Founders often ask us what kind of AI company they should start and how to start something long lasting?
Our thesis on AI and ML at Pear is grounded in the belief that advances in these fields are game-changing, paralleling the advent of the web in the late ’90s. We foresee that AI and ML will revolutionize both enterprise software and consumer applications. A particular area of interest is generative AI, which we believe holds the potential to increase productivity across many verticals by five to ten times. Pear has been investing in AI/ML for many years, and in generative AI more recently. That said, there’s still a lot of noise in this space, which is part of the reason we host a “Perspectives in AI” technical fireside series to cut through the hype, and connect the dots between research and product.
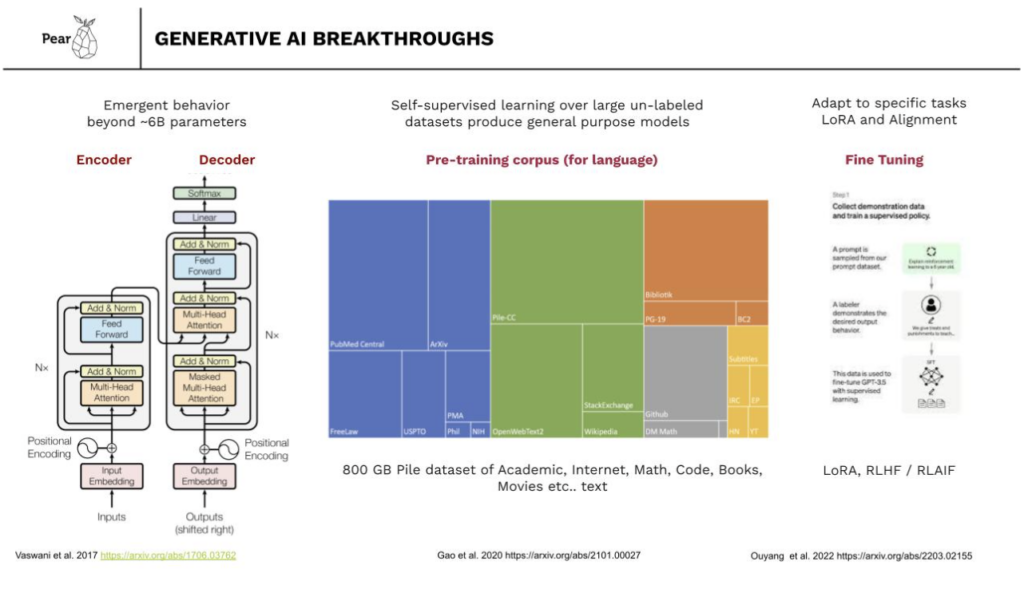
Much of the progress in Generative AI began with the breakthrough invention of the transformer in 2017 by researchers at Google. This innovation combined with the at-scale availability of GPUs in public clouds paved the way for large language models and neural networks to be trained on massive datasets. When these models reach a size of 6 billion parameters or more, they exhibit emergent behavior, performing seemingly intelligent tasks. Coupled with training on mixed domain data such as the pile dataset, these models become general-purpose, capable of various tasks including code generation, summarization, and other text-based functions. These are still statistical models with non zero rates of error or hallucination but they are nevertheless a breakthrough in the emergence of intelligent output.
Another related advancement is the ability to employ these large foundational models and customize them through transfer learning to suit specific tasks. Many different techniques are employed here, but one that is particularly efficient and relevant to commercial applications is fine tuning using Low Rank Adaptation. LoRA enables the creation of multiple smaller fine tuned models that can be optimized for a particular purpose or character, and function in conjunction with the larger model to provide a more effective and efficient output. Finally one of the most important recent innovations that allowed the broad public release of LLMs has been RLHF and RLAIF to create models that are aligned with company-specific values or use-case-specific needs. Collectively these breakthroughs have catalyzed the capabilities we’re observing today, signifying a rapid acceleration in the field.
Text is, of course, the most prevalent domain for AI models, but significant progress has been made in areas like video, image, vision, and even biological systems. This year, in particular, marks substantial advancements in generative AI, including speech and multimodal models. The interplay between open-source models (represented in white in the figure below) and commercial closed models is worth noting. Open-source models are becoming as capable as their closed counterparts, and the cost of training these models is decreasing.
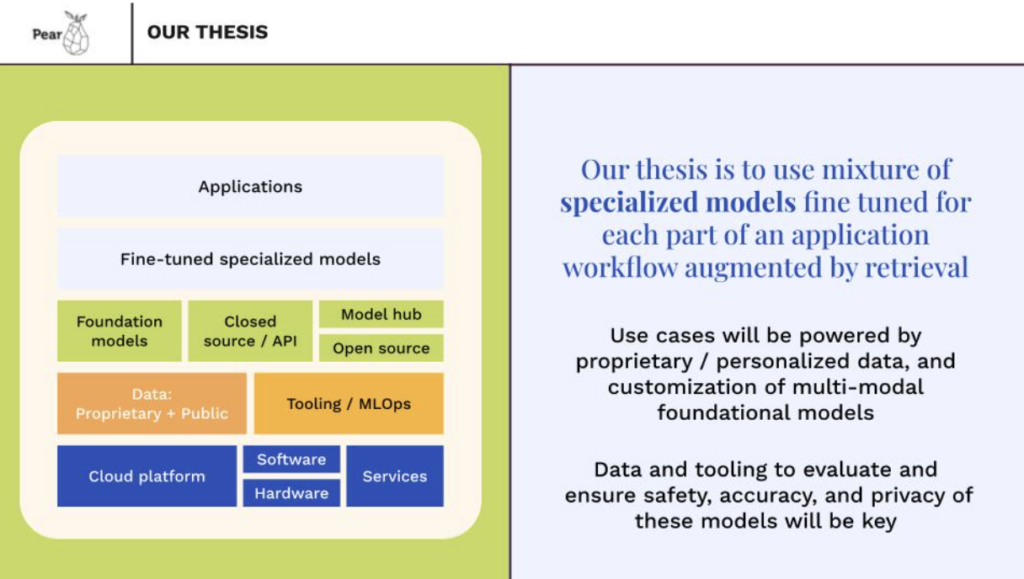
Our thesis on AI breaks down into three parts: 1. applications along with foundation / fine tuned models, 2. data, tooling and orchestration and 3. infrastructure which includes cloud services software and hardware. At the top layer we believe the applications that will win in the generative AI ecosystem will be architected using ensembles of task specific models that are fine tuned using proprietary data (specific to each vertical, use case, and user experience),along with retrieval augmentation. OrbyAI is an early innovation leader in this area of AI driven workflow automation. It is extremely relevant and useful for enterprises.We also believe that tooling for integrating, orchestrating, evaluating/testing, securing and continuously deploying model based applications is a separate investment category. Nightfall understands this problem well and is focused on tooling for data privacy and security of composite AI applications. Finally, we see great opportunity in infrastructure advances at the software, hardware and cloud services layer for efficient training and inference at larger scales across different device form factors. There are many diverse areas within infrastructure from specialized AI chips to high bandwidth networking to novel model architectures. Quadric is a Pear portfolio company working in this space.
Successful entrepreneurs will focus on using a mixture of specialized models fine tuned using proprietary or personal data, to a specific workflow along with retrieval augmentation and prompt engineering techniques to build reliable, intelligent applications that automate previously cumbersome processes. For most enterprise use cases the models will be augmented by a retrieval system to ensure a fact basis as well as explainability of results. We discuss open source models in this context because these are more widely accessible for sophisticated fine tuning, and they can be used in private environments for access to proprietary data. Also they are often available in many sizes enabling applications with more local and edge based form factors. Open source models are becoming progressively more capable with new releases such as Llama2 and the cost of running these models is also going down.
When we talk about moats, we think it’s extremely important that founders have compelling insight regarding the specific problem they are solving and experience with go-to market for their use case. This is important for any start up, but in AI access to proprietary data and skilled human expertise are even more important for building a moat. Per our thesis, fine tuning models for specific use cases using proprietary data and knowledge is key for building a moat. Startups that solve major open problems in AI such as providing scalable mechanisms for data integration, data privacy, improved accuracy, safety, and compliance for composite AI applications can also have an inherent moat.
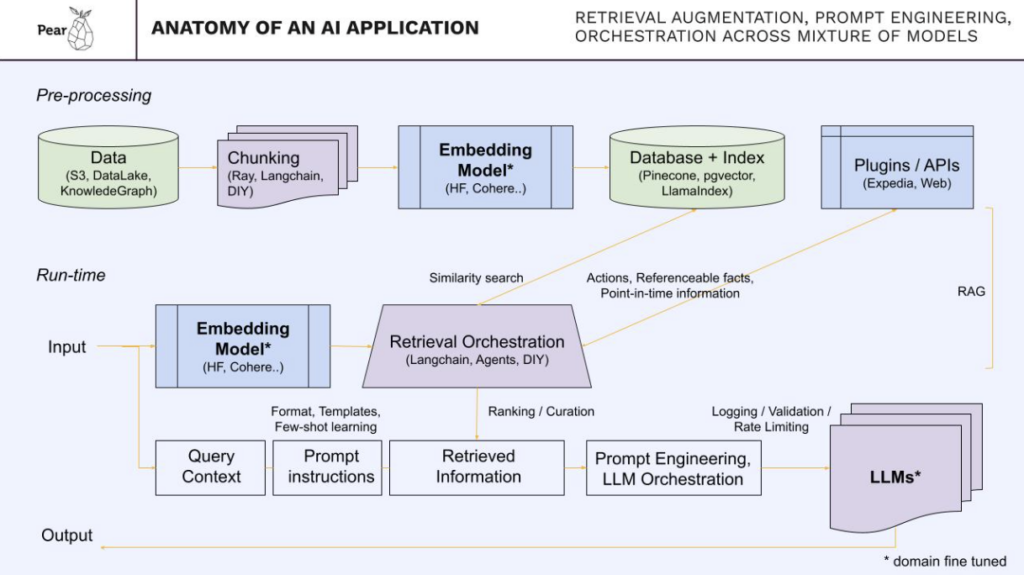
A high level architecture or “Anatomy of a modern AI application” often involves preprocessing data, chunking it and then using an embedding model, putting those embeddings into a database, creating an index or multiple indices and then at runtime, creating embeddings out of the input and then essentially searching against the index with appropriate curation and ranking of results. AI applications pull in other sources of information and data as needed using traditional APIs and databases, for example for real time or point in time information, referenceable facts or to take actions. This is referred to as RAG or retrieval augmented generation. Most applications require prompt engineering for many purposes including formatting the model input/output, adding specific instructions, templates, and providing examples to the LLM. The retrieved information combined with prompt engineering is fed to an LLM or a set of LLMs/ mixture of large language models, and the synthesized output is communicated back to the user. Input and output validation, rate limiting and other privacy and security mechanisms are inserted at the input and output of LLMs. I’ve bolded the Embedding model, and the LLMs, because those benefit from fine tuning.
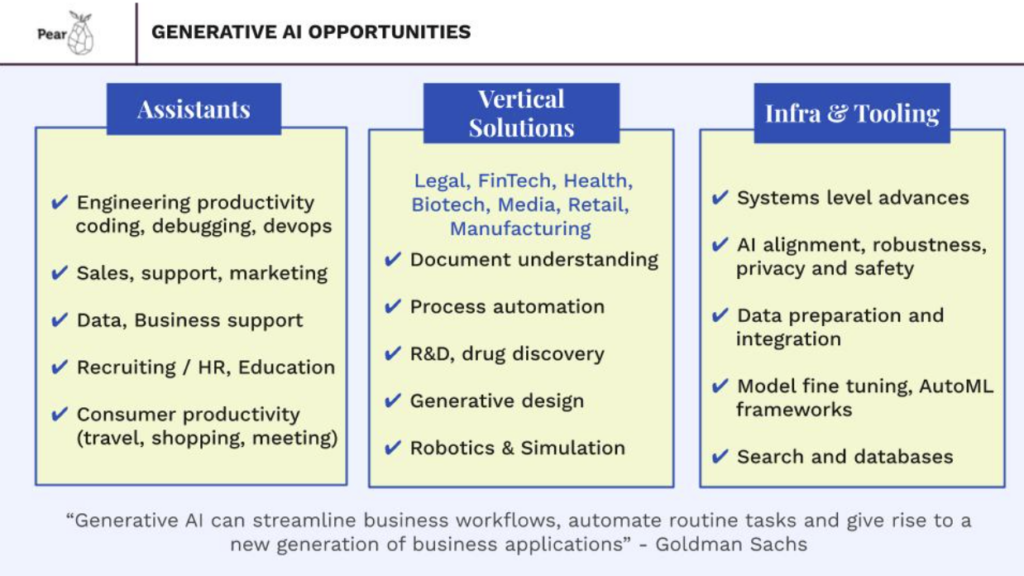
In terms of applications that are ripe for disruption from generative AI, there are many. First of all, the idea of personalized “AI Assistants” for consumers broadly will likely represent the most powerful shift in the way we use computing in the future. Shorter term we expect specific “assistants” for major functional areas. In particular software development and the engineering function overall will likely be the first adopter of AI assistants for everything from code development to application troubleshooting. It may be best to think of this area in terms of the jobs to be done (e.g., SWE, Test/QA, SRE etc), while some of these are using generativeAI today, there is much more potential still. A second closely related opportunity area is data and analytics which is dramatically simplified by generative AI. Additional rich areas for building generative AI applications are all parts of CRM systems for marketing, sales, and support, as well as recruiting, learning/education and HR functions. Sellscale is one of our latest portfolio companies accelerating sales and marketing through generative AI. In all of these areas we think it is important for startups to build deep moats using proprietary data and fine tuning domain specific models.
We also clearly see applications in healthcare, legal, manufacturing, finance, insurance, biotech and pharma verticals all of which have significant workflows that are rich in text, images or numbers that can benefit greatly from artificial intelligence. Federato is a Pear portfolio company that is applying AI to risk optimization for the insurance industry while VizAI uses AI to connect care teams earlier, increase speed of diagnosis and improve clinical care pathways starting with Stroke detection. These verticals are also regulated and have a higher bar for accuracy, privacy and explainability all of which provide great opportunities for differentiation and moats. Separately, media, retail and gaming verticals offer emerging opportunities for generative AI that have more of a consumer / creator goto market. The scale and monetization profile of this type of vertical may be different from highly regulated verticals. We also see applications in Climate, Energy and Robotics longer term.
Last but not least, at Pear we believe some of the biggest winners from generative AI will be at the infrastructure and tooling layers of the stack. Startups solving problems in systems to make inference and training more efficient, pushing the envelope with context lengths, enabling data integration, model alignment, privacy, and safety and building platforms for model evaluation, iteration and deployment should see a rapidly growing market.
We are very excited to partner with the entrepreneurs who are building the future of these workflows. AI, with its recent advances, offers a new capability that is going to force a rethinking of how we work and what parts can be done more intelligently. We can’t wait to see what pain points you will address!
I recently hosted a fireside chat with AI researcher Edward Hu. Our conversation covered various aspects of AI technology, with a focus on two key inventions Edward Hu pioneered: Low Rank Adaptation (LoRA) and μTransfer, which have had wide ranging impact on the efficiency and adoption of Large Language Models. For those who couldn’t attend in person, here is a recap (edited and summarized for length).
Aparna: Welcome, everyone to the next edition of the ‘Perspectives on AI’ fireside chat series at Pear VC. I’m Aparna Sinha, a partner at Pear VC focusing on AI, developer tooling and cloud infrastructure investments. I’m very pleased to welcome Edward Hu today.
Edward is an AI researcher currently at Mila in Montreal, Canada. He is pursuing his PhD under Yoshua Bengio, who is a Turing award winner. Edward has a number of inventions to his name that have impacted the AI technology that you and I use every day. He is the inventor of Low Rank Adaptation (LoRA) as well as μTransfer, and he is working on the next generation of AI reasoning systems.Edward, you’ve had such an amazing impact on the field. Can you tell us a little bit about yourself and how you got started working in this field?
Edward: Hello, everyone. Super happy to be here. Growing up I was really interested in computers and communication. I decided to study both computer science and linguistics in college. I got an opportunity to do research at Johns Hopkins on empirical NLP, building systems that would understand documents, for example. The approach in 2017, was mostly building pipelines. So you have your name entity recognition module, that feeds into maybe a retrieval system, and then the whole thing in the end, gives you a summarization through a separate summarization module. This was before large language models.
I remember the day GPT-2 came out. We had a lab meeting and everybody was talking about how it was the same approach as GPT, but scaled to a larger data set and a larger model. Even though it was less technically interesting, the model was performing much better. I realized there is a limit to the gain we have from engineering traditional NLP pipelines. In just a few years we saw a transition from these pipelines to a big model, trained on general domain data and fine tuned on specific data. So when I was admitted as an AI resident at Microsoft Research, I pivoted to work on deep learning. I was blessed with many mentors while I was there, including Greg Yang, who recently started xAI. We worked on the science and practice of training huge models and that led to LoRA and μTransfer.
More recently, I’m back to discovering the next principles for intelligence. I believe we can gain much capability by organizing computation in our models. Is our model really thinking the way we think? This motivated my current research at Mila on robust reasoning.
Aparna: That’s amazing. So what is low rank adaptation in simple terms and what is it being used for?
Edward: Low Rank Adaptation (often referred to as LoRA) is a method used to adapt large, pre-trained models to specific tasks or domains without significant retraining. The concept is to have a smaller module that contains enough domain-specific information, which can be appended to the larger model. This allows for quick adaptability without altering the large model’s architecture or the need for extensive retraining. It performs as if you have fine tuned a large model on a downstream task.
For instance, in the context of diffusion models, LoRA enables the quick adaptation of a model to particular characters or styles of art. This smaller module can be quickly swapped out, changing the style of art without major adjustments to the diffusion model itself.
Similarly, in language processing, a LoRA module can contain domain-specific information in the range of tens to hundreds of megabytes, but when added to a large language model of tens of gigabytes or even terabytes, it enables the model to work with specialized knowledge. LoRA’s implementation allows for the injection of domain-specific knowledge into a larger model, granting it the ability to understand and process information within a specific field without significant alteration to the core model.
Aparna: Low rank adaptation seems like a compelling solution to the challenges of scalability and domain specificity in artificial intelligence. What is the underlying principle that enables its efficacy, and what led you to develop LoRA?
Edward: We came up with LoRA two years ago, and it has gained attention more recently due to its growing applications. Essentially, LoRA uses the concept of low rank approximation in linear algebra to create a smaller, adaptable module.This module can be integrated into larger models to customize them towards a particular task.
I would like to delve into the genesis of LoRA. During my time at Microsoft,when GPT-3 was released and the OpenAI-Microsoft partnership began, we had the opportunity to work with the 175-billion-parameter model, an unprecedented scale at that time. Running this model on production infrastructure was indeed painful.
Firstly, without fine-tuning, the model wasn’t up to our standards. Fine-tuning, is essential to adapt our models to specific tasks, and it became apparent that few-shot learning didn’t provide the desired performance for a product. Although once fine-tuned, the performance was amazing, the process itself was extremely expensive.
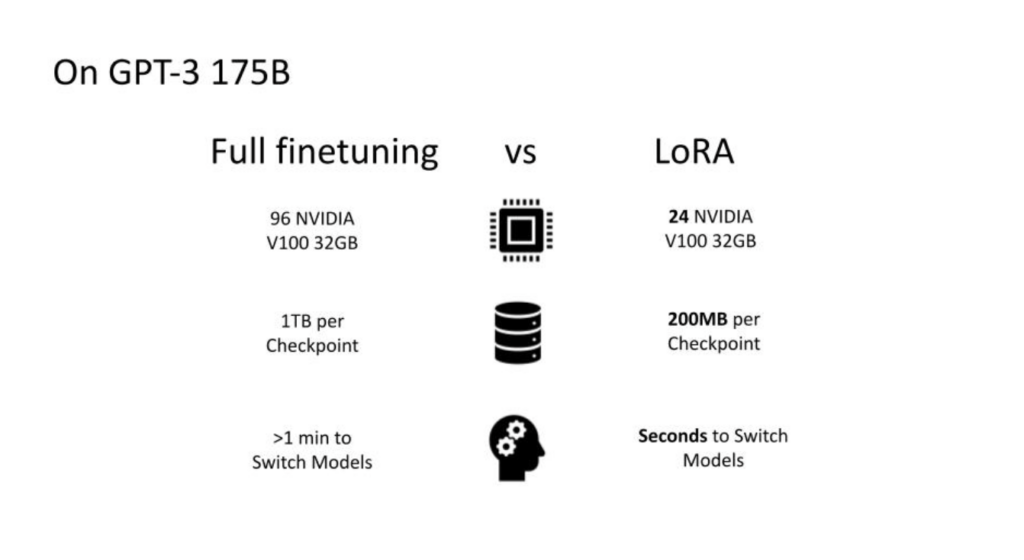
To elucidate, it required at least 96 Nvidia V100s, which was cutting-edge technology at the time and very hard to come by, to start the training process with a small batch size, which was far from optimal. Furthermore, every checkpoint saved was a terabyte in size, which meant that the storage cost was non-negligible, even compared to the GPUs’ cost. The challenges did not end there. Deploying the model into a product presented additional hurdles. If you wanted to customize per user, you had to switch models, a process that took about a minute with such large checkpoints. The process was super network-intensive, super I/O-intensive, and simply too slow to be practical.
Under this pressure, we sought ways to make the model suitable for our production environment. We experimented with many existing approaches from academia, such as adapters and prefix tuning. However, they all had shortcomings. With adapters, the added extra layers led to significant latency, a nontrivial concern given the scale of 175 billion parameters. For prefix tuning and other methods, the issue was performance, as they were not on par with full fine-tuning. This led us to think creatively about other solutions, and ultimately to the development of LoRA.
Aparna: That sounds like a big scaling problem, one that must have prevented LLMs from becoming real products for millions of users.
Edward: Yes, I’ll proceed to elaborate on how we solved these challenges, and I will discuss some of the core functionalities and innovations behind LoRA.
Our exploration with LoRA led to impressive efficiencies. We successfully devised a setup that could handle a 175 billion parameter model. By fine-tuning and adapting it, we managed to cut the resource usage down to just 24 V100s. This was a significant milestone for our team, given the size of the model. This newfound efficiency enabled us to work with multiple models concurrently, test numerous hyperparameter combinations, and conduct extensive model trimming.
What further enhanced our production capabilities was the reduction in checkpoint sizes, from 1 TB to just 200 megabytes. This size reduction opened the door to innovative engineering approaches such as caching in VRAM or RAM and swapping them on demand, something that would have been impossible with 1 TB checkpoints. The ability to switch models swiftly improved user experience considerably.
LoRA’s primary benefits in a production environment lie in the zero inference latency, acceleration of training, and lowering the barrier to entry by decreasing the number of GPUs required. The base model remains the same, but the adaptive part is faster and smaller, making it quicker to switch. Another crucial advantage is the reduction in storage costs, which we estimated to be a reduction by a factor of 1000 to 5000, a significant saving for our team.
Aparna: That’s a substantial achievement, Edward, paving the way for many new use cases.
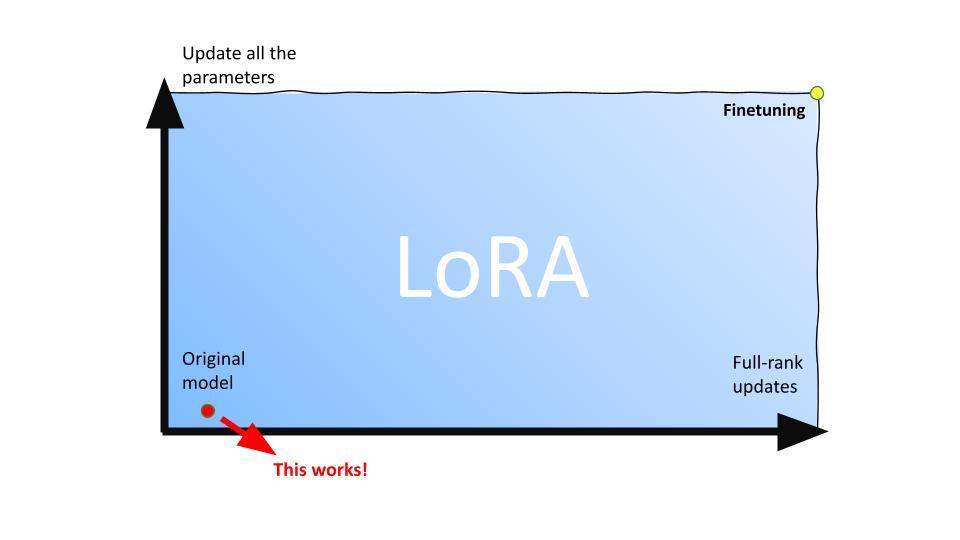
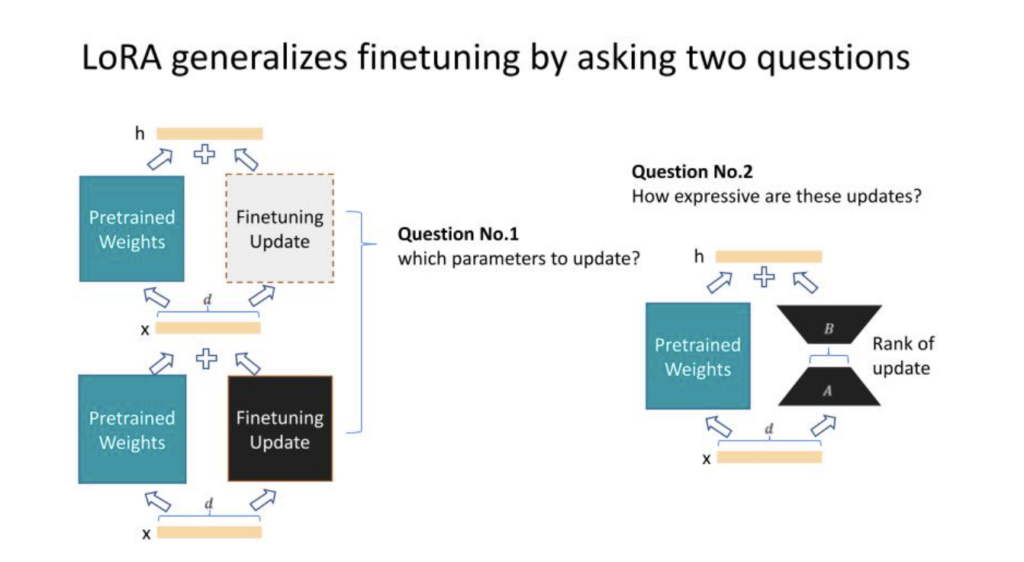
Edward: Indeed. Now, let’s delve into how LoRA works, particularly for those new to the concept. LoRA starts with fine-tuning and generalizes in two directions. The first direction concerns which parameters of the neural network – made up of numerous layers of weights and biases – we should adapt. This could involve updating every other layer, every third layer, or specific types of layers such as the attention layers or the MLP layers for a transformer.
The second direction involves the expressiveness of these adaptations or updates. Using linear algebra, we know that matrices, which most of the weights are, have something called rank. The lower the rank, the less expressive it is, providing a sort of tuning knob for these updates’ expressiveness. Of course, there’s a trade-off here – the more expressive the update, the more expensive it is, and vice versa.
Considering these two directions, we essentially have a 2D plane to help navigate our model adaptations. The y-axis represents the parameters we’re updating – from all parameters to none, which would retain the original model. The parameters of our model exist on a plane where the x-axis signifies whether we perform full rank updates or low rank updates. A zero rank update would equate to no updating at all. The original model can be seen as the origin, and fine tuning as the upper right corner, indicating that we update all parameters, and these updates are full rank.
The introduction of LoRA allows for a model to move freely across this plane. Although it doesn’t make sense to move outside this box, any location inside represents a LoRA configuration. A surprising finding from our research showed that a point close to the origin, where only a small subset of parameters are updated using very low rank, can perform almost as well as full fine tuning in large models like GPT-3. This has significantly reduced costs while maintaining performance.
Aparna: This breakthrough is not only significant for the field as a whole, but particularly for OpenAI and Microsoft. It has greatly expanded the effectiveness and efficiency of large language models.
Edward: Absolutely, it is a significant leap for the field. However, it’s also built on a wealth of preceding research. Concepts like Adapters, Prefix Tuning, and the like have been proposed years before LoRA. Each new development stands on the shoulders of prior ones. We’ve built on these works, and in turn, future researchers will build upon LoRA. We will certainly have better methods in the future.
Aparna: From my understanding, LoRA is already widely used. While initially conceived for text-based models, it’s been applied to diffusion models, among other things.
Edward: Indeed, the beauty of this approach is its general applicability. Whether deciding which layers to adapt or how expressive the updates should be, these considerations apply to virtually any model that incorporates multiple layers and matrices, which is characteristic of modern deep learning. By asking these two questions, you can identify the ideal location within this ‘box’ for your model. While a worst case scenario would have you close to the upper right, thereby not saving as much, many models have proven to perform well even when situated close to the lower left corner. LoRA is also supported in HuggingFace nowadays, so it’s relatively easy to use.
Aparna: Do you foresee any potential challenges or limitations in its implementation? Are there any other domains or innovative applications where you envision LoRA making a significant impact in the near future?
Edward: While LoRA presents exciting opportunities, it also comes with certain challenges. Implementing low rank adaptation requires precision in crafting the smaller module, ensuring it aligns with the larger model’s structure and objectives. An imprecise implementation could lead to inefficiencies or suboptimal performance. Furthermore, adapting to rapidly changing domains or highly specialized fields may pose additional complexities.
As for innovative applications, I envision LoRA being utilized in areas beyond visual arts and language. It could be applied in personalized healthcare, where specific patient data can be integrated into broader medical models. Additionally, it might find applications in real-time adaptation for robotics or enhancing virtual reality experiences through customizable modules.
In conclusion, while LoRA promises significant advancements in the field of AI, it also invites careful consideration of its limitations and potentials. Its success will depend on continued research, collaboration, and innovative thinking.
Aparna: For many of our founders, the ability to efficiently fine tune models and customize them according to their company’s unique personality or data is fundamental to constructing a moat. What your work has done is optimize this process through tools like Lora and μTransfer. Would you tell us now about μTransfer, the project you embarked upon post your collaboration with Greg Yang on the theory of infinity with neural networks.
Edward: The inception of μTransfer emerged from a theoretical proposition. The community has observed that the performance of a neural network seemed to improve with its size. This naturally kindled the theoretical question, “What happens when the neural network is infinitely large?” If one extrapolates the notion that larger networks perform better, it stands to reason that an infinitely large network would exhibit exceptional performance. This, however, is not a vacuous question.
When one postulates an infinite size, or more specifically, infinite width for a neural network, it becomes a theoretical object open to analysis. The intuition being, when you are summing over infinitely many things, mathematical tools such as convergence of random variables come into play. They can assist in reasoning about the behavior of the network. It is from this line of thought that μTransfer was conceived. In essence, it not only has practical applications but is also a satisfying instance of theory and empirical applications intersecting, where theory can meaningfully influence our practical approaches.
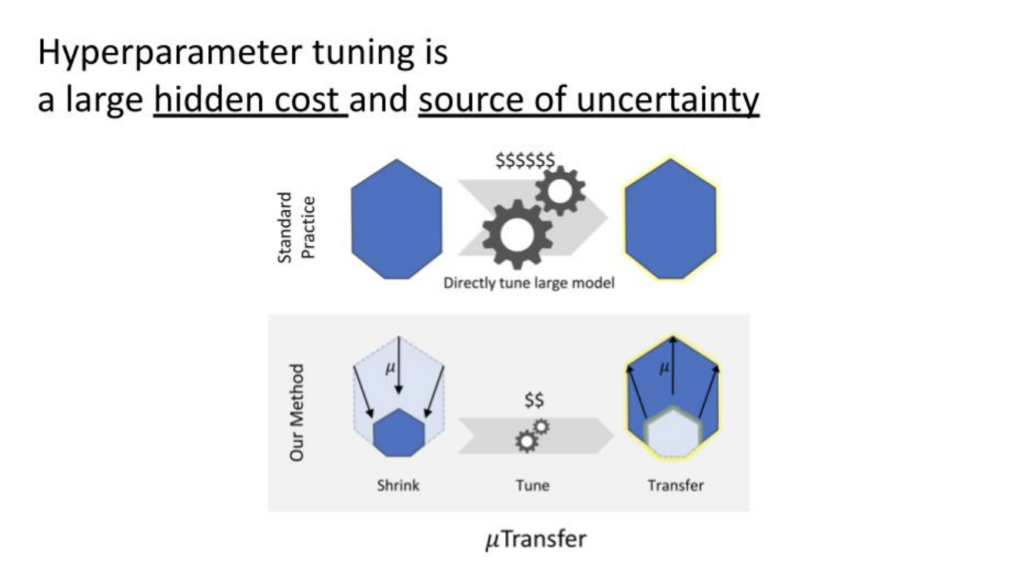
I’d like to touch upon the topic of hyperparameter training. Training large AI models often involves significant investments in terms of money and compute resources. For instance, the resources required to train a model the size of GPT-3 or GPT-4 are substantial. However, a frequently overlooked aspect due to its uncertainty is hyperparameter tuning. Hyperparameters are akin to knobs or magic numbers that need to be optimized for the model to train efficiently and yield acceptable results. They include factors like learning rate, optimizer hyperparameters, and several others. While a portion of the optimal settings for these has been determined by the community through trial and error, they remain highly sensitive. When training on a new dataset or with a novel model architecture, this tuning becomes essential yet again, often involving considerable guesswork. It turns out to be a significant hidden cost and a source of uncertainty.
To further expound on this, when investing tens of millions of dollars to train the next larger model, there’s an inherent risk of the process failing midway due to suboptimal hyperparameters, leading to a need to restart, which can be prohibitively expensive. To mitigate this, in our work with μTransfer, we adopt an alternative approach. Instead of experimenting with different hyperparameter combinations on a 100 billion parameter model, we employ our method to reduce the size of the model, making it more manageable.
In the past, determining the correct hyperparameters and setup was akin to building proprietary knowledge, as companies would invest significant time experimenting with different combinations. When you publish a research paper, you typically disclose your experimental results, but rarely do you share the precise recipe for training those models. The working hyperparameters were a part of the secret. However, with tools like μTransfer, the cost of hyperparameter tuning is vastly reduced, and more people can build a recipe to train a large model.
We’ve discovered a way to describe a neural network that allows for the maximal update of all parameters, thus enabling feature learning in the infinite-width limit. This in turn gives us the ability to transfer hyperparameters, a concept that might need some elucidation. Essentially, we make the optimal hyperparameters the same for the large model and the small model, making the transfer process rather straightforward – it’s as simple as a ‘copy and paste’.
When you parameterize a neural network using the standard method in PyTorch, as a practitioner, you’d observe that the optimal learning rate changes and requires adaptation. However, with our method of maximal update parameterization, we achieve a natural alignment. This negates the need to tune your large model because it will have the same optimal hyperparameters as a small model, a principle we’ve dubbed ‘mu transfer’. Indeed, “μ” in “μTransfer” stands for “maximal update,” which is derived from a parameterization we’ve dubbed “maximal update parameterization”.
To address potential prerequisites for this transfer process, for the most part, if you’re dealing with a large model, like a large transformer, and you are shrinking it down to a smaller size, there aren’t many restrictions. There are a few technical caveats; for instance, we don’t transfer regularization hyperparameters because they are more of an artifact encountered when we don’t have enough data, which is usually not an issue when pretraining a large model on the Internet.
Nonetheless, this transfer needs to occur between two models of the same architecture. For example, if we have GPT3 175 B for which we want to find the hyperparameters, we would shrink it down to GPT3 10 mil or 100 mil to facilitate the transfer of hyperparameters from the small model to the large model. It doesn’t apply to transferring hyperparameters between different types of models, like from a diffusion model to GPT.
Aparna: A trend in recent research indicates that the cost of training foundational models is consistently decreasing. For instance, training and optimizing a model at a smaller scale and then transferring these adjustments to a larger scale significantly reduces time and cost. Consequently, these models become more accessible, enabling entrepreneurs to utilize them and fine-tune them for various applications. Edward, do you see this continuing?
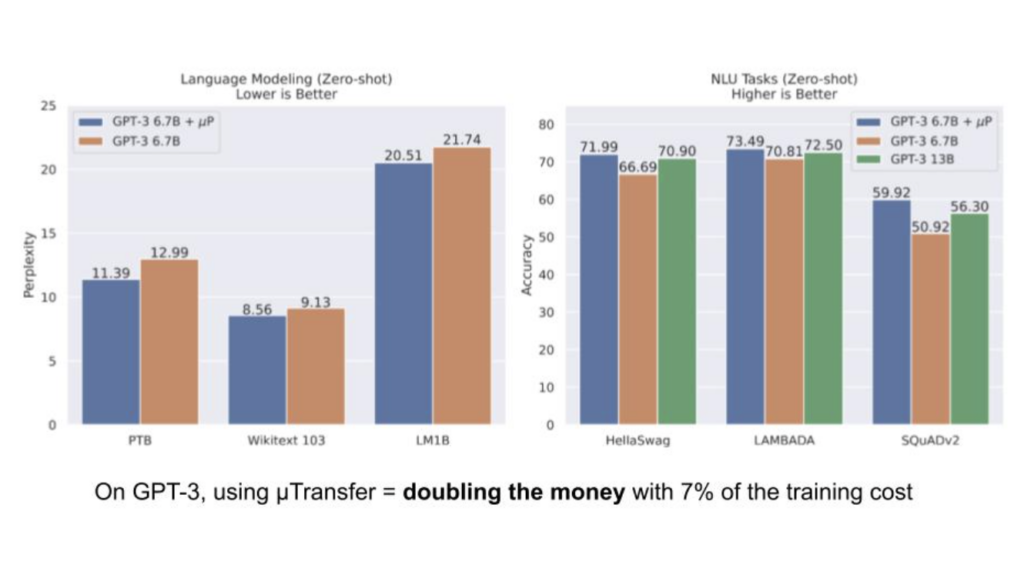
Edward: Techniques like μTransfer, which significantly lower the barrier to entry for training large models, will play a pivotal role in democratizing access to these large models. For example, I find it particularly gratifying to see our work being used in the scaling of large language models, such as the open-source Cerebras-GPT, which comprises around 13 billion parameters or more.
In our experiments, we found that using μTransfer led to superior hyperparameters compared to those discovered through heuristics in the GPT-3 paper. The improved hyperparameters allowed a 6.7 billion parameter model to roughly match the performance of a 13 billion parameter model, effectively doubling the value of the original model with only a 7% increase in the pre-training cost.
Aparna: It appears that the direction of this technology is moving towards a world where numerous AI models exist, no longer monopolized by one or two companies. How do you envision the utilization of these models evolving in the next one or two years?
Edward: It’s crucial to comprehend the diverse ways in which computational resources are utilized in training AI models. To begin with, one could train a large-scale model on general domain data, such as the Pile or a proprietary combination of internet data. Despite being costly, this is typically a one-time investment, except for occasional updates when new data emerges or a significant breakthrough changes the model architecture.
Secondly, we have domain-specific training, where a general-purpose model is fine-tuned to suit a particular field like law or finance. This form of training doesn’t require massive amounts of data and, with parameter-efficient fine-tuning methods like LoRA, the associated costs are dropping significantly.
Finally, there’s the constant use of hardware and compute in inference, which, unlike the first two, is an ongoing cost. This cost may end up dominating if the model or domain isn’t changed frequently.
Aparna: Thank you for the comprehensive explanation. Shifting gears a bit, I want to delve into your academic pursuits. Despite your significant contributions that have been commercialized, you remain an academic at heart, now back at Mila focusing on your research. I’m curious about your perspectives on academia, the aspects of research that excite you, and what you perceive to be the emerging horizons in this space.
Edward: This question resonates deeply with me. Even when I was at Microsoft, amidst exciting projects and the training of large models, I would often contemplate the next significant advancements in the principles and fundamentals underpinning the training of these models. There are myriad problems yet to be solved.
Data consumption and computational requirements present unique challenges to current AI models like GPT-4. As these models are trained on increasingly larger data sets, we might reach a point where we exhaust high-quality internet content. Moreover, despite their vast data processing, these models fail at executing relatively simple tasks, such as summing a long string of numbers, which illustrates the gap between our current AI and achieving Artificial General Intelligence (AGI). AGI should be able to accomplish simple arithmetic effortlessly. This gap is part of what motivates my research into better ways to structure computation and enhance reasoning capabilities within AI.
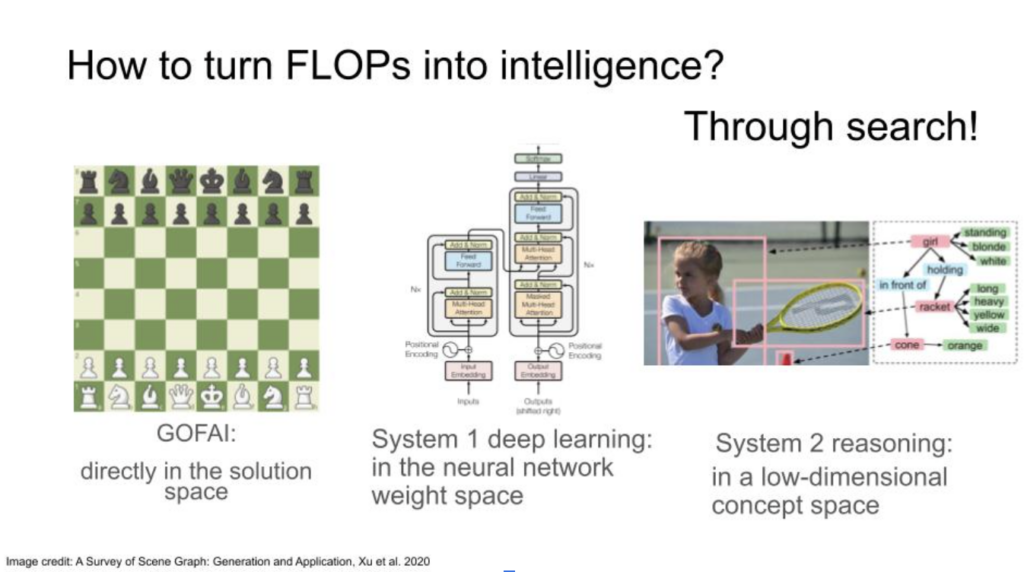
Shifting back to the topic of reasoning, it’s an exciting direction since it complements the scaling process and is even enabled by it. The fundamental question driving our research is, “How can we convert computations, or flops, into intelligence?” In the past, AI was not particularly efficient at transforming compute into intelligence, primarily due to limited computational resources and ineffective methods. Although we’re doing a better job now, there’s still room for improvement.
The key to turning flops into intelligence lies in the ability to perform effective search processes. Intelligence, at its core, represents the capability to search for reasons, explanations, and sequences of actions. For instance, when devising a move in chess, one examines multiple possible outcomes and consequences—a form of search. This concept is not exclusive to games like chess but applies to any context requiring logical reasoning.
Traditional AI—often referred to in research communities as “good old fashioned AI” or “GOFAI”—performed these search processes directly in the solution space. It’s analogous to playing chess by examining each possible move directly. However, the efficiency of these processes was often lacking, which leads us to the development of modern methods.
The fundamental challenge we face in computational problem-solving, such as in a game of chess, is that directly searching the solution space for our next move can be prohibitively expensive, even when we try to exhaustively simulate all possibilities. This issue escalates when we extend it to complex domains like language processing, planning, or autonomous driving.
Today, deep learning has provided us with an effective alternative. Although deep learning is still a form of search, we are now exploring in the space of neural network weights, rather than directly in the solution space. Training a neural network essentially involves moving within a vast space of billions of parameters and attempting to locate an optimal combination. While this might seem like trading one immense search space for another, the introduction of optimization techniques such as gradient descent has made this search more purposeful and guided.
However, when humans think, we are not merely searching in the weight space. We are also probing what we might call the ‘concept space.’ This space consists of explanations and abstract representations; we formulate narratives around the entities involved and their relationships. Therefore, the next frontier of AI research, which we are currently exploring at Mila with Yoshua, involves constructing models capable of searching this ‘concept space.’
Building on the foundations of large-scale, deep learning neural networks, we aim to create models that can autonomously discover concepts and their relationships. This approach harkens back to the era of ‘good old fashioned AI’ where researchers would manually construct knowledge graphs and scene graphs. However, the major difference lies in the model’s ability to learn these representations organically, without explicit instruction.
We believe that this new dimension of search will lead to better ‘sample complexity,’ meaning that the models would require less training data. Moreover, because these models have a more structured, lower-dimensional concept space, they are expected to generalize much better to unseen data. Essentially, after seeing a few examples, these models would ideally know how to answer the same type of question on unseen examples.
Aparna: Thank you, Edward. Your insights have been both practical, pertaining to present technologies that our founders can utilize, as well as forward-looking, providing a glimpse into the ongoing research that is shaping the future of artificial intelligence. Thank you so much for taking us through your inventions and making this information so accessible to our audience.
Join me for the next Perspectives in AI fireside, hosted monthly at Pear for up to date technical deep dives on emerging areas in Artificial Intelligence. You can find an archive of previous talks here.
We recently hosted a fireside chat on safe and efficient AI with notable Stanford CS PhD researchers Dan Fu and Eric Mitchell. The conversation covered various aspects of AI technology, including the innovations that Dan and Eric have pioneered in their respective fields.
Dan is co-inventor of FlashAttention. He’s working on improving efficiency and increasing the context length in Large Language Models (LLMs). His experience in developing groundbreaking AI technologies allows him to provide profound insights into the future capabilities of LLMs. During the event, Dan discussed the implications of his work on enabling new generative AI use cases, as well as brand new techniques for efficient training.
Eric’s work focuses on AI safety and responsibility. He is the co-author of DetectGPT, a tool capable of differentiating between AI-generated and human-generated text. In recent times, DetectGPT has gained press attention for its innovative approach to addressing the growing concern with AI-generated content. Eric shared his thoughts on the potential impact of DetectGPT and similar tools, discussing the necessity for safe AI technologies as the field expands.
During the discussion, we touched on practical applications of generative AI, and the forecast for open source vs. proprietary LLMs. We also touched on the prospect of AGI, the ethical ramifications, cybersecurity implications, and overall societal effects of these emerging technologies.
For those who couldn’t attend in person, we are excited to recap the high points today (answers are edited and summarized for length):
Aparna: Can you tell us a bit about yourselves and your motivation for working in AI?
Dan: I focus on making foundation models faster to train and run, and I’m interested in increasing sequence length to allow for more context in the input data. Making sure you’re not limited by a specific number of tokens. But you can feed in as much data as you’d like, as much context and use that to teach the model what you want to say. I’ve been interested in machine learning for a long time and have been at Stanford for five years now. It’s a thrilling time to work in this field.
Eric: I’m a fourth-year PhD student at Stanford, and I got into AI because of my fascination with the subjective human experience. I’ve taken a winding road in AI, starting with neuroscience, 3D reconstruction, robotics, and computer vision before being drawn to the development of large language models. These large language models are really powerful engines, and we’re sort of just starting to build our first cars that can drive pretty well. But we haven’t built the seatbelts and the antilock brakes, and these safety and quality of life technologies. So that’s what I’m interested in.
Aparna: What major breakthroughs have led to the recent emergence of powerful generative AI capabilities? And where do you think the barriers are to the current approach?
Dan: That’s a really great question. There has been a seismic shift in the way that machine learning (ML) is done in the past three to four years. The old way was to break a problem into small parts, train models to solve one problem at a time, and then use those building pieces to build up a system. With foundation models, we took the opposite approach. We trained a model to predict the next word in a given text, and these models can now do all sorts of things, like write code, answer questions, and even write some of my emails. It’s remarkable how the simplest thing can scale up to create the largest models possible. Advances in GPUs and training systems have also allowed us to scale up and achieve some incredible things.
I think one of the barriers is the technical challenge of providing sufficient context to the models, especially when dealing with personal information like emails. Another barrier is making these models more open and accessible, so that anyone can see what goes into them and how they were trained. So making the process more open the same way that anybody can look at a Kubernetes stack and see exactly what’s happening under the hood. Or anybody can open up the Linux kernel and figure out what is running under there. those are frontiers that I hope that we push on pretty quickly. This would enable better trust and understanding of the models.
Eric: I agree with Dan’s points. Additionally, a challenge we’re facing is the need to solve specific problems with more general models. However, we’ve found that large scale self-supervised training can be effective in tackling these specific problems. For example, the transformer architecture has been helpful in representing knowledge efficiently and improving upon it. In general, the ability to do large scale self-supervised learning on just a ton of data has been key to the recent progress.
Furthermore, we need a way to explain our intent to the model in a way that it can correctly interpret and follow it. This is where the human preference component comes in. We need to be able to specify our preferences to the model, so that it can draw upon its knowledge and skills in a way that is useful for us. This is a qualitative shift in how these models interact with society, and we are only scratching the surface.
Aparna: I’d like to go a little bit deeper technically. Dan, could you explain how your work with attention has made it possible to train these large generative AI models?
Dan: Sure, I can give a brief overview of how attention works at a high level. So you have these language models, and when you give it a sentence, the attention mechanism compares every word in that sentence to every other word in that sentence. If you have a databases background, it’s kind of like a self join, where you have a table that is your sentence, and then you join it to itself. This leads to some of the amazing abilities that we’ve seen in generative AI. However, the way that attention used to be calculated was quite inefficient. You would compare every word to every other word, resulting in a hard limit on the context of the models. This meant that the maximum context length was around 2000, which is what could fit in memory on an A100 GPU.
If you look at databases and how they do joins, they don’t write down all the comparisons between all the joins, they do it block by block.About a year ago, we developed an approach called Flash attention which reduced the memory footprint by doing the comparisons block by block. This enabled longer context lengths, allowing us to feed in a whole essay instead of just a page of text at a time. We’ve been really humbled by the very rapid adoption. It’s in PyTorch, 2.0. GPT-4, for example, has a context length of 8k, and a context length option of 32k.
Aparna: That’s really interesting. So, with longer context lengths, what kinds of use cases could it enable?
Dan: The dream is to have a model that can take all the text ever written and use it as context. However, there’s still a fundamental limitation to attention because even with a reduced memory footprint, you’re still comparing every word to every other word. If you think about how language works, that’s not really how we process language. I’m sure you can’t remember every word I’ve said in the past few minutes. I can’t even remember the words I was saying. That really led us to think okay, are there some alternatives to attention that don’t scale fundamentally quadratically. We’ve been working on some models called Hungry Hungry Hippos. We have a new one called hyena, where we try to make the context length a lot longer. And these models may have the potential to go up to hundreds of thousands of words, or even millions. And if you can do that, it changes the paradigm of what you can do with these models.
Longer context lengths enable more complex tasks such as summarization, question answering, and machine translation. It also allows for more efficient training on large datasets by utilizing more parallelism across GPUs. But if you have a context length of a million words, take your whole training set, feed it in as input, you could have an embodied AI, and have say a particular agent behave in a personalized way when responding to emails or talking to clients.
Longer context can also be particularly useful in modalities like images, where it means higher resolution. For example, in medical imaging, where we are looking for very small features, downsampling the image may cause loss of fine detail. In the case of self-driving cars, longer context means the ability to detect objects that are further away and at a higher resolution. Overall, longer context can help us unlock new capabilities and improve the accuracy of our models.
Aparna: How do you see the role of language models evolving in the future?
Dan: I think we’re just scratching the surface of what language models can do, and there are so many different ways that they can be applied. One of the things that’s really exciting to me is the potential for language models to help us better understand human language and communication. There’s so much nuance and complexity to how we use language, and I think language models can help us unpack some of that and get a better understanding of how we communicate with each other. And of course, there are also lots of practical applications for language models, like chatbots, customer service, and more.
Personally, I’m very excited to see where small models can go. We’re starting to see models that have been trained much longer than we used to train them, like a 7 billion parameter model, or a 13 billion parameter model, that with some engineering, people have been able to get to run on your laptop. When you give people access to these models, in a way that is not super expensive to run, you’re starting to see crazy applications come out. I think it’s really just the beginning.
Eric: It has been an interesting kind of phase change just going from GPT3 to GPT4. I don’t know how much people have played with these models side by side or if people have seen Sebastien Bubeck’s somewhat Infamous First Contact talk now where he kind of goes through some interesting examples. One thing that’s weird about where the models are now is that usually, the pace of progress was slower than the time it took to understand what the capabilities of the technology were, but recently, it felt like a bit of an inversion. I would be surprised to see this slowdown in the near future. And I think it changes the dynamic in research.
Most machine learning research is quantitative, focused on building models, evaluating them on datasets, and getting higher scores. However, Sebastien’s talk is interesting because it evaluates models qualitatively with no numbers, which feels less rigorous but has more credibility due to Sebastien’s rigorous research background. The talk includes impressive examples, such as a model drawing a unicorn or writing 500 lines of code for a 3D game. One fascinating example is the model coaching people in an interpersonal conflict, providing direct and actionable advice that is useful in real-life situations. A big caveat is that current outputs from GPT-4 are much worse than the examples given in the talk. Sebastien’s implication or claim is that aligning the model to follow human intent better reduces its capabilities. This creates a tough conflict between economic incentives and what’s useful for society. It’s unclear what people will do when faced with this conflict.
Aparna: Do you think there will be ethical concerns that arise as language models become more sophisticated?
Eric: Yeah, I think there are also going to be questions around ownership and control of these models. Right now, a lot of the biggest language models are owned by big tech companies, and there’s a risk that they could become monopolies or be used in ways that are harmful to consumers. So we need to be thinking carefully about how we regulate and govern these models, and make sure that they’re being used in a responsible and ethical way.
One of the big challenges is going to be figuring out how to make language models more robust and reliable. Right now, these models are very good at generating plausible-sounding text, but they can still make mistakes and generate misleading or incorrect information. So I think there’s a lot of work to be done in terms of improving the accuracy and reliability of these models, and making sure that they’re not spreading misinformation or bias.
Aparna: Given your PhD research Eric, what are the main areas that warrant concern for AI safety and responsibility?
Eric: In summary, there are three categories of issues related to AI ethics. The first category includes concrete near-term problems that many in the AI ethics community are already working on, such as unreliable and biased models that may dilute collective knowledge. The second category is a middle-term economic alignment problem, where incentives in industry may not be aligned with making models that are safer or more useful for society. The third and longest-term category involves high-stakes decisions made by very capable models, which could be used by bad actors to do harm or may not align with human values and intentions. While some may dismiss the risks associated with these issues, they are worthy of serious consideration.
My research is focused on developing auxiliary technologies to complement existing mass-produced products. I am specifically working on model editing, pre-training models in safer ways, and developing detection systems for AI-generated texts. The aim is to give practitioners and regulators more tools to safely use large language models. However, measuring the capabilities of AI systems is challenging, and my team is working on building a comprehensive public benchmark for detection systems to help better assess their performance.
Aparna: I’m excited about the prospect of having evaluation standards and companies building tooling around them. Do you think there’ll be regulation?
Eric: In my opinion, we can learn from the financial crisis that auditors may not always work in practice, but a system to hold large AI systems to sensible standards would be very useful. Currently, there are questions about what capabilities we can expect from AI systems and what technologies we have to measure their capabilities. As a researcher, I believe that more work needs to be done to give regulators the tools they need to make rules about the use of AI systems. Right now, we have limited abilities to understand why an AI model made a certain prediction or how well it may perform in a given scenario. If regulators want to require certain things from AI model developers, they need to be able to answer these questions. However, currently, no one can answer these questions, so maybe the only way to ensure public safety is to prohibit the release of AI models until we can answer them.
Aparna: Stanford has been a strong contributor to open source and we’ve seen progress with open models like Alpaca, Dolly, and Red Pajama. What are the advantages and disadvantages of open sourcing large language models?
Dan: As an open source advocate and a researcher involved in the Red Pajama release, I believe making these large language models open source can help people better understand their capabilities and risks. The release of the 1 trillion token dataset allowed us to question what goes into these models and what happens if we change their training data. Open sourcing these models and datasets can help with understanding their inner workings and building on them. This is crucial for responsible use of these models.
The effort behind Red Pajama is to recreate powerful language models in an open manner by collecting pre-training data from the internet and human interaction data. The goal is to release a completely open model that is auditable at every step of the process. Small models trained on a lot of text can become surprisingly powerful, as seen in the 7 billion parameter model that can fit on a laptop. The llama model by Facebook is not completely open, as it requires filling out a form and has questionable licenses.
Eric: The open source topic is really interesting. I think many people have heard about the call for a pause on AI research letter. Open source is great, and it’s why OpenAI relies on it a lot. However, a few weeks ago, a bug in an open source framework they were using caused some pretty shocking privacy violations for people who use Chat GPT, where you could see other people’s chat histories. In some sense, I think the cat is already out of the bag on the open source question. The pre-training phase is where a lot of the effort goes into these models, and we already have quite a few really large pre-trained models out there. So even if we paused right now and said no more big pre-trained models can be released, there’s already enough out there for anyone who is worried about it to worry a lot.
Aparna: So with these smaller models, running on laptops and on mobile and edge devices what new use cases will open up?
Dan: Sure, I think it’s amazing that our phones have become so powerful over the past decade. If I could have a language model running on my phone that functions as well as the GPT models we have today, and can assist me in a conversational way, that would be awesome.
Eric: I think it’s exciting and cool from a privacy perspective to have these models running locally. They can be really powerful mental health professionals for people, and I believe these models can be meaningful companions to people as well. Loneliness sucks, and the COVID years have made this very clear to a lot of people. These are the types of interactions that these models are best suited for. They understand what we’re saying, they can respond intelligently, and they can ask us questions that are meaningfully useful.
From this perspective, having them locally to do these types of things can be really powerful. Obviously, there’s a significant dual-use risk with these models, and we’ve tried to do some work to partially mitigate these things. But that’s just research right now. There are already very real and powerful models out there.
I think it’s great and exciting, and I’d be lying if I said I can’t foresee any way this could be problematic in some ways. But the cat is out of the bag, and I believe we will see some really cool and positive technologies from it.
Aparna: My final question is about Auto GPT, a new framework that uses GPT to coordinate and orchestrate a set of agents to achieve a given goal. This autonomous system builds upon the idea of using specialized models for specific tasks, but some even argue that this approach could lead towards AGI. Do you believe this technology is real and revolutionary?
Eric: Yes, Auto GPT is a real framework that uses large language models to critique themselves and improve their performance. This idea is powerful because it suggests that models can improve themselves without the need for constant human feedback. However, Auto GPT is not yet advanced enough to replace human jobs as it can still get stuck in loops and encounter situations where it doesn’t know what to do. It’s also not trustworthy enough to handle tasks that require a high level of complexity and verification. While the ideas behind Auto GPT are promising, it’s not a revolutionary technology in and of itself and doesn’t massively improve the capabilities of GPT.
Dan: So, I was thinking about what you said earlier about the generative AI revolution and how it’s similar to the internet boom in 2000. But I see it more like electricity, it’s everywhere and we take it for granted. It’s enabled us to do things we couldn’t before, but it has also displaced some jobs. For example, we don’t have lamplighters or people who manually wash clothes anymore. However, just like how people in the early 20th century imagined a future where everything would be automated with electricity, we still have jobs for the moment. It’s hard to predict all the impacts AI will have, but it will certainly change the types of jobs people are hired for. I think it’ll become more integrated into our daily lives and introduce new challenges, just like how electrical engineering is a field today. Maybe we’ll see the emergence of foundation model engineering. That’s just my two cents on AGI – I’m not sure if it’ll be fully realized or just a tool to enhance AI capabilities.
Eric: I think the employment question is always brought up in discussions about AI, but it’s not clear that these models can replace anyone’s job right now or in the near future. They are good for augmenting people, but not at tasks they’re not already qualified for. It’s not a drop-in replacement for humans. I don’t think we’ll see mass unemployment, like with the electricity revolution. The internet analogy is similar, in that it was thought to make people more productive, but it turned out to be a distraction tool as well. Generative AI may not have a net positive impact on productivity in the near term, but it will certainly entertain us.
On March 1st, Pear’s Aparna Sinha hosted a fireside chat with Hussein Mehanna, SVP of Engineering for AI/ML at Cruise for a discussion on next generation AI/ML technologies. Hussein has a long and deep history of innovation in machine learning engineering spanning speech recognition, language models, search, ads, and ML platforms at companies including Google, Facebook and Microsoft. He is currently focused on ML-driven robotics, especially autonomous vehicles at Cruise.
This is the first in a series of AI/ML events Pear is hosting. To hear about future events, please sign up for our newsletter and keep an eye on our events page.
The exciting conversation lasted for over an hour, but below is a summary with some highlights from the talk between Aparna and Hussein:
Q: You’ve been building products at the forefront of AI throughout your career, from search, to speech to ML platforms and now robotics and autonomous vehicles. Tell us a little bit about your journey, and the evolution of your work through these products?
A: My journey began with a scholarship for neural networks research in 2003, followed by a role at Microsoft. I eventually joined Facebook and worked on Ads that pushed the limits of ML and from there moved to a more broadened role of working with ML platforms across the company. I then joined Google Cloud’s AI team to explore disruption of enterprise through ML. I learned over the years that robotics is the biggest field facing disruption with machine learning, and autonomous vehicles is the biggest application of that. So I joined Cruise both out of interest in robotics and a pure interest in cars.
Q. Ads, in fact, also at Google was the birthplace of a lot of the advanced AI. And now AI is absolutely into everything.
A: Absolutely. There was a system in Google Ads called Smart ass. It was actually one of the first known large scale machine learning systems. And the person who developed them, Andrew Moore, eventually became my manager at Google Cloud AI. You’d be surprised how many lessons to be learned from building machine learning for ads that you could implement in something as advanced as autonomous vehicles.
You’d be surprised how many lessons to be learned from building machine learning for ads that you could implement in something as advanced as autonomous vehicles.
Q: We are seeing the emergence of many AI-assistive products, co-pilot for x, or auto-pilot for y. But you’ve spoken about AI-native products. Are AI-assistive products and AI-native products fundamentally different?
A: Yes, they are. An AI-native product is one that cannot exist, even in MVP form, without machine learning. Examples include autonomous vehicles or speech recognition software like Alexa. On the other hand, AI-assistive products can help humans in various ways without necessarily using machine learning. In fact, Google search, people may not know that, but Google Search started with more of a data mining approach than machine learning.
Q: What is the gap between building an AI-assistive product versus an AI-native product?
A: The gap is huge. Building an AI-native product assumes full autonomy, while building an AI-enhanced product assumes a human being will still be involved. For example, the technology used for driver-assist features (level 1-3 autonomy) versus fully autonomous driving (level 4-5 autonomy) require vastly different approaches and parameters. Autopilot is actually classified as Driver Assist. But then once you remove the driver completely, from behind the wheel, you get into level 4, level 5, autonomy. Level 5 is maybe less dependent on a predefined map, you could just throw the robot anywhere, and they’ll figure its way. It’s very important for founders, entrepreneurs, product managers to understand, are they building something that assists human beings, and therefore assumes a human being, or something that completely replaces them.
Q: Where do generative AI and GPT technologies fall on the spectrum?
A: Generative AI and GPT – so far – are human-assisted technologies that require a human being to function properly. Today, they are not designed to replace humans like technologies used for level 4-5 autonomy.
Q: At a high level, what are the components and characteristics of a fully autonomous system? I’ve heard you call it an AI brain.
A: So let me project the problem first, from a very high level on driving, because I suspect most of us have driven before. For a full autonomous system the first component is perception, you need to understand the environment, and essentially describe the environment as the here and now. This is a vehicle, it’s heading this direction, with this velocity; here’s a pedestrian, he or she is x distance away from you, and they’re heading that way, and that’s their velocity. Here’s a pile of dirt. And here’s a flying plastic bag. And here’s something that we don’t know what it is, right? So perception is extremely important. Because if you don’t understand the environment around you, you don’t know how to navigate it.
Now, what’s very, very important about perception is that you can’t build a perception system that is 100% perfect, especially a rich system that describes all sorts of things around you. And so one of the lessons we’ve learned is, you can build multiple levels of perception. You can build a level of perception that is less fine grained. A machine learning system that just understands these two categories can generalize better. And it’s very important for your perception system to have some self awareness so that it tells you the rich system is confused about this thing here. So let’s go to the less sophisticated system and understand whether it’s something that is safe to go through or go around. Now the reason why you need the rich system is because it gives you rich information. So you can zip through the environment faster, you can finish your task faster. And if your rich system is accurate, let’s say x percent of the time with a little bit of unsureness, then it’s okay to drive a little bit slower using the less rich, less refined system. So that’s number one about perception.
The second component of autonomous driving is prediction, which involves understanding how agents in the environment will interact with each other. For example, predicting whether a car will cut you off or slow down based on its behavior. However, predicting the future behavior of other agents is dependent on how your car will behave, leading to an interactive loop. We’ve all been in this situation, you’re trying to cross the road, there seems to be a car coming up. If you’re assertive, very likely, in crossing the road, the car will stop. Or if they’re more assertive, you’ll probably back off. At Cruise, we no longer separate the prediction system from the maneuver planning system. We have combined them to decide jointly on what is the future behavior of other agents and our future, to solve extremely complicated interactive scenarios, including intersections with what they call a “chicken dance” where cars inch up against each other. We now call this the “behaviors” component.
The third component is motion planning and controls, where the car starts actually executing on its planned trajectory with smoothness. This component plays a huge role in delivering a comfortable ride because it can accurately calculate the optimal braking speed that reduces jerk (or discomfort). Most of our riders feel the difference immediately compared to human driving where a human driver could pump the breakers harder than necessary. Simulation is also a critical component of autonomous driving, which is often considered only as a testing tool but is, in fact, a reverse autonomous vehicle problem. Simulation involves building other agents that behave intelligently, such as human drivers, pedestrians, and cyclists. At Cruise, we have seen massive improvements in simulation since we have taken a big chunk of our AI and Autonomous Vehicle talent and put them in simulation. The technology we are working on is generalizable and broadly applicable to any robotics problem, such as drones and robots inside warehouses.
I like to tell people that by joining Cruise, people are building their ML-driven robotics career, which can be applied to many other places. The stack of perception, prediction, maneuvering, and simulation can be scaled to other robotics problems. Robotics is pushing AI technology to its limits as it requires reasoning, self-awareness, and better generative AI technologies.
Robotics is pushing AI technology to its limits as it requires reasoning, self-awareness, and better generative AI technologies.
Q: The concepts you described here of predicting and simulating, giving your AI system a reasoning model, and self awareness, in terms of how confident it should be. These are lacking in today’s generative AI technologies. Is this a future direction that could produce better results?
A: I do believe robotics is going to push AI technology to its limits, because it is not acceptable that you build a robot that will do the operation 99% of the time, correct, the 1% of the time can introduce massive friction.
Generative AI is very impressive, because it sort of samples a distribution of outputs, for a task that is not extremely well defined. There’s so many degrees of freedom, it’s like, give me a painting about something. And then it produces a weird looking painting, which in reality is an error. But you’re like, Wow, this is so creative. That’s why I say generative AI and particularly chatGPT do not replace human beings, they actually require a human operator to refine it. Now it may reduce the number of human beings needed to do a task. But it’s L3 at best.
Now, in order to build an L4 and above technology, especially if it has a sort of a massive safety component. Number one, you need various components of this technology to have some self awareness of how sure they are. And us as humans, we actually operate that way with a self awareness of uncertainty. L4 technologies are not going to be able to be certain about everything. So they have to be self aware about the uncertainty of whatever situation they’re in. And then they have to develop sort of policies to handle this uncertainty versus chance it up to tell you whatever, statistically, it’s learned without self awareness of its accuracy.
Q: What do you think about the combination of generative AI and a human operator in various fields such as education and healthcare?
A: Using generative AI alongside a human operator can result in an incredible system. However, it’s important to be mindful of the system’s limitations and determine whether you’re creating an L3 system with more degrees of freedom or an L4 system with no human oversight. In the field of education, generative AI can be a valuable tool, but it’s crucial to acknowledge that education is a highly sensitive area. On the other hand, in healthcare, as long as a physician reviews the outcomes, there are considerable degrees of freedom.
Q: I’ve heard great reviews from riders using Cruise’s service in San Francisco. What was your experience like in a driverless ride?
A: My first driverless ride was in a Chevy Bolt vehicle with a decent sensor package on top. At first, I felt a little anxious, but quickly realized that the vehicle was an extremely cautious driver that obeyed stop signs and braked very well. The vehicle optimized the braking and turning speeds, which made me feel safe and comfortable. I have seen the same reaction from family and friends who have ridden in the vehicles.
I think that the new Origin car is amazing and looks like the future. It’s a purposely built car for autonomy with no steering wheel and has two rows of seating facing each other. I believe that it’s going to be a very different experience from the current driverless rides, as it becomes real that there’s no driving and the car is really moving itself. The feedback from multiple people who have experienced it is that it’s as big as their first driverless ride. I also think that people will love the Origin car because it’s more comfortable and cautious than any vehicle with a driver, and it looks like the future. The first version of the Origin car should be deployed this year, and I hope that many people will have the opportunity to experience it and enjoy it within the next year or two.
Q: What are some open questions and unsolved problems as we move forward in building autonomous vehicles?
A: One open question is how to move towards end-to-end learning for autonomous vehicles, which would involve creating a single, large machine learning model that takes in sensor inputs and produces control signals, rather than the current system, which is heavily componentized. Another question is how to create an equivalent to the convolutional operator, a key component in computer vision, for autonomous vehicles. This is still an early stage field that requires significant investment to develop.
Q: At Facebook, you pioneered a new approach to AI platforms that then also later permeated our work at Google Cloud. And I think it was a very meaningful contribution. Can you explain why platforms are important for machine learning productivity?
A: I pioneered a new approach to AI platforms at Facebook that focused on productivity and delivering machine learning models quickly. I believe that productivity is key for successful machine learning because it allows for quick iteration and a faster feedback loop. In my opinion, platforms are the best mechanism to deliver machine learning models quickly and make machine learning a reality. I believe what is much more powerful than building one model that is centralized, that serves everybody is to empower everybody to build the models they want, and to tweak them, and to tune them the way they like. And that’s where a machine learning platform comes in. And I do believe that is very much true in our organization. And I’ve seen that happen at Facebook, where at one point, around 2017, we had 20% of the company, either interacting or building machine learning models one way or another.
Q: In summary, are we at an inflection point in machine learning? Can autonomous systems approaches influence responsible AI more broadly?
A: I believe that we are at an inflection point where machine learning is expected to have a massive impact on multiple fields, including autonomous vehicles, robotics, and generative AI. Robotics is pioneering this concept of reasoning and understanding the environment and incorporating it, simulating it, and building your machine learning system to be accurate enough and understand the externalities. All of it is on this foundational bedrock of having great platforms which will enable quick iteration and a faster feedback loop.
I also believe that the advanced work happening in robotics and autonomous vehicles will influence the future of AI, potentially leading to a more holistic and safe system that is oriented towards reasoning. In my opinion, one potential impact of autonomous vehicle technology on machine learning is around responsible AI. We should have one strategy for product safety, rather than separate strategies for product safety and ML safety. As an autonomous vehicle engineer, I spend more time evaluating the effectiveness of the system than building and tuning the ML model. The ability to evaluate the system effectively will become increasingly important, and I hope that there will be a generation of ML engineers that are used to doing so.
I believe that we are at an inflection point where machine learning is expected to have a massive impact on multiple fields, including autonomous vehicles, robotics, and generative AI.
We’d like to extend our sincerest thanks to Hussein Mehanna for joining us for this insightful chat. His expertise and experience in the field provided valuable insights into the current and future states of AI/ML. We look forward to hosting more conversations on AI, so please keep an eye on our events page!
I recently joined Pear as a Visiting Partner focused on early-stage investments in Machine Learning / Artificial Intelligence and Developer Tools. As I kicked off this new chapter, I sought advice on how to find the next billion dollar startup. The natural place to start: ChatGPT.
Every time I asked ChatGPT which areas in technology are likely to cause the greatest disruption in the next 5 years?”, it gave me different lists, everything from quantum computing to 5G to Biotech and medicine. But AI/ML was always on top of its list. So to get some detail on the potential of AI/ML, I asked “which problems should AI-based startups solve to maximize growth and ROI?”
Results from ChatGPT question: “which problems should AI-based startups solve to maximize growth and ROI?”
I noticed that ChatGPT picked up acronyms like ROI and expanded them correctly, and correctly interpreted queries with misspelled words (e.g., ‘distributed’ was corrected to ‘disruptive’ based on the context of the chat). That made me sit up in my chair!
ChatGPT’s responses are high level. So I tried to pin it down by asking what specific products our startup should build. It provided a specific list, but I could not get it to stack rank or put numerical values against any of these.
Results from ChatGPT question around what specific products our startup should build.
To go deeper, I picked the ‘Personal Assistants’ product idea, and asked
1. “How would we monetize our personal assistant?” and got this reply:
Results from ChatGPT question: “How would we monetize our personal assistant?”
2. And, “how would we differentiate it relative to competition?”
Results from ChatGPT question: “How would we differentiate it relative to competition?”
These were surprisingly good answers: multimodal chatbots that are personalized and integrated with enterprise systems could be quite useful. Finally I asked ChatGPT to write the business plan and it did! I shared this business plan with Pear’s healthcare investors and it even passed a few checks. Now if only ChatGPT could generate founders and funding, we’d be all set!
But let’s fast forward to the future, which is what Pear’s portfolio companies are building. First of all they are using AI to solve real problems, such as automating an existing workflow. For example, Osmos.io uses a form of generative AI to create data transformations in a no-code data ingestion platform that’s replacing fragile, hard to maintain hand-coded ETLs. Sellscale uses generative AI to create better marketing emails. Orby.ai discovers and automates repetitive tasks in Finance, HR, customer service, sales, and marketing. And CausalLabs.io is creating the infrastructure layer for UI that is increasingly generated, optimized and personalized by AI.
Kirat Pandya, Co-Founder and CEO of Osmos, a Pear portfolio company that helps companies scale their customer data ingestion and drive growth with self-serve uploaders and no-code ETL
These companies are building on foundational models like GPT and expanding them to get users accurate, effective outcomes that are orders of magnitude more efficient. When a technology creates orders of magnitude better outcomes, it is a game changer.
We believe AI in 2023 is what PC’s were in 1983 or the internet was in 1995 – it will power enterprises and consumers to do things they couldn’t before and generate enormous value in the next five years. Much of it will come from startups that are in the very early stages today.
This brings me back to why I joined the fast-moving startup ecosystem at PearVC in the first place: the time is now, and the opportunity to build the future with our next billion dollar startup is here.
Ali Baghshomali, former data analyst manager at Bird, hosted a talk with Pear on data and analytics for early stage founders. We wanted to share the key takeaways with you. You can watch the full talk here.
While a lot has been said around building go to market and engineering teams, there’s not much tactical coverage for analytics teams. Yet analytics is one of the most fundamental and crucial functions in a startup as it launches and scales.
When should you start seriously working on analytics?
You should start thinking about your analytics platform when your company is nearing product launch. After your product is live, you’ll receive an influx of data (or at least some data) from customers and prospects, so you want to be prepared with the proper analytics infrastructure and team to make the most of this data to drive business growth.
If you are just starting out and would benefit from working with analytics but don’t have much in house, consider using third party data sources, like census data.
Why should you work on analytics?
If done well, analytics will pay back many, many times over in time, work, money, and other resources saved as well as powerful insights uncovered that drive meaningful business growth.
Who should you hire?
In conversation, people often use “data scientist” and “data analyst” interchangeably. While fine for casual conversation, you should clearly understand and convey the difference when writing job postings, doing job interviews, hiring team members, and managing data teams.
Data scientists work with predictive models through leveraging machine learning. Data analysts, in contrast, build dashboards to better display your data, analyze existing data to draw insights (not predictions), and build new tables to better organize existing data.
For example, at Spotify, data scientists build models that recommend which songs you should listen to or add to particular playlists. Data analysts analyze data to answer questions like how many people are using the radio feature? At what frequency?
Similarly, at Netflix, data scientists build models that power the recommendation engine, which shows you a curated dashboard of movies and TV shows you may like as soon as you log in. Data analysts would conduct data analysis to determine how long people spend on the homepage before choosing a show.
Unless your core product is machine learning driven, you should first hire data analysts, not data scientists. In general, a good rule of thumb is to have a 3:1 ratio of data analysts to data scientists (for companies whose products are not machine learning driven).
For early stage startups, stick to the core titles of data scientists and data analysts rather than overly specialized ones like business intelligence engineers because you’ll want someone with more flexibility and who is open and able to do a wider range of work.
What should be in your analytics stack?
Here are examples of tools in each part of the analytics stack and how you should evaluate options:
Database: examples include BigQuery and Redshift. Analytics databases are essentially a republica of your product database but solely for analytics. In this way, you can do analytics faster without messing up product performance. In general, it is advisable to use the same database service as your cloud service.
Business intelligence: examples include Looker and Tableau. Business intelligence tools help you visualize your data. They connect to your analytics database. You should pick a provider based on pricing, engineering stack compatibility, and team familiarity. Don’t just default to the most well known option. Really consider your unique needs.
Product intelligence: examples include Mixpanel and Amplitude. Product intelligence tools are focused on the product itself, rather than the over business. Specifically, they are focused on the user journey. They get code snippets inserted from the product. Because they don’t encapsulate the full code, you should consider this data to be an estimate and use the insights drawn more directionally. Product intelligence tools can be used to create charts, funnels, and retention analyses, and they don’t need to be connected to other databases.
What are some case studies of company analytics operations?
Helping Hands Community is a COVID inspired initiative that services high risk and food insecure individuals during the pandemic.
Team: 7 engineers, no data analysts
Product: basic with 1000 users
Stack: Google Cloud, Firebase for product database, BigQuery for analytics, Google Data Studio for business intelligence, and Google Analytics for product intelligence
Bird is a last mile electric scooter rental service.
Stack: AWS for cloud, Postgres (AWS) for product database, PrestoDB for analytics, Tableau and Mode for business intelligence, Mixpanel for product, Google Analytics for website, Alation for data, DataBricks for ETL, and Anodot for anomaly detection (you generally need anomaly detection when ~1 hour downtime makes a meaningful difference in your business)
What should you do moving forward?
Make a data roadmap just like you make business and product roadmaps. Data roadmaps are equally as important and transformative for your startup. List the top 5 questions you foresee having at each important point along this roadmap. Structure your data roadmap in a way that your stack and team addresses each of the questions at the point at which they’re asked.
We hope this article has been helpful in laying the foundations for your analytics function. Ali is available to answer further questions regarding your analytics strategy, and he is providing analytics and data science consulting. You can find and reach him on LinkedIn here.
This is a recap of our discussion with Nikhyl Singhal, VP of Product at Facebook, former CPO at Credit Karma, and former Director of Product Management at Google.
Watch the full talk at pear.vc/events and RSVP for the next!
Product management can be an elusive topic, especially as its definition changes as the company grows. Early on, product management is focused on helping the company get to product market fit. Once the company achieves it, product management can change dramatically depending on the type of product or service, the organizational structure, and the company’s priorities. We brought Nikhyl Singhal to demystify the product management process and share insights on when, how and why to add product management into your company.
In the “Drunken Walk” Phase, Product Managers Should Really Be Project Managers
While employees at early stage companies may have Product Manager as their title, they should really be owning project management and execution.
Product management, or the goal of helping that company get to product market fit, should be owned by the founders.
It’s partially an incentive problem. Founders, as Singhal notes, are usually the executives with a larger share of ownership.
“They’re the ones that the investors have really placed money in and the extended team in some ways just aren’t at the same level in scale as the founders,” Singhal says.
However, execution and distribution are team responsibilities–and Singhal considers them much more of a utility than a strategic function. Understanding the allocation of responsibilities in founders versus product managers in early stage companies can be crucial to success.
“I actually embrace this and I [would] suggest, “Look, there’s no shame in saying that we need to bring in product managers to really own a lot of the execution.”
For Founders Working on Product Market Fit, Maintain Healthy Naivete
For early stage founders, Singhal says not to discount naivete. He recounts from his own experience that while others had insider perspectives or felt jaded, his own beliefs helped propel him through company building, ultimately helping him found three companies in online commerce, SAAS, and voice services.
“I think that the lesson, if I were to pick one, is that healthy naivete is a critical element to finding product fit and actually fortitude around some of those ideas that are, ‘Hey, the world should work this way,’” Singhal reflects. “‘I don’t quite understand the industry, but I want to focus on that user, that business problem, and go forward on it.’”
If You’re Not a Product Person, Find a Co-Founder Who Can Own Product Market Fit
“The speed to be able to go through product fit is so essential for being able to efficiently get to the destination in the final course of action for the company,” Singhal says.
Thus, while it’s possible for founders to take other roles early on, purely outsourcing product fit to the rest of the team is still not a wise decision.
“If you’re not the person who’s owning product fit and you agree that product fit is sort of job number one, what I would say is—find a co-founder who can be essentially the owner of product fit. The reason why I use the term co-founder is for the economics to work.”
Introduce Product Management When Founders Shift Priorities
One issue founders often face with product management is determining when to introduce it. Introducing it too early may lead to conflicts internally, while introducing it too late means the company may have missed out on the prime time for strengthening execution.
Again, product management is dependent on the founders’ backgrounds. For founders who have backgrounds in product, as long as there is clarity and predictability around what will happen, the company may proceed without product managers. The most common case for introducing product management, however, is when founder priorities need to shift from product fit to scaling the organization.
“This could be establishing new functions,” Singhal notes, “Or fundraising or thinking through acquisition. Marketing is also an important area, or thinking through company culture if the company starts to scale. At this point, if you fail to bring in product management, you’ll see dramatic reductions in efficiency.”
Look for Product Managers Who Can Scale with the Organization
For early product manager hires, companies should consider both the growth curve of the company and the growth point of the individual. Especially for companies that may be in hypergrowth, it’s important to have a mindset that “what’s gotten us here isn’t what gets us there.” This means the product management team must be adaptable.
Being aware of how product management interacts with other functions is also crucial.
“Product tends to essentially sit between the power functions of the organization as it deals with scale and growth,” Singhal says. It could be between marketing analytics and product engineering, or sales and product, depending on what the company’s business model is.
Lastly, founders need to examine their own career trajectories in transitioning product power to teammates. It can be a tough emotional decision, Singhal acknowledges, but this question should be asked early on.
“I think that it’s almost a psychological question around: what is the person’s career ambition as a founder? Do they see themselves as moving into a traditional executive role? Shall I call it CEO or head of sales or head of product? If the goal of the person is to expand beyond product, then I think that the question really deserves quite a bit of weight,” Singhal says.
This is a recap of our discussion with Pedram Keyani, former Director of Engineering at Facebook and Uber, and our newest Visiting Partner.Keep an eye out for Pedram’s upcoming tactical guide diving deeper into these concepts.
The first mistake managers encounter in the hiring process is not prioritizing hires. Often, when faced with building a company’s first team, managers tend to hire for generalists. While this is a fine principle, managers must still identify what the most critical thing to be built first is.
“The biggest challenge that I see a lot of teams make is they don’t prioritize their hires, which means they’re not thinking about: what do they need to build? What is the most critical thing that they need to build?”
Mistake #2: Ignoring Hustle, Energy, and Optimism
People naturally prefer pedigreed engineers — engineers that have worked at a FAANG company, for example, or engineers that have built and shipped significant products. But for young companies that might not have established a reputation yet, they’re more likely to attract new college grads.
“They’re not going to know how to do some of the things that an engineer who’s been in the industry for a while will do, but oftentimes what they have is something that gets beaten out of people. They have this energy, they have this optimism. If you get a staff engineer that’s spent their entire career at—name-your-company—they know how to do things a particular way. And they’re more inclined to saying no to any new idea than they are to saying yes.”
So don’t worry too much about getting that senior staff engineer from Google. Often, bright-eyed, optimistic young engineers just out of school work well too.
Mistake #3: Not Understanding Your Hiring Funnel
Managers must be aware of how their hiring funnels are laid out. No matter what size of company or what role, a hiring manager must treat recruiting like their job and be a willing partner to their recruiters.
Get involved as early as sourcing.
“If they’re having a hard time, for example, getting people to respond back to their LinkedIn or their emails, help put in a teaser like, ‘Our director or VP of this would love to talk to you.’ If that person has some name recognition, you’re much more likely to get an initial response back. That can really fundamentally change the outcomes that you get.”
Mistake #4: Not Planning Interviews
Once a candidate gets past the resume screen to interviews, that process should be properly planned. Interviewing is both a time commitment from the candidate and from the company’s engineering team. Each part of the process must be intentional.
For phone screens, a frequent mistake is having inexperienced engineers conduct them.
“You want the people who are doing the phone screens to really be experienced and have good kinds of instincts around what makes a good engineer.”
For interviews, Pedram suggests teams have at least two different sessions on coding and at least one more session on culture.
To train interviewers, a company can either have new interviewers shadow experienced interviewers or experienced interviewers reverse shadow new interviewers to make sure they’re asking the right questions and getting the right answers down.
Mistake #5: Lowering Your Standards
Early companies can encounter hiring crunches. At this time, hiring managers might decide to lower their standards in order to increase headcounts. However, this can be extremely dangerous.
“You make this trade off, when you hire a B-level person for your company—that person forever is the highest bar that you’re going to be able to achieve at scale for hiring because B people know other B people and C people.”
What about the trade-off between shipping a product and hiring a less qualified teammate? Just kill the idea.
“At the end of the day, these are people you’re going to be working with every day.”
Mistake #6: Ignoring Your Instincts
Failure #5 ties into Failure #6: Ignoring your instincts. If there’s a gut feeling that your candidate won’t be a good fit, you should trust it.
“The worst thing you can do is fire someone early on because your team is going to be suffering from it. They’re going to have questions. They’re going to think, ‘Oh, are we doing layoffs? Am I going to be the next person?’”
Mistake #7: Hiring Brilliant Jerks
During the hiring process, managers may also encounter “Brilliant Jerks.” These are the candidates that seem genius, but may be arrogant. They might not listen, they might become defensive when criticized, or they might be overbearing.
The danger of hiring brilliant jerks is that they’ll often shut down others’ ideas, can become huge HR liabilities, and won’t be able to collaborate well within a team environment at all.
So when hiring, one of the most important qualities to look out for is a sense that “this is someone that I could give feedback to, or I have a sense that I could give feedback to you.”
Mistake #8: Giving Titles Too Early
Startups tend to give titles early on. A startup might make their first engineering hire and call them CTO, but there are a lot of pitfalls that come with this.
“Make sure that you’re thoughtful about what your company is going to look like maybe a year or two year, five years from now. If you’re successful, your five person thing is going to be a 500,000 person company.”
Can your CTO, who has managed a five person team effectively, now manage a 500,000 person team?
Instead of crazy titles, provide paths to advancement instead.
“Give people roles that let them stretch themselves, that let them exert responsibility and take on responsibility and let them earn those crazy titles over time.”
Mistake #9: Overselling The Good Stuff
When a team’s already locked in their final candidates, young companies might be incentivized to oversell themselves to candidates—after all, it’s hard to compete against offers from FAANG these days. But transparency is always the best way to go.
“You need to tell a realistic story about what your company is about. What are the challenges you’re facing? What are the good things? What are the bad things? Don’t catfish candidates. You may be the most compelling sales person in the world, and you can get them to sign your offer and join you, but if you’re completely off base about what the work environment is like a weekend, a month, and six months in, at some point, they’ll realize that you are completely bullshitting them.”
As Director of Engineering at Facebook, Pedram made sure to put this into practice. After mentioning the positives and perks of the job, he would follow up with “By the way, it’s very likely that on a Friday night at 9:00 PM, we’re going to have a crazy spam attack. We’re going to have some kind of a vulnerability come up. My team, we work harder than a lot of other teams. We work crazy hours. We work on the weekends, we work during holidays because that’s when shit hits the fan for us. I wouldn’t have it any other way, but it’s hard. So if you’re looking for a regular nine to five thing, this is not your team.”
Make sure to set expectations for the candidate before they commit.
Mistake #10: Focusing on the Financial Upside
Don’t sell a candidate on money as their primary motivation during this process.
“If the key selling point you have to your potential candidate is that you’re going to make them a millionaire you’ve already lost.”
Instead, develop an environment and culture about a mission. Highlight that “if we create value for the world, we’ll get some of that back.”
Mistake #11: Getting Your Ratios Wrong
Companies want to make sure that they have the right ratio of engineering managers to engineers. Each company might define their ratios differently, but it’s important to always keep a ratio in mind and keep teams flexible.
Mistake #12: Not Worrying About Onboarding
Once a candidate signs on, the onboarding process must be smooth and well-planned. Every six months, Pedram would go through his company’s current onboarding process himself, pretending to be a new hire. This allowed him to iterate and make sure onboarding was always up to date.
“It’s also a great opportunity for you to make sure that all of your documentation for getting engineers up to speed is living documentation as well.”
Mistake #13: Not Focusing on Culture
Culture should underscore every part of the hiring process. It can be hard to define, but here are some questions to start:
How does your team work?
How does your team solve problems?
How does your team deal with ambiguity?
How does your team resolve conflicts?
How does your team think about transparency and openness?
“Culture is something that everyone likes to talk about, but it really just boils down to those hard moments.”
Mistake #14: Never Reorganizing
Failure #14 and #15 really go hand in hand. As many companies grow, they may forget to reorganize.
“You need to shuffle people around. Make sure you have the right blend of people on a particular team. You have the right experiences on a team.”
Again, keep your ratios in mind.
Mistake #15: Never Firing Anyone
Lastly, and possibly the hardest part of hiring, companies need to learn to let people go.
“People have their sweet spot. Some people just don’t scale beyond a 20 person company. And, you know, keeping them around is not fair to them and not fair to your company.”
This is a recap of our discussion with Lindsay Kriger, Director of Transformation and Business Operations, Andrew Smith, Chief Operations and Innovation Officer, and Dr. Bobbie Kumar, a family physician, from Vituity, the largest physician-owner partnership in the U.S.
Though tackling the American healthcare system seems extremely daunting, the most important rule as a healthcare founder is to remember to keep the patients’ and the communities’ needs centered. Like any startup founder, healthcare providers need to know their users.
“The reality of healthcare innovation is that it’s local,” said Kriger, Vituity’s Director of Transformation and Business Operations. “We need to talk to real people from diverse backgrounds, geographies, cultures, and clinical care settings and build companies from passion and personal experience. That will ultimately create the healthcare that we all want.”
Often, this means bringing care directly to the patient, especially in the COVID era, when patients may be wary of coming to hospitals.
“There are many sick people in this country that aren’t coming to the hospital or asking anyone for help, so taking care of people at home, or in their grandparents’ house, or at an SNF, or anywhere they are and reaching out to them has become incredibly important,” explains Smith.
To get started, pick an area to focus on
Our healthcare system is a $6 trillion problem. We spend close to 18% of the GDP on healthcare every year and over $10,000 per capita—twice of what any other industrialized country spends.
Naturally, numerous technical solutions and innovations have emerged in this space. Because of how vast the market is, however, it can be difficult to figure out how to start.
This is where balance comes in. After thoroughly understanding your users, pick one area to focus on.
“If you try to solve all of the problems of healthcare in one swoop, it is going to be extremely difficult,” Smith emphasizes.
Smith underscores the importance of iteration and building feedback cycles from diverse sets of users.
“With whatever you’re rolling out, you need to hear from patients and providers–and not just in one location. One location is a great place to start, but one of my recommendations is having a diverse set of pilots.”
Again, because of how local healthcare is, understanding the specific needs of markets you are targeting will help you build the best solutions.
At scale, however, Vituity firmly believes that all users and all markets should be serviced.
“We’re going to take care of everyone equally, always. And we want to build solutions and products that work for the entire community in this country.”
Recommendations for new healthcare solutions
Dr. Bobbie Kumar, Director of Clinical Innovation at Vituity, thinks a key area for innovation in the healthcare space is physician productivity.
When Dr. Kumar was an intern, she had 45 minutes to meet each patient. As a doctor, she only gets 10-15 minutes to do the same amount of work.
“Reducing the administrative burden that myself and the care team have to experience is going to be a very key and poignant feature in how solutions are able to penetrate the healthcare space,” she added.
Beyond that, she leaves two other recommendations for innovating solutions within the healthcare industry.
“Disrupt the industry, not the mission,” she said. “The top two reasons for choosing medicine are help people, followed by intellectual pursuit— wanting to find something that’s challenging enough for the knowledge base and the research.”
The last recommendation? “Preserve the humanism.” Technological solutions simply cannot account for the degree of human interaction inherent in physician-patient relationships.
“Until we really start looking at healthcare as both patient-centric and provider and care team supported, we’re just going to end up missing the target. So, my hope for the future is that we disrupt the status quo and we model these solutions that not just promote, but really emphasize the value and the unique human experience.”
Cathy Polinsky, former CTO at Stitch Fix, chatted this week with Pear associate Harris, who leads our talent initiatives. This is a recap! Watch the full talk at pear.vc/speakers.
It starts as an obsession. You play with your first coding language, and you’re hooked. You keep learning new languages and building cool things with your new skills. You’re doing this in an exciting environment with enthusiastic mentors who support you.
Cathy Polinsky, former CTO at Stitch Fix, was lucky enough to grow up this way. In the 80’s, Cathy’s mother was a teacher, and Apple personal computers had arrived at school. Cathy’s mother thought the technology was interesting and bought one for their home (before they had a VCR!).
Cathay learned her first programming language, Logo, and went on to learn basic programming. Computer science was so new then that there wasn’t formal education for it in school, but growing up in Pittsburgh meant that Cathy was able to go to a summer camp at Carnegie Mellon.
“We did algorithms in the morning and more hands-on programming in the afternoon with robotics and maze solving problems, and I just really got hooked and knew I wanted to study it after high school,” said Cathy.
Sure enough, Cathy did just that, and went on to a thriving computer engineering career. In this fireside chat with Pear, she looks back at her career and highlights the building blocks she gained from each role to help future engineers make decisions about their own careers.
“A career is made in hindsight, not while you’re on that path. While you’re on it, it might not feel straight, but you can in retrospect see this arc of where you’ve come from. I’d say I have a little bit more of a clear arc than most, but I know many other people who have had different paths that have gotten there or to some other destination that they have been really excited about.”
Laying the groundwork as a software engineer scaling early Amazon
Like many young graduates in computer science today, Cathy’s first job out of school was as a software engineer at a fast-growing company — Amazon, in 1999, right before the dotcom crash.
“I thought I’d missed the interesting times at Amazon. I thought I’d missed the early stage startup. Little did I know, I was living the interesting times. It was a gritty time. I was there during the dotcom collapse and all my stock was underwater,” Cathy recalls.
Things were still early enough for Cathy to grow fast with the company (she had a door desk when she started!). Amazon was in the hundreds of engineers then, and everyone was brilliant, but the rapid pace meant that the environment was a bit chaotic. The code base was a mess for example, with little documentation.
“It was an amazing time where I learned how to be an engineer being in a company that was scaling so fast. I learned a lot about how to hire people earlier than any other job I would have gotten,” says Cathy.
At Amazon, Cathay had the opportunity to learn from the tech giants. She developed solid, rigorous ground for her career learning to ship things at scale and having to think through everything from interview process to database and schema design, to hardware constraints and automation and testing.
But in addition to engineering skills, Amazon helped Cathy to gain a deep appreciation for the growth mindset — a mindset that serves her even today.
“Jeff [Bezos] never wanted to be written in an article and have Amazon in the same sentence with any other early stage dotcom company. He only wanted to see himself with the giant companies that were out there. I’d say that I was much more of a voice of growth and opportunity as a leader at Stitch Fix in the sense of: ‘How can we invest more, and how can we grow more?’ and making sure that we were keeping our eyes always on the long-term.”
Hands-on, non-stop building at an early stage startup
Cathy soon got the startup itch and wanted to see what early startups were like, so she went and joined a 13-person startup in San Mateo.
At first, with only two years of work experience at a scaling company, the early startup environment felt quite different. Cathy was surprised to learn that there were no automation suites and other big tools she took for granted at Amazon.
“But, I wrote way more code there than any other place, and I got to wear more hats and I got to go to a pilot customer and be involved when we were doing discussions about name changes and logos,” says Cathy. “You got to interact with people that weren’t just tech and be much more involved in the company on a different scale .”
Cathy also experienced the pain of building great products that didn’t work out.
“The company never really got off the ground. We only had two pilot customers, couldn’t get sales. There was a recession going on. It was heartbreaking when we closed the door to feel like I put so much of my blood, sweat, and tears into building something that I was really proud of.”
It was valuable first-hand experience in understanding that a successful company was not just about building a great product, but also about building the right thing and checking in with the market for early feedback.
Moving into management and people skills at Yahoo and beyond
After the startup heartbreak, Cathy turned back to big company world, though she “wouldn’t recommend to anyone to overcompensate that strongly,” she laughs.
At Oracle, Cathy realized she missed the fast pace of earlier companies, and sought to move into management. A friend pointed her to a position opening up at Yahoo.
Cathy ended up being offered her choice between two roles there — an engineering management role and an engineering lead role. She decided to try management and never looked back, going on to lead engineering at Salesforce after Yahoo, and on to the C-suite at Stitch Fix.
One of the first lessons Cathy learned in her first management role at Yahoo was to stay out of the code. The engineering manager she inherited the role from said that she regretted being so hands-on and jumping in too quickly to fix bugs or help her team with the solution.
“I really took that to heart. If I’m jumping in to heroically save the day, I’m not actually working on the fundamental issues that are going to help the team be successful in the long run. That has really influenced how I spend my time and how I look at the role,” says Cathy.
That is, transitioning into a management role means focusing your attention more on the people issues rather than the tech issues.
“I’d say that I choke often — that I would have been better off being a psychology major than a computer science major,” Cathay laughs. “Dealing with people in some of these large organizations is much more complex, and not deterministic in any way. You never know if you’re doing it the right way or not. I think that I’ve spent more sleepless nights thinking about people issues than I have about technology issues.”
In all the companies Cathy has been in, it’s been key to treat every single tech production incident as a learning opportunity.
That’s because if you’re shipping software, it’s inevitable that you are going to break something eventually. So, the question software engineers should be thinking about isn’t “How do we avoid breaking things?” but rather, “How do you make sure you don’t have the same problem happen again, and how do you make sure that you learn from it and get better and have other people around you learn from it, so they don’t have the same mistake that you had?”
Cathay is a fan of blameless postmortems.
“We get in a room and we do a postmortem of what happened, but the only rule is you can’t point fingers at anyone. You don’t name any names. You’re not trying to get anyone in trouble. If you can really approach any problem with that open mindset and learning, then you will make sure that you uncover all the problems in the areas and you won’t have the same problems again.”
Cathy’s Career Advice
There’s no wrong answer to big tech vs. join a startup vs. start my own company.
Take the roles where you’re going to learn the most.
Follow your passions.
If you are interested in something that’s different than what you’re doing today, just tell people that. People will see you differently and think of you when opportunities arise when you tell people what you’re passionate about.
Don’t worry about where you’re going to be 10 years from now, but have an idea of what you want to do next.
If you don’t know what you want to do next, talk to a lot of people.
Cathy’s Advice On Hiring
Anytime you can, hire someone smarter than you.
A lot of people have a hard time doing that. They think, “Oh, they have more experience, or they’re smarter than I am, what am I needed for?” You will never ever fail if you were hiring people that are smarter than you and know more than you.
Extend outside your network and find people who are going to push you.
I have worked in a lot of companies that focus on hiring within your network and telling the great track record they have for internal referrals. As a woman engineer, I think that’s really dangerous. I think that you have only a specific network of people and if you continue to hire people in your network, you’re only going to see people who look exactly like you and you’re not going to push yourself and get diverse opinions around the table. You’d be better off really trying to extend outside your network and finding people who are going to push you and bring different experiences to the table than you have in your own. That’s something that we were really intentional about at Stitch Fix — making sure that we were reaching out into diverse networks and seeing people that were different than the people that we already had.
Follow the structure of what you set out to do — don’t rush.
One of the challenging hires was not someone who worked directly for me, but was one level down, and was a referral from someone in the organization. We did a rush job hiring and leaned on the referral, but really did not show up living the values that we had as a company. We started to see some things that didn’t show up the way that we would expect for someone of their level. When we did a debrief on what happened, we realized that we hadn’t done reference checks and we hadn’t really done a full check on: ‘Is this person a good fit to the values that we had?’ It was a pretty big miss that we hadn’t followed the structure of what we had set out to do and really caused a lot of friction across the team because of it.
It’s critical to understand what you need for the stage of your company.
In the early days, Amazon would rather hire someone that had a couple of amazing interviews and a couple of bad interviews than someone who was mediocre across the board. They wanted to see someone who really excelled in a specific area, even if it meant they had holes in other areas. I like that sense of playing to someone’s strengths, especially as a larger company, you can take more liberties in that way.
It’s harder in an early stage company… you have funding for three hires. You’re going to need to hire some real generalists who like to build things, who can also answer phones and do hiring and operations and the like. Thinking about those first hires as generalists who are interested in getting to wear a lot of different hats is important. It’s kind of fun for the people who do it, to get to build things from the early stage.
Then you have to think about how you scale it. Because at some point, those people are probably not going to be happy after you get to a team of 100 where they’re not the best at any of those things. Either they scale, and they still know everything and are this amazing person that can jump in anywhere and add value, or they get really dissatisfied that they can’t really play the same role that they had before.
As you’re scaling things out, you’re hiring more narrow generalists of, “Hey, we really need someone who understands AWS deployments, or we need someone who really understands this mobile technology stack,” or whatever it might be.
So, if you’re really thinking about building and scaling with the business, as the business scales, you have to think about what stage you’re in and know that what works before is not going to be the thing that’s going to be successful after you get to 50 or you get to 100.
Tactical Hiring Tips
Take home interview questions and pair-programming interview questions are a good way to see what people are going to do in their day to day. You don’t work by yourself — you work in a team and so seeing how people work with a team is good.
Have candidates interview with non-technical team members and solve a problem together. It’s important for technical people to be able to talk with nontechnical folks. At Stitch Fix, this practice has enabled a much higher EQ team.
Have inclusive language in your job description and list fewer requirements to be more welcoming to women. Avoiding bro-like or gendered language is of course the obvious thing to do, but what might be less obvious is that long requirements can rule out certain populations of people! Men will tend to apply anyway despite not meeting all requirements, and women will tend to filter themselves out because they don’t have nearly enough of the requirements on this list.
Sit in on every debrief. You don’t necessarily need to meet every candidate, but you should listen carefully to candidate discussions and guide your team. “There were times where someone would explain the interview and then have a strong assessment on whether we should hire the person or not. I would listen to their rationale, but not agree with the outcome based on their assessment, so we could talk about that and dig in. Sometimes there were some things that changed the way that they thought about the interview, for example, something like, “They weren’t very confident in their skills.” We would ask, “Why did you think that?” And it could just be a passive word choice that they used, and someone else points out, “They’re actually really confident over here — and is that really a job requirement that you need?”