugging Face, we prioritize open sourcing and face limitations when it comes to closed models. We cannot train on their outputs or use them for commercial purposes due to their restrictive licenses. This creates challenges and a need for accessible alternatives.
It is essential to make such powerful models more accessible, enabling more people to work with them and develop them.
Aparna: Founders often start with GPT-4 due to its capabilities and ease of use. However, they face concerns about potential changes and the implications for the prompt engineering they’ve done. The uncertainty surrounding access to the model and its impact on building a company is a significant worry. Enterprises also express concerns about proprietary models, as they may face difficulties integrating them into their closed environments and ensuring safety and explainability. Are these lasting concerns?
Nazneen: The concerns raised by founders and enterprises highlight the importance of finding the right model and ensuring it fits their specific needs. This is where Hugging Face comes in. Today, we are releasing something called “transformer agents” that address this very challenge. An agent is a language model that you can chat with using natural language prompts to define your goals. We also provide a set of tools that serve as functions, which are essentially models from our extensive collection of 200,000 models. These tools are selected for you based on the task you describe. The language model then generates the necessary code and uses the tools to accomplish your goal. It’s a streamlined process that allows for customization and achieving specific objectives.
Aparna: I learned from my experience with Kubernetes that open source software is great for innovation. However, it can lack reliability and ease of use unless there’s a commercial entity involved. Some contributions may be buggy or poorly maintained, and the documentation may not always be updated or helpful. To address this, Google Cloud hosted Kubernetes to make it more accessible. How does Hugging Face help me navigate through 200,000 models and choose the right one for my needs?
Nazneen: The Transformers Agents can assist you with that exact task. Transformer agents are essentially language models that you can chat with. You provide a natural language prompt describing what you want to achieve, and the agent uses a set of pre-existing tools, which are essentially different models, to fulfill your request. These tools can be customized or extended to suit specific goals. The agent composes these tools and runs the code for you, making it a streamlined process. For example, you can ask the agent to draw a picture of a river, lakes, and trees, then transform that image into a frozen lake surrounded by a forest. These tools are highly customizable, allowing you to achieve your desired outcomes.
Aparna: It feels like the evolution of what we’ve seen with OpenAI’s GPT plug-ins and Langchain’s work on chaining models together. Does Hugging Face’s platform automate and simplify the process of building an end-to-end AI application?
Nazneen: Absolutely! The open-source nature of the ecosystem enables customization and validation. You can choose to keep it in a closed world setting if you have concerns about safety and execution of potentially unsafe code. Hugging Face provides tools to validate the generated code and ensure its safety. The pipeline created by Hugging Face connects the necessary models seamlessly, making it a powerful and efficient solution.
Aparna: This aligns with our investment thesis and the idea of building applications with models tailored to specific workflows. Switching gears, what are some of the applications where you would use GPT-3 and GPT4?
Nazneen: GPT-3 can be used for almost any task. The key approaches are in-context learning and pre-training. These approaches are particularly effective for tasks like entity linking or extraction, making the model more conversational.
While GPT-3 performs well on traditional NLP tasks like sentiment analysis, conversational models like GPT-4 shine in their ability to engage in interactive conversations and follow instructions. They can perform tasks and format data in specific ways, which sets them apart and makes them exciting.
The real breakthrough moment for generative AI was not GPT-3. Earlier chatbots like Blenderbot from Meta and Microsoft’s chatbots existed but were not as popular due to less refined alignment methodologies. The refinement in approaches like in-context learning and fine-tuning has led to wider adoption and breakthroughs in generative AI.
Aparna: How can these techniques address issues such as model alignment, incorrect content, and privacy concerns?
Nazneen: Techniques like RLHF focus on hallucination and factuality, allowing models to generate “I don’t know” when unsure instead of producing potentially incorrect information. Collecting preferences from domain experts and conducting human evaluations can improve model performance in specific domains. However, ethical concerns regarding privacy and security remain unresolved.
Aparna: I do want to ask you about evaluation. How do I know that the model that I find tuned is actually good? How can I really evaluate my work?
Nazneen: Evaluation is key for a language model because of the stochasticity of the thing. Before I talk about evaluation, I want to first talk about the types of learning or training that goes into these language models. There are four types of learning.
The first is pre training, which is essentially building the foundation model.
The second is in-context learning or in-context training, where no parameters are updated, but you give the model a prompt, and describe a new task that you want the model to achieve. It can either be zero shot, or a few shots. And then you give it a new example. It learns in context.
The third one is supervised fine tuning, which is going from something like GPT3 to instruct GPT. So, you want this foundation model to follow instructions and chat with a human and generate outputs that are actually answers to what the person is looking for or being chatty and being open ended and also following instructions.
The fourth type of training is called reinforcement learning with human feedback. In this case, you first train a reward model based on human preferences. What people have done in the past is, have humans generate a handful of examples, and then ask something like chat GPT to generate more. That is how Alpaca came about and the self instruct data set came about.
For evaluating the first two types of learning, pre-training and in-context learning, we can use benchmarks like the big bench from Google, or the helm benchmarks from Stanford, which are very standard benchmarks of NLP tasks.
During supervised fine tuning, you evaluate for chattiness, whether the language model is actually generating open-ended answers, and also whether it’s actually able to follow instructions. We cannot use these NLP benchmarks here.
We also have to evaluate the reward model to make sure that it has actually learned the values we care about. The things that people generally train the reward model on are truthfulness, harmlessness, and helpfulness. So how good is the response in these dimensions?
Finally, the last part is the very interesting final way to evaluate is called Red Teaming, which comes in the very end. In this case, you’re trying to adversarially attack or prompt the model, and see how it does.
Aparna: What do you think are the defensible sources of differentiation in generative AI?
Nazneen: While generative AI is a crowded field, execution and data quality are key differentiators. Ensuring high-quality data and disentangling hype from reality are crucial. Building models with good data quality can yield better results compared to models trained on noisy data. Investing effort and resources into data quality is essential.
While generative AI is a crowded field, execution and data quality are key differentiators.
Aparna: Lastly, what do you see as the major opportunities for AI in enterprise?
Nazneen: Enterprise AI solutions have major opportunities in leveraging proprietary data for training models. One example is streamlining employee onboarding by automating email exchanges, calendars, and document reading. Workflows in platforms like ServiceNow and Salesforce can also be automated using large language models. The enterprise space offers untapped potential for AI applications by utilizing data and automating various processes.
This past December, Pear VC was proud to invest in Infinimmune’s $12M seed round. Infinimmune is reinventing antibody drug discovery by focusing solely on human-derived antibody drugs and mining the insights uniquely gathered from deep characterization of the functional antibody repertoire.Here, we reflect on the broader field of antibody-based therapeutics and why we are excited about Infinimmune’s team, technical approach, and vision.
Antibody drugs have made an undeniable impact on modern medicine.
Since the FDA’s first approval of a therapeutic monoclonal antibody in 1986, more than 160 marketed antibody drugs have been developed to treat various ailments including cancer, autoimmune disease, infectious disease, and more.
Seven of the top 20 best-selling drugs of 2022 were antibodies, including Humira, Keytruda, and Dupixent. Collectively, antibody sales that year likely topped $200B, roughly on par with the sales of Apple’s iPhone.
Antibodies play a central defensive role in the adaptive immune system. Recent decades have witnessed tremendous, hard-won advances in the science of these amazing molecular machines and in their application as research tools, diagnostic reagents, and therapeutics.
Scientists have deciphered their molecular structures; decoded many of the intricate genetic and cellular processes that create and select functional antibodies; devised a variety of sophisticated approaches to identify novel antibodies that effectively bind a given antigen; and developed the tools and processes to reliably characterize, manufacture, and distribute them at scale.
Newer therapeutic modalities that rely on antibodies or components of them for their function, such as antibody-drug conjugates, targeted radioligand therapies, bispecific T cell engagers, and CAR-T cells, have become established drug classes in their own right. And in recent years, in silico design techniques, aided by ML/AI, have been used to engineer antibodies with better binding, stability, and expression.
Despite all of this progress, our state of understanding regarding the vast diversity of the antibody repertoire actually produced in humans remains shockingly low.
Limitations in the characterization techniques previously applied to this diversity, estimated at 10^11 to 10^18 unique protein sequences in humans, have stymied efforts to fully understand and gain insights from it. Even the advent of next-generation sequencing has not deeply impacted this space—most studies of the antibody repertoire still rely on bulk sequencing technologies, which only capture half of most of the variable region of one antibody transcript at a time.
Why does this matter in antibody drug discovery?
Because every day, inside every human, the body conducts the equivalent of 100 billion antibody clinical trials, testing each antibody for safety and efficacy in parallel. And these techniques have been developed and optimized over 500 million years of evolution of the adaptive immune system.
For instance, by studying the immune reactivity of blood samples donated from adults living in a malaria-endemic region, researchers were able to identify broadly reactive antibodies that exhibited non-canonical features (Tan et al., Nature 529:105-109, 2016). These antibodies were found to contain a large insert of an extracellular LAIR1 domain located between key antibody segments. This domain, which is non-canonical and which was not observed in narrowly reactive antibodies, increased binding to malaria-infected red blood cells. These results demonstrated a novel mechanism of antibody diversification that the human immune system can use to create therapeutically effective antibodies.
Clearly, human B cells produce antibodies that mouse B cells and humanized mouse B cells do not. However, the most common methods for discovering therapeutic antibodies today rely on screening antibodies produced in transgenic mice that have been immunized with the desired target antigen, or panning for binding to the antigen in relatively shallow pools of engineered human antibody-like binders expressed via phage or yeast display.
These approaches are not capable of leveraging the unique insights that can be captured by studying functional antibodies produced by the human immune system.
Enter Infinimmune.
Infinimmune is a startup that is reinventing antibody drug discovery by focusing solely on human-derived antibody drugs.
Infinimmune was founded by Wyatt McDonnell, David Jaffe, Katie Pfeiffer, Lance Hepler, and Mike Gibbons, a multidisciplinary team of scientists and technologists. These founders have deep expertise in immunology, genomics, computational biology, single cell sequencing, and data analysis, and they take a first principles approach to therapeutics platform development as drawn from previous experiences at 10x Genomics, Pacific Biosciences, and the Broad Institute.
As an example of this expertise, Wyatt, David, and Lance co-authored a paper in Nature last year that discovered a new property of functional antibodies coined light chain coherence (Jaffe et al., Nature 611:352-357, 2022). In this work, the authors used single-cell RNA sequencing to determine the paired heavy and light chain antibody sequences from 1.6 million B cells from four unrelated humans and incorporated a total of 2.2 million B cells from 30 humans.
They compared antibody sequences from pairs of B cells that were isolated from different donors and which shared similar heavy chain segments, specifically, the same heavy chain V gene, and the same amino acid sequence for a key antigen-binding region called CDRH3. [Note: an antibody is composed of a pair of one heavy chain and one light chain that are generated through a process of sequential gene recombination involving V, D (for heavy chains), J, and C segments.]
The authors found evidence of previously unrecognized determinism in the light chain segment (i.e. light chain V gene) used in functional antibodies, which were derived from memory B cells, as opposed to naive antibodies. The discovery of light chain coherence suggests that the sequence space for the light chain of a functional antibody, which has undergone selection by the human immune system to be useful, safe, and effective, is more restricted than what was previously believed. It also carries important implications for the design of therapeutic antibodies, transgenic platforms, and diversification strategies of antibody drugs.
With these types of capabilities and insights at hand, Infinimmune is developing an end-to-end platform to deliver antibody drugs derived directly from the human immune system.
These truly human antibodies are designed to drug new targets with improved safety and efficacy. Infinimmune is building its own pipeline of drug candidates while also aiming to partner with pharma companies to expand treatment options and reach more patients.
This past December, we were proud to co-invest alongside our friends at Playground Global, Civilization Ventures, and Axial in Infinimmune’s $12M seed round. We are delighted to work closely with the Infinimmune team, and we look forward to sharing many exciting updates to come. Infinimmune’s new HQ is in Alameda, and their team is always interested in hearing from smart, curious, and passionate scientists with a track record of innovation and building things from scratch. If you want to build better drugs for humans, from humans, you can reach the founders directly at founders@infinimmune.com or careers@infinimmune.com—there’s no better way to get in the hiring queue before more job postings go live in 2023!
We kicked off this week with the announcement of our 4th seed stage fund, one of the largest of its kind, raising $432M to seed the next generation of startups. Today we are thrilled to announce a dedicated Artificial Intelligence startup package, PearX for AI, which offers each founding team $250K in cloud credits, access to beta APIs, expanded check sizes up to $5M, 1:1 expert technical advice, customer introductions, AI talent matching and a curated community of AI practitioners who connect and learn from each other. Applications are open now through June 10th.
PearX for AI, is dedicated to the most ambitious technical founders, interested in building groundbreaking applications, tooling and infrastructure to power the Artificial Intelligence driven revolution. This program provides the resources, expertise, and customer connections you need to build the future.
Who should apply?
PearX for AI will be a small tight-knit community with up to 10 startups selected into our inaugural summer batch. Pear specializes in working deeply with our portfolio companies to solve the most challenging problems startups face during the 0 to 1 journey from idea to product market fit. No idea is too early or too controversial. The program requires technical depth with a focus in AI, and the application process is tailored towards CS / Engineering graduates, PhDs, researchers and other technical professionals who have built AI driven applications in the past. We look for a combination of market knowledge, technical strategy and coding skills. The program will further build upon these skills and help round out your team’s capabilities in any areas that may need support. It will also connect you with Pear’s community of AI entrepreneurs.
Artificial Intelligence is a horizontal technology with the potential to impact many industries. We believe generative AI is a game-changer for consumer, social and enterprise applications. Particularly Healthcare, Legal, Financial Services, Retail, Logistics, Fashion, Design, Media, Gaming, Manufacturing, Energy, Industrial and Biotechnology to name a few verticals ripe for AI innovations. Pear’s AIteam is especially skilled in enterprise AI adoption and will work with exceptional founders to craft solutions for the most pressing enterprise needs.
We are deep technologists ourselves and value founders working on next generation Natural Language Understanding, Image generation, Computer Vision, Protein and Molecular synthesis and Robotics and Simulation technology. We have experts focused on applications of AI to developer tooling, open source software, sales, support, HR, R&D, design and education. We are bullish on infrastructure software, data services, and tools that reimagine the tech-stack for optimal AI performance.
What benefits will I receive?
Pear’s AI track comes with $250K in cloud credits, early access to new APIs and models, technical support from practitioners, mentorship from specialist AI experts, enterprise customer introductions, access to a talented and like-minded community, and an extended virtual cohort of AI founders. Pear will also extend larger check sizes for AI startups that require additional upfront investment, and provide introductions to strategic angel investors. Finally Pear will prepare all founders in the program for Series A fundraising. Our programs have an 87% success rate for series A and beyond investment by top tier funds.
Why now?
We’re living in an era of unprecedented technological advancement. AI is re-shaping our present and enabling some of the most significant breakthroughs of our lifetimes. The pace of this technological shift is breathtaking. The last time we witnessed a transformation of this nature was in 2000 with web technologies. There was a bubble then, just as there is significant hype around Generative AI now, but from it emerged breakout companies like Google, VMware, Salesforce and more. Breakout companies will be built now in this similar environment.
What does this mean for founders? Opportunity! There has never been a better time to start a company, but navigating the hype and shifting landscape that surrounds technical breakthroughs that are still in progress, requires expertise, judgment, and partners who will tell you hard truths and stand steady through difficult times, helping you secure the resources required – both financial and human.
Why Pear?
We have been investing in AI startups for several years and have a portfolio of AI powered companies that span verticals including consumer social, gaming, retail, healthcare, fintech, insurance, property technology, infrastructure, databases, deep tech, and more.
With PearX for AI, we have pulled together the resources, community, and expertise to help founders discern signal from noise and succeed in building industry defining companies using the latest breakthroughs in Generative AI. The first track of PearX for AI is set to start in July, with a small cohort of founders who have a proven track record in applying AI to real-world problems. If you’re ready to take on this challenge and shape the future with AI, we invite you to apply now here. Let’s build the future together!
10 years ago, we started what is now Pear VC under the name Pejman and Mar Ventures. But the story dates even further back to 2009, when Pejman approached me with the goal to build a fund that serves world class entrepreneurs and supports their efforts with know-how, network, and capital. Pejman had a clear vision to build a seed stage firm with a true legacy: one that would be talked about in the history books.
By that time, Pejman had established himself as a savvy angel investor, and he even backed some of my own startups. When setting out to start a fund, he wanted to partner with someone that had a complementary skillset: while Pejman had over ten years of experience investing, I had founded three companies. It was a great match, but I was initially pretty reluctant to dive into the world of venture. Pejman, like any great founder, did not give up. He spent four years trying to convince me, and ultimately the two of us agreed to set out and raise an initial seed fund in 2013. Raising our first fund was not easy. After all, neither of us had any venture experience and we did not fit the mold of typical VCs. After facing a series of no’s, a few brave LPs put their trust in us, and we were off to the races with a $50M seed fund.
Me and Pejman in Pear’s first office in Palo Alto in 2013.
So here we are, 10 years later. We are incredibly proud of how far we have come, but we’re also well aware of how much lies ahead of us. Over the last decade, we’ve seeded over 150 companies including marquee companies like DoorDash (NSDQ: DASH), Guardant Health (NSDQ:GH), Senti Bio (NSDQ: SNTI), Aurora Solar, Gusto, Branch, Affinity, Vanta, Viz.ai and many more.
Although we have come a long way since 2013, our DNA has not changed. Perseverance, can-do mentality, collaboration, service, and legacy remain the pillars of our fund.
The team has grown quite a bit. We now have a world class team of 26 (and growing!) Pear team members. Our investment team brings deep expertise across our vertical areas – from consumer to biotech to fintech to AI and beyond. We’ve also invested our resources in building a best-in-class platform team, with extensive backgrounds in company building – from talent to GTM to marketing and more.
Pear’s amazing team in our Menlo Park HQ.
Just like on day one of Pear, we are at the service of our founders. When we partner with a company, we are an extended member of their team and we do whatever it takes to help them be successful. We tell founders to think of us as “Ocean’s Eleven”: we’re a unique cast of colorful characters, with specific skills, a common plan, and coordinated execution. In fact, coordinated collaboration is at the heart of what we do.
We remain as optimistic as day one. Over the last decade of building Pear, we have witnessed the market go through its fair share of ups and downs. Despite the current economic downturn, we firmly believe that there is no better time to invest at the seed stage. The market is teeming with exceptional talent starting companies, the advent of AI is propelling company building at an unprecedented pace, and sales and marketing can be done at scale with fewer resources. In light of these factors, we are confident that the next wave of iconic companies will emerge from this downturn, and we are looking forward to being their initial backers.
This week, we celebrate raising our fourth fund at $432 million, but we know that fundraising is just one milestone. We have our eyes set on the decades that lie ahead, and we are already hard at work building new initiatives that will help us deliver on our promise to back and support early-stage companies.
Since day one, we’ve built Pear on this belief that people truly make the difference. We are deeply grateful to our LPs and to our founders who put their faith in us as partners every day.
We look forward to building the future of tech with Pear Fund IV. We couldn’t be more excited for the next decade of Pear!