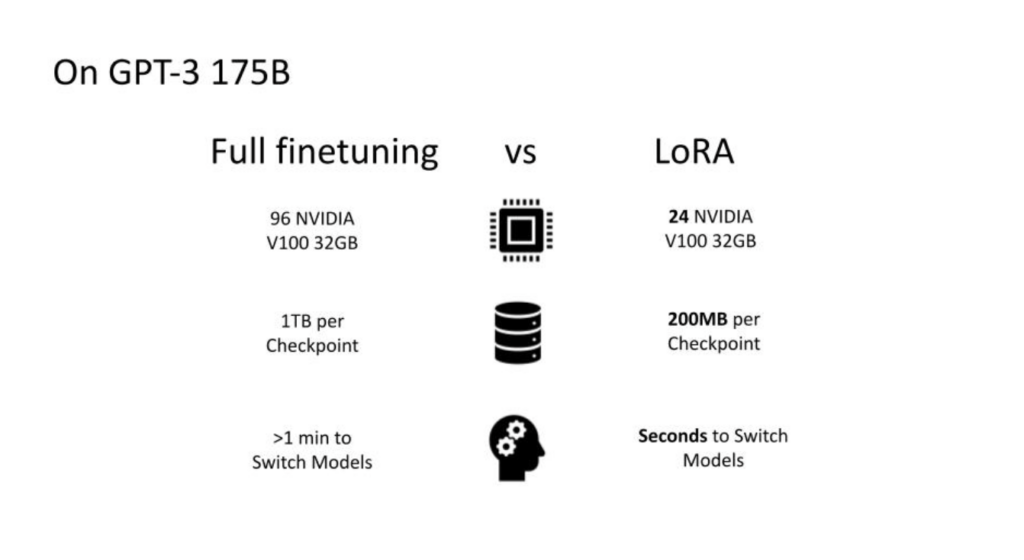
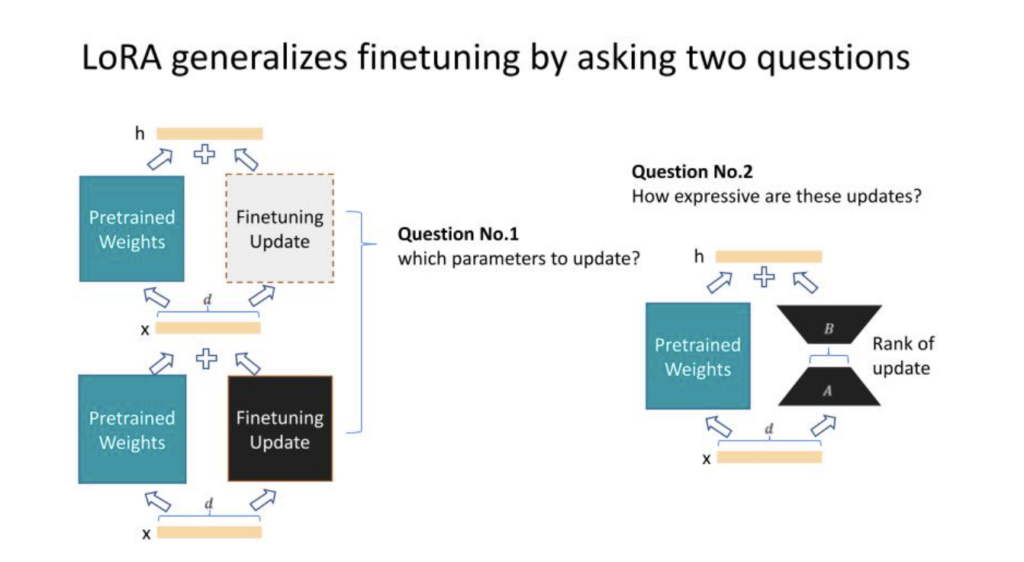
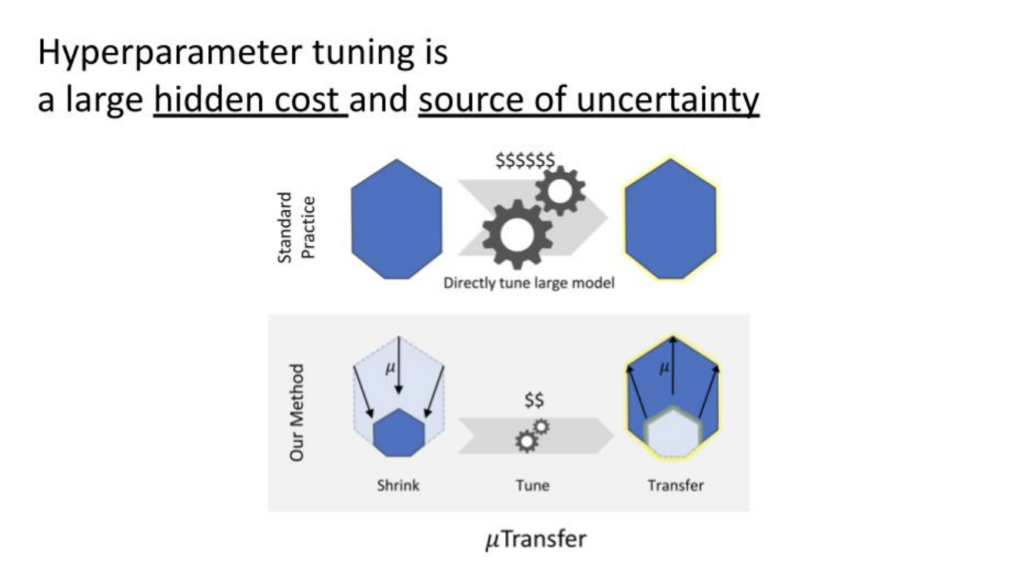
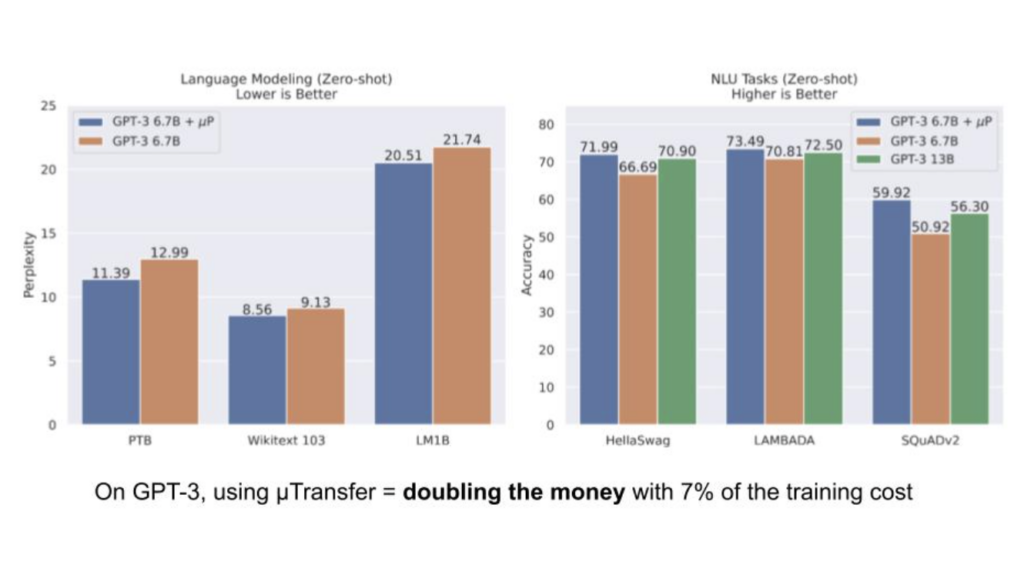
At Pear, we recently hosted a Perspectives in AI fireside chat with Kamil Rocki, Head of Performance Engineering at Stability AI. We discussed breakthroughs at the hardware-software interface that are powering generative AI. Kamil has extensive experience with GPU hardware and software programming from his PhD research and his work at IBM, Nvidia, Cerebras, Neuralink, and of course now StabilityAI. Read a recap of that conversation below:
Aparna: Kamil, thank you for joining us. You’ve accomplished many amazing things in your career, and we’re excited to hear your story. How did you choose your career path and what led you to work on the projects you’ve been involved with?
Kamil: My journey into the world of technology began in my 20s. After a few years of rigorous mathematical studies, I found myself in a robotics lab. I was tasked with enabling a robot to solve a Rubik’s cube. The challenge was to detect the cube’s location in an image captured by a camera, and this had to be done at a rate of 100 frames per second.
I was intrigued by the work my peers were doing in computer graphics using Graphics Processing Units (GPUs). They were generating landscapes and waves, manipulating lighting, and everything was happening in real-time. This inspired me to use GPUs to process the images for my project.
The process was quite challenging. I had to learn OpenGL from my friends, write images to the GPU, apply a pixel shader, and then read data back from the GPU. Despite the complexity, I was able to exceed the initial goal and run the process at 200 frames per second. I even developed a primitive version of a neural network that could detect the cube’s location in the image.
In 2008, around the time I graduated, CUDA came out and there was a lot of excitement around GPUs. I wanted to continue exploring this field and heard about a supercomputer being built in Japan based on GPUs and ended up doing a PhD in supercomputing. During this time, I worked on an algorithm called Monte Carlo Tree Search, deploying it on a cluster of 256 GPUs. At that time, not many people were familiar with GPU programming, which eventually led me to the Bay Area and IBM Research in Almaden.
I spent five years at IBM Research, then moved to the startup world. I had learned how to build chips, design computer architecture, and build computers from scratch. I was able to go from understanding the physics of transistors to building a software stack on top of that, including an assembler, compiler, and programming what I had built. One of my goals at IBM was to develop a wafer scale system. This led me to Cerebras Systems, where I co-designed the hardware. Later I joined Neuralink and then Nvidia, where I worked on the Hopper architecture. I joined Stability, as we are currently in a transition to Hopper GPUs. There is a significant amount of performance work required, and with my extensive experience with this architecture, I am well-equipped to contribute to this transition.
Aparna: GPUs have become one of the most profitable segments of the AI value chain, just looking at Nvidia’s growth and valuation. GPUs are also currently a capacity bottleneck. How did we arrive at this point? What did Nvidia, and others, do right or wrong to get us here?
Kamil: Nvidia’s journey to becoming a key player in the field of artificial intelligence is quite interesting. Initially, Nvidia was primarily known for its Graphics Processing Units (GPUs), which were used in the field of graphics. A basic primitive in graphics involves small matrix multiplication, used for rotating objects and performing various view projection transformations. People soon realized that these GPUs, efficient at matrix multiplications, could be applied to other domains where such operations were required.
In my early days at the Robotics Lab, I remember working with GPUs like the GeForce 6800 series. These were primarily designed for graphics, but I saw potential for other uses. I spent a considerable amount of time writing OpenGL code to set up the entire pipeline for simple image processing. This involved rasterization, vertex shader, pixel shader, frame buffer, and other complex processes. It was a challenging task to explore the potential of these GPUs beyond their conventional use.
Nvidia noticed that people were trying to use GPUs for general-purpose computing, not just for rendering images. In response, they developed CUDA, a parallel computing platform an application programming interface model. This platform significantly simplified the programming process. Tasks that previously required 500 lines of code could now be achieved with a program that resembled a simple C program. This opened up the world of GPU programming to a wider audience, making it more accessible and flexible.
Around 2011-12, the ImageNet moment occurred, and people realized the potential of scaling up with GPUs. Before this, CPUs were the primary choice for most computing tasks. However, the realization that GPUs could perform the same operations on different data sets significantly faster than CPUs led to a shift in preference. This was particularly impactful in the field of machine learning, where large amounts of data are processed using the same operations. GPUs proved to be highly efficient at performing these repetitive tasks.
This realization sparked a self-perpetuating cycle. As GPUs became more powerful, they were used more extensively in machine learning, leading to the development of more powerful models. Nvidia continued to innovate, introducing tensor cores that further enhanced machine learning capabilities. They were smart in making their products flexible, catering to multiple markets including graphics, machine learning, and high-performance computing (HPC). They supported FP64 computation, graphics, and tensor cores, which could be used for ray tracing and FP64. This adaptability and flexibility, combined with an accessible programming model, is what sets Nvidia apart in the field.
In the span of the last 15 years, from 2008 to the present, we have seen a multitude of different architectures emerge in the field of machine learning. Each of these architectures was designed to be flexible and adaptable, capable of being executed on a GPU. This flexibility is crucial as it allows for a wide range of operations, without being limited to any specific ones.
This approach also empowers users by not restricting them to pre-built libraries that can only run a single model. Instead, it provides them with the freedom to program as they see fit. For instance, if a user is proficient in C, they can utilize CUDA to write any machine learning model they desire.
However, some companies have lagged behind in this regard. Their mistake was in not providing users with the flexibility to do as they please. Instead, they pre-programmed their devices and assumed that certain architectures would remain relevant indefinitely. This is a flawed assumption. Machine learning architectures are continuously evolving, and this is a trend that I foresee continuing into the future.
Aparna: Could you elaborate more on the topic of special purpose chips for AI? Several companies, such as SambaNova Systems and Cerebras, have attempted to develop these. What, in your opinion, would be a successful architecture for such a chip? What would it take to build a competitive product in this field? Could you also shed some light on strategies that have not worked well, and those that could potentially succeed?
Kamil: Reflecting on my experience at Cerebras Systems, I believe one of the major missteps was the company’s focus on building specialized kernels for specific architectures. For instance, when ResNet was introduced, the team rushed to develop an architecture for it. The same happened with WaveNet and later, the Transformer model. At one point, out of 500 employees, 400 were kernel engineers, all working on specialized kernels for these architectures. The assumption was that these models were fixed and optimized, and users were simply expected to utilize our library without making any changes.
However, I believe this approach was flawed. It did not take into account the fact that architectures change frequently. Every day, new research papers are published, introducing new models and requiring changes to existing ones. Many companies, including Cerebras, failed to anticipate this. They were so focused on specific architectures that they did not consider the need for flexibility.
In contrast, I admire NVIDIA’s approach. They provide users with tools and allow them to program as they wish. This approach is more successful because it allows for adaptability. Despite the progress made by companies like Cerebras, Graphcore, and others, I believe too much time and effort is spent on developing prototypes of networks, rather than on creating tools that would allow users to do this work themselves.
Even now, I see companies building accelerators for the Transformer architecture. I would advise these companies to rethink their approach. They should aim for flexibility, ensuring that their architecture can accommodate changes. For instance, if we were to revert to recurrent nets in two years, their architecture should still be programmable.
Aparna: Thank you for your insights. Shifting gears, I’d like to talk about your work at Stability. It’s an impressive company with a thriving open-source community that consistently produces breakthroughs. We’ve observed the quality of the models and the possibilities with image generation. Many founders are creating companies using Stability’s models. So, my question is about the future of this technology. If a founder is building in this space and using your models as a foundation, where do you see this foundation heading? What’s the future of image generation technology at Stability?
Kamil: The potential of technology, particularly in the field of artificial intelligence, is immense. Currently, we’re seeing significant advancements in image generation models. The quality of these generated images is often astounding, sometimes creating visuals that are beyond reality, thereby accelerating creativity and content creation. We’re now extending this capability into 3D and video space. We’re actively working on models that can generate 3D scenes or objects and extend to video space. Imagine a scenario where you can generate a short clip of a dog running or even create an entire drama episode from a script.
We’re also developing audio models that can generate music. This can be combined with video generation to create a comprehensive multimedia experience. These applications have significant potential in the entertainment industry, from content generation for artists to the movie industry and game engine development.
However, I believe the real breakthrough will come when we move towards more industrial applications. If we can generate 3D representations and add video to that, we could potentially use this technology to simulate physical phenomena and accelerate R&D in the manufacturing space. For instance, generating an object that could be printed by a 3D printer. This could optimize and accelerate prototyping processes, potentially revolutionizing supply chains.
Recently, I was asked if a space rocket could be designed with generative AI. While it’s not currently feasible, the idea is intriguing and could potentially save a lot of money if we could solve complex problems using this technology.
In relation to hardware, I believe that generative AI and language models can be used to accelerate the discovery of new kinds of hardware and for generating code to optimize performance. With the increasing complexity and variety of models and architectures, traditional approaches to optimizing code and performance modeling are struggling. We need to develop more automated, data-driven approaches to tackle these challenges.
Aparna: You’ve broadened our understanding of the potential of generative AI. I’d like to delve deeper into the technical aspects. As the head of Performance Engineering at Stability, could you elaborate on the challenges involved in building systems that can generate video and potentially manufacture objects without error, performing exactly as intended?
Kamil: From a performance perspective, the issue of being limited by computational resources is closely related to the first question. At present, only a few companies can afford to innovate due to the high costs involved.
This situation might actually be beneficial as it could spark creativity. The scarcity of resources, particularly GPUs, could trigger innovations on the algorithmic side. I recall a similar situation in the early days of computer science when people were predicting faster clock speeds as the solution to performance issues. It was only when they hit a physical limit that they realized the potential of parallelization, which completely changed the way people thought about performance.
Currently, the cost of building a data center for training state-of-the-art language models is approaching a billion dollars, not including the millions of dollars required for training. This is not a sustainable situation. I miss the days when I could run models and prototype things on a laptop.
One of the main problems we face is that we’ve allowed our models to become so large, assuming that compute infrastructure is infinite. These larger models are becoming slower because more time is spent on moving data around rather than on the actual computation. For instance, when I was at Nvidia, anything below 90% of the so-called ‘speed of light’ was considered bad. However, in many cases, large language models only utilize about 30-40% of the peak performance that you can achieve on a GPU. This means a lot of compute power is wasted.
People often overlook this issue. When I suggest optimizing the code on a single GPU and running it on a small model before scaling up, many prefer to simply run it on multiple GPUs to make it faster. This lack of attention to optimization is a significant concern.
Aparna: As we wrap up, I’d like to pose a final question related to your experience at Neuralink, a company focused on brain-to-robot interaction. This technology has potential applications in assisting differently-abled individuals. Could you share your perspective on this technology? When do you anticipate it will be ready, and what applications do you foresee?
Kamil: My experience at Neuralink was truly an exciting adventure. I had the opportunity to work with a diverse team of neuroscientists, physicists, and biologists, all of whom were well-versed in computing and programming. Despite the initial intimidation, I found my place in this team and contributed to some groundbreaking work.
One of the primary challenges we aimed to address at Neuralink was the communication barrier faced by individuals whose cognitive abilities were intact, but who were physically unable to express themselves. This issue is exemplified by renowned physicist Stephen Hawking, who could only communicate by typing messages very slowly using his eyes.
Our initial project involved training macaque monkeys to play a Pong game while simultaneously feeding data from their motor cortex. This allowed us to decode brain signals and enable the monkeys to control something on the screen. Although it may not seem directly related to human communication, this technology could potentially be used to control a cursor and type messages, thus bypassing physical limitations.
We managed to measure the information transfer rate from the brain to the machine in bits per second, achieving a rate comparable to that of people typing on their cell phones. This was a significant milestone and one of the first practical applications of our technology. It could potentially benefit individuals who are paralyzed due to spinal injuries, enabling them to communicate despite their physical limitations.
However, our work at Neuralink wasn’t limited to decoding brain signals and reading data. We also explored the possibility of stimulating brain tissue to induce physical movements or visual experiences. This bidirectional communication could potentially allow individuals to interact with computers more efficiently, bypassing the need for physical input devices. It could even pave the way for a future where VR goggles are obsolete, as we could stimulate the visual cortex directly. However, the safety of these techniques is still under investigation, and it’s crucial that we continue to prioritize this aspect as we push the boundaries of what’s possible.
There’s a significant spectrum of disorders that this technology could address, particularly for individuals who struggle with mobility or communication. We were also considering mental health issues such as depression, insomnia, and ADHD. One of the concepts we were exploring is the ability to read data from the brain, identify its state, and stimulate it. This could potentially serve as a substitute for medication or other forms of treatment.
However, it’s important to note that the technology, while progressing, is not entirely clear-cut. The safety aspect is crucial and cannot be ignored. At Neuralink, we’ve done a remarkable job ensuring that everything we develop is safe, especially considering these devices are implanted in someone’s head.
When we consider brain stimulation, we must also consider potential negative scenarios. For instance, if we stimulate a certain region of the brain to alleviate depression, we could inadvertently create a dependency, similar to injecting dopamine. This could potentially lead to a loop where the individual becomes addicted to the stimulation. It’s a complex issue that requires careful consideration and handling.
In addressing these challenges, we’ve engaged in extensive conversations with physicians, neuroscientists, and other experts. While some companies may have taken easier paths, potentially compromising safety, we’ve chosen a more cautious approach. Despite the slower progress, I can assure you that whatever we produce will be safe. This commitment to safety is something I find particularly impressive.
Kamil: For those interested, it’s worth noting that Neuralink is currently hiring. They’ve recently secured another round of funding and are actively seeking new talent. This is indeed a glimpse into the future of technology.
Aparna: Earlier, you mentioned an intriguing story about monkeys and reading their brainwaves. This story is related to the AI that’s been implanted in their brains and how it communicates. Could you elaborate on what happens with the models in this context?
Kamil: In our initial approach to decoding brain signals, we utilized a simple model. We had a vector of 1024 electrodes and our goal was to infer whether the monkey was attempting to move the cursor up, down, or click on something. We used static data from what we termed a pre-training session, which was essentially data recorded from the implant. The model was a two-layer perceptron, quite small, and could be trained in about 10 seconds. However, the brain’s signal distribution changes rapidly, so the model was only effective for about 10 to 15 minutes before we observed a degradation in performance. This necessitated the collection of new data and retraining of the model.
Recently, Neuralink has started exploring reinforcement learning-based approaches, which allow for on-the-fly identification and retraining of the model on the implant. During my time at Neuralink, my focus was primarily on the inference side. We trained the model outside the implant, and my role was to make the inference parts work on the implant. This was a significant achievement for us, as we were previously sending data out and back in. Given our battery limitations, performing tasks on the implant was more cost-effective. The ultimate goal was to move the entire training process to the implant.
Every day, our brains produce varying signals due to changes in our moods and environments. These factors could range from being in a noisy place, feeling tired, or engaging in different activities. This results in a constantly shifting distribution of brain signals, which presents a significant challenge. This phenomenon is not only applicable to the brain but also extends to other applications in the medical field.
Aparna: We’ve discussed a wide range of topics, from hardware design to image and video generation, and even brainwaves and implant technology. Thank you so much for these perspectives Kamil!
Thank you to Kamil for his perspectives on these exciting AI topics. To read more about Pear’s AI focus and previous Perspectives in AI talks, visit this page.